
Чтобы еще быстрее рассказывать вам свежие новости мира больших данных, а также информировать о наших курсах, акциях, статьях и прочих интересных событиях, мы запустили Telegram-канал https://t.me/BigDataSchool_ru. Подписывайтесь и получайте самые интересную и полезную информацию о технологиях Big Data, Machine Learning, Data Science, узнавайте особенности разработки распределенных приложений и администрирования кластеров...

Поскольку наши курсы по Apache Spark предполагают практическое обучение с глубоким погружением в особенности разработки и настройки распределенных приложений, сегодня рассмотрим, как именно выполняются кластерные вычисления в рамках этого Big Data фреймворка. Читайте далее, из чего состоит архитектура Spark-приложения, как связаны SparkContext и SparkConf, а также зачем ограничивать размер драйвера...

Чтобы добавить в наши обновленные авторские курсы для дата-инженеров по Apache AirFlow еще больше интересного, сегодня продолжим разбирать полезные дополнения релиза 2.0 и поговорим, почему разделение фреймворка на пакеты делает его еще удобнее. Также рассмотрим практический пример создания общедоступного провайдера из локального Python-пакета с собственными операторами, хуками и прочими компонентами....
Ровно через неделю, в четверг 15 апреля, с 10:00 до 15:00 МСК наш партнер компания Arenadata, разработчик отечественных решений для обработки и хранения больших данных, проводит первую клиентскую конференцию Big Data Universe #1. С докладами выступят ТОП-менеджеры и технические специалисты самой Arenadata, которые расскажут об особенностях практического применения платформы и...
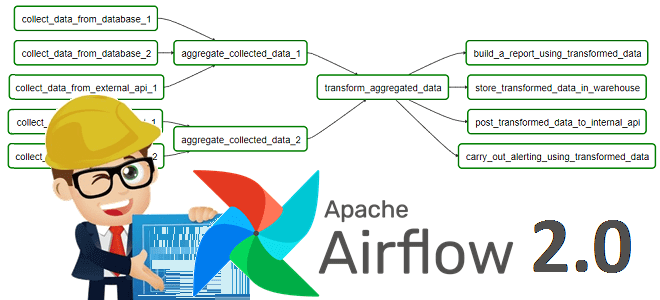
В поддержку наших полностью обновленных авторских курсов для инженеров данных по Apache AirFlow, сегодня рассмотрим новые способы определения DAG, которые были добавлены в релизе 2.0. Читайте далее, что под капотом TaskFlow API, как поместить задачи в TaskGroup, чем dag_policy отличается от task_policy и почему все это упрощает работу инженера Big...

Продолжая вчерашний разговор про потоковую аналитику больших данных на Apache Kafka и Pinot, сегодня рассмотрим особенности интеграции этих систем. Читайте далее, как входные данные Kafka разделяются, реплицируются и индексируются в Pinot, каким образом выполняется обработка данных через распределенные SQL-запросы. Также разберем, почему управление памятью серверов Pinot, потребляющих данные из Kafka,...

В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене...
Вчера мы упоминали, как долгожданный KIP-500, реализованный в марте 2021 года, позволяет не только отказаться от Zookeeper в кластере Apache Kafka, но и снимает ограничение числа разделов, чтобы масштабировать брокеры практически до бесконечности. Однако, не все так просто: читайте далее, какие важные функции еще не поддерживаются в этом экспериментальном режиме...
Сегодня рассмотрим важную практическую задачу из курсов Kafka для разработчиков и администраторов кластера – разделение топиков по брокерам. Читайте далее, как пропускная способность всей Big Data системы зависит от числа разделов, коэффициента репликации и ответного ack-параметра, а также при чем здесь KIP-500, позволяющий отказаться от Zookeeper. Что такое партиционирование в...

В поддержку курса Hadoop для инженеров данных сегодня разберем, в чем проблема безопасной отправки заданий и файлов в облачное хранилище Amazon S3 и как ее решить. Читайте далее, почему AWS S3 не дает гарантий согласованности как HDFS, из-за чего S3Guard не обеспечивает транзакционность и как настроить коммиттеры S3A для Spark...