 1105
1105 
Содержание
Продолжая вчерашний разговор про потоковую аналитику больших данных на Apache Kafka и Pinot, сегодня рассмотрим особенности интеграции этих систем. Читайте далее, как входные данные Kafka разделяются, реплицируются и индексируются в Pinot, каким образом выполняется обработка данных через распределенные SQL-запросы. Также разберем, почему управление памятью серверов Pinot, потребляющих данные из Kafka, влияет на общую производительность всей Big Data системы.
Как устроен Apache Pinot: краткий обзор архитектуры и принципов работы
Прежде чем говорить об интеграции Apache Kafka и Pinot, рассмотрим, как устроено это быстрое OLAP-хранилище больших данных. Вчера мы уже упоминали, что на фундаментальном уровне оно немного похоже на Apache Druid и яндексовский ClickHouse, а также основанную на нем Arenadata QuickMarts. Все эти аналитические хранилища выполняют обработку запросов на одних и тех же узлах, уходя от разрозненной архитектуры BigQuery, а также выполняют запросы быстрее, чем Big Data инструменты класса SQL-on-Hadoop: Hive, Impala, Presto и Spark, даже при обработке данных в колоночном формате, таких как Parquet или Kudu. Такая оперативность достигается за счет собственного формата хранения индексированных данных, интегрированного с движками обработки запросов.
Кроме того, данные в Apache Pinot, Druid и ClickHouse c Arenadata QuickMarts статично распределены между узлами, поэтому при быстром выполнении локальных данных не поддерживаются запросы с межузловыми перемещениями, такие как join-соединение между двумя большими таблицами. Также отсутствуют точечные обновления и удаления за счет эффективного колоночного сжатия и разнообразных индексов.
Таблица Pinot состоит из набора сегментов, распределенных по серверам. Сегмент – это единица разделения, репликации и обработки запросов, которая включает в себя метаданные таблицы, сжатые колоночные данные и индексы. Сегменты хранятся в файловой системе, например, Hadoop HDFS и для вычислений могут быть загружены на узлы обработки запросов. Сегменты данных не привязаны жестко к конкретным узлам кластера: за присвоение сегментов узлам, их и перемещение между узлами и репликацию отвечает контроллер – специальный выделенный сервер. Брокеры Pinot используют информацию с контроллера, чтобы рассылать запросы на отдельные серверы и собирать их вместе. Метаданные сегментов хранятся в Apache ZooKeeper, обращение к которому выполняется с использованием фреймворка Helix. Узлы обработки запросов загружают сегменты и обслуживают запросы к хранящимся в них данным, но не занимаются накоплением новых данных и производством новых сегментов.
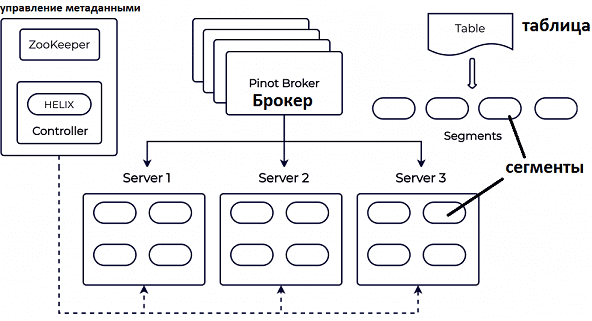
Ключевое отличие Pinot от Druid – это реализация управления сегментами: Druid реализует всю логику самостоятельно, используя Curator для взаимодействия с ZooKeeper, а Pinot полагается на фреймворк Helix. За счет отсутствия сегментации управление данными в ClickHouse c Arenadata QuickMarts проще, чем в Druid и Pinot, но последние выигрывают с точки зрения оптимизации инфраструктурной стоимости больших кластеров, и лучше подходят для облачных окружений [1]. О прочих сходствах и отличиях Apache Pinot, Druid и ClickHouse с Arenadata QuickMarts мы поговорим в другой раз. А пока рассмотрим, как данные из Kafka представляются в Pinot для аналитики в реальном времени.
Из Kafka в Pinot: потоковая аналитика больших данных
Конвейер интеграции Kafka с Pinot выглядит следующим образом [2]:
- сперва данные записываются в топиках Kafka;
- затем Pinot считывает сообщения из топиков Kafka и создает соответствующие сегменты данных, делая их доступными для SQL-запросов в реальном времени. Если данные секционируются в Kafka по каким-либо ключам измерений, информация об этом разбиении учитывается при создании сегментов в Pinot.
- при выполнении запроса с предикатом на конкретном измерении, брокер-узел Pinot фильтрует сегменты так, чтобы затронуть как можно меньше сегментов и узлов обработки запросов. Эта концепция называется «predicate pushdown» и важна для поддержания высокой производительности в некоторых приложениях.
При создании таблицы в Pinot следует указать два элемента:
- схема, которая определяет столбцы размеров и показателей, а также обозначает один из столбцов как столбец времени. Как правило, основой для этого является исходная схема Kafka.
- конфигурация таблицы, которая указывает ее свойства – репликация, хранение, квоты, параметры индексации, а также источник данных и, в случае Kafka, начальное смещение, с которого начинается потребление данных.
Пример кода по созданию таблицы в Pinot, куда в реальном времени принимаются данные из Kafka, выглядит так:
«REALTIME»: {
«tableName»: «pinotTable»,
«tableType»: «REALTIME»,
«segmentsConfig»: {
«schemaName»: «pinotTable»,
}
},
«tableIndexConfig»: {
«streamConfigs»: {
«streamType»: «kafka»,
«stream.kafka.consumer.type»: «lowlevel»,
«stream.kafka.topic.name»: «<topic-name>»,
«stream.kafka.broker.list»: «<broker-list>»,
}
},
}
Создание схемы и конфигурации таблицы уведомляет контроллер Pinot о начале приема данных для этой таблицы, который из Kafka обнаруживает разделы и определяет начальное смещение, по умолчанию установленное на последнее сообщение в каждом разделе.
Сегменты Pinot, которые хранятся в памяти называются «изменяемые» (mutable) и находятся в состоянии потребления (CONSUMING). Каждый изменяемый сегмент упорядочивает входящие данные в колоночном формате и обновляет необходимые индексы в реальном времени. Изменяемые сегменты доступны для SQL-запросов сразу после создания. Таким образом, актуальность данных у Pinot совпадает со свежестью данных Kafka при очень низких накладных расходах на прием сообщений.
При сохранении изменяемых сегментов из памяти их на диск они становятся неизменяемыми (immutable). Согласованность данных между репликами на разных узлах и конечным смещением Kafka при этом обеспечивается с помощью протокола контроллера Pinot. Для отдельного раздела Kafka, когда текущий изменяемый сегмент полностью сохраняется, т.е. становится неизменяемым, контроллер Pinot создает следующий изменяемый сегмент и назначает его некоторому набору серверов Pinot. Начальное смещение нового изменяемого сегмента на единицу больше конечного смещения последнего зафиксированного сегмента.
Обработка аналитических запросов выполняется брокером Pinot, который представляет собой stateless-сервер следующим образом [2]:
- клиентское приложение обращается к любому из развернутых в кластере Pinot брокеров;
- при получении запроса брокер определяет, какие сегменты (изменяемые и неизменяемые) необходимы для получения результата;
- брокер ищет информацию о местоположении сегмента через Helix и рассылает запрос на соответствующие серверы;
- каждый сервер локально выполняет полученный запрос, обрабатывая данные из своих локальных сегментов и отправляя промежуточный ответ брокеру;
- получив результаты с разных серверов, брокер объединяет их и отправляет окончательный ответ клиенту.
«Под капотом» этого несложного на первый взгляд алгоритма спрятаны особенности, которые позволяют ускорить выполнение запросов за счет сокращения пересылаемых данных. По умолчанию брокер Pinot выбирает все доступные сегменты для обработки запроса, а отдельные серверы сокращают сегменты по критериям фильтрации запросов. Большой диапазон запросов увеличивает вероятность попадания в «медленный сервер» и, следовательно, влияет на общую задержку. Предупредить это можно, обрезав сегменты на уровне брокера, т.е. предварительно разбить их на разделы. Также можно заранее разделить данные Kafka с ksqlDB, применив «PARTITION BY» к столбцу, часто используемому в условии WHERE. Затем следует указать Pinot, что входные данные уже разделены по этому столбцу, используя поле segmentPartitionConfig внутри конфигурации таблицы Pinot. На основе этих данных брокер Pinot сократит список сегментов, которые необходимо запросить.
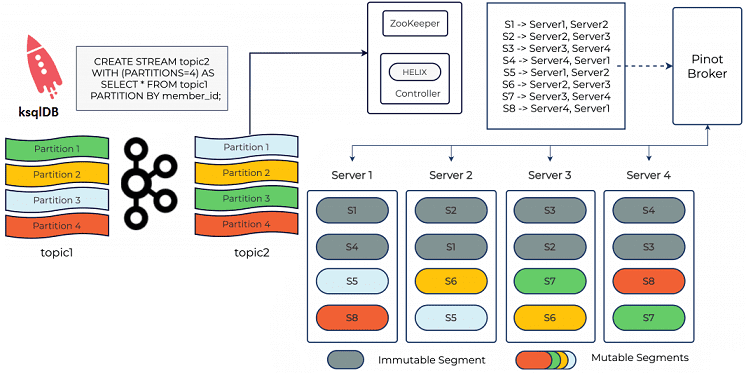
Например, данные из топика Kafka topic1 повторно разделяются на topic2 на основе выбранного столбца member_id. Таким образом, SQL-запрос обработки данных из таблицы Pinot, куда поступают данные из топика Kafka topic2, выглядит следующим образом [2]:
select count(*) from pinot_table
where member_id = 123
Если все записи с member_id=123 принадлежат разделу 1 топику Kafka topic2, то брокеру Pinot потребуется только запросить сегмент S1, что позволит выполнить запрос очень быстро.
Как выполнять SQL-запрос еще быстрее: управление памятью в сегментированных таблицах и общая latency всей Big Data системы
Наконец, отметим, как управление памятью в сегментированных таблицах Pinot влияет на общую задержку потоковой аналитики больших данных во всей Big Data системе на базе Apache Kafka.
Изначально в Pinot изменяемый сегмент полностью управлялся в динамической памяти, упрощая реализацию таких структур данных, как словари, прямые и инвертированные индексы за счет к большого потребления памяти на хостах. Это увеличивало вероятность возникновения проблем со сборкой мусора (Garbage Collection), предупредить которые можно через следующие подходы [2]:
- память вне кучи (Off-heap memory), доступная для большинства структур данных, кроме инвертированного индекса;
- перенос неизменяемых сегментов, которые используют меньше резидентной памяти, чем изменяемые сегменты. Pinot позволяет перемещать неизменяемые сегменты на хосты, которые не потребляют данные от Kafka, чтобы обеспечить точное выделение ресурсов на них и снизить общую стоимость кластера.
Также Pinot может использовать Kafka для координации между репликами. Два разных формата сегментов позволяют немедленно запрашивать данные, но имеют компактное и эффективное представление на диске. А управление памятью вне кучи в изменяемом сегменте Pinot делает таблицы реального времени более эффективными и повышает стабильность кластера.
Узнайте больше об администрировании кластеров Apache Kafka, а также использования этой event-streaming платформы для интеграции информационных систем и разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://habr.com/ru/company/oleg-bunin/blog/351308/
- https://www.confluent.io/blog/real-time-analytics-with-kafka-and-pinot/

