
В этой статье для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных разберем пример перевода сервиса Strava с кластера Cassandra в облачное хранилище AWS S3 и какую роль в этом сыграл вычислительный движок Apache Spark. Постановка задачи: слишком дорогая Cassandra Strava – это глобальный сервис отслеживания активности велосипедистов, бегунов...
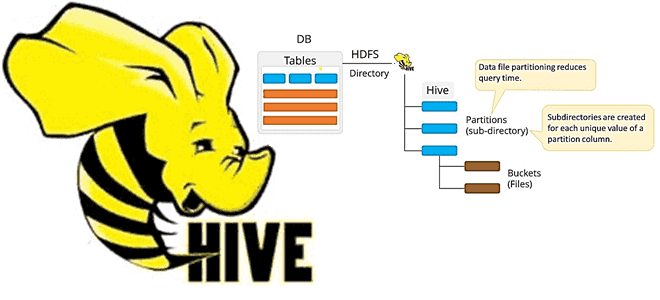
Что такое MSCK REPAIR TABLE в Apache Hive, зачем нужна эта команда, ее достоинства и недостатки, а также альтернативные варианты для задач пакетной дата-инженерии. Разбираем на примере конвейера обработки данных в ML-приложениях при работе с Data Lake. Команда MSCK REPAIR TABLE в Apache Hive В ML-приложениях особенно важно, как озеро данных (Data...

В этой статье для дата-инженеров и администраторов SQL-on-Hadoop рассмотрим, что такое Cloudera Data Platform Operational Database, как это связано с Apache HBase и Phoenix. Также разберем, каким образом перенести данные из кластера HBase в Cloudera Operational Database, избежав их потери и других подводных камней. Что такое Cloudera Operational Database: назначение...

Что такое Hive Transform, зачем это нужно дата-инженеру и разработчику распределенных приложений, где и как использовать эту функцию популярного средства SQL-on-Hadoop. Краткий обзор альтернативного способа операций с данными в Apache Hive, его возможности и ограничения, а также связь с HiveQL. Преобразования в Apache Hive Apache Hive – это популярная экосистема...

Чтобы самостоятельное обучение по Impala стало еще интереснее, сегодня мы предлагаем вам простой комплексный тест по основам работы с различными функциями в этой распределенной СУБД, включая особенности их применения. Комплексный тест по основам работы с функциями в Impala для новичков Для тех, кто начинает самостоятельное обучение по Apache Impala, мы...

В прошлый раз мы говорили про метаданные в Apache Impala. Сегодня поговорим про функции командной строки в Impala. Читайте далее про особенности работы функций командной строки Impala, благодаря которым становится возможным процесс оптимизации обработки Big Data массивов. Как работают функции командной строки в Impala: особенности оптимизации обработки Big Data Командная...

Сегодня в рамках обучения дата-аналитиков и разработчиков распределенных приложений, рассмотрим, что такое пользовательские функции в Apache Hive, как их создать и использовать. А также в чем проблема вызова UDF-функции, зарегистрированной в Hive, из Impala и при чем здесь Sentry. Простые и сложные UDF в Apache Hive Пользовательские функции в Hive...

В прошлый раз мы говорили про DML-операции в Hive. Сегодня поговорим про DDL-операции в этой распределённой Big Data платформе. Также рассмотрим применение этих операций к объектам, хранящимся в этой СУБД. Читайте далее про особенности работы DDL-операции в Hive. DDL-операции в СУБД Apache Hive DDL-операции (Data Definition Language, Язык Определения Данных)...

В прошлый раз мы говорили про индексы в Hive. Сегодня поговорим про DML-операции в этой распределённой Big Data платформе. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про DML-операции в Hive и их особенности. DML-операции в СУБД Apache Hive DML-операции (Data Manipulation Language) -...

В прошлый раз мы говорили про особенности работы механизмов группировки и сортировки в распределенной среде Impala. Сегодня поговорим про метаданные таблиц в Impala и про то, как их извлекать и выводить на экран. Читайте далее про табличные метаданные в Impala, благодаря которым становится доступным и весьма удобным legacy-проектирование. Что из...