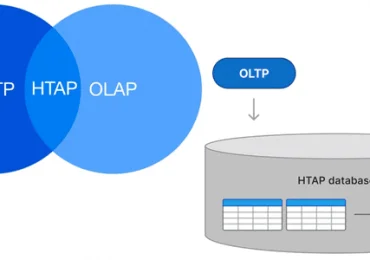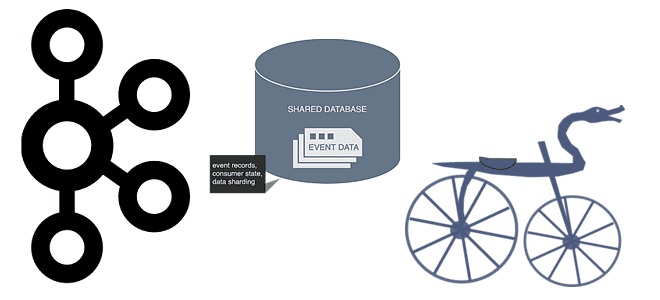
Однажды мы уже разбирали, способна ли Apache Kafka заменить собой базы данных в мире Big Data. Сегодня рассмотрим обратную постановку этой задачи: можно ли реализовать постоянный обмен сообщениями в стиле Kafka с помощью СУБД. Читайте далее, что общего у Kafka с базой данных, чем они отличаются и почему попытки заменить их друг другом – пустая трата времени и сил.
Почему Apache Kafka – это НЕ просто СУБД для потоков Big Data
Apache Kafka действительно имеет общие черты с любой СУБД, позволяя систематизировано хранить данные, обрабатываемые компьютеризованным способом, с поддержкой ACID с помощью механизмов гарантии доставки сообщений, репликации, средств конфигурирования топиков и настроек параметров очистки журналов. Однако, эта стриминговая платформа обработки событий не заменяет, а дополняет классические реляционные и NoSQL-СУБД [1]. Подробно об этом мы рассказывали здесь.
Но, поскольку Apache Kafka относится к технологиям Big Data, она применяется в гораздо меньшем количестве проектов, чем «обычная» база данных типа MySQL, MS SQL и пр. Поэтому по мере роста малого и среднего бизнеса может возникнуть соблазн построить свой велосипед с блэк-джеком и плюшками на основе уже привычного инструментария, самостоятельно организовав обмен сообщениями через СУБД вместо предназначенной для этого системы. Сначала эта идея может показаться вполне жизнеспособной, но ее реализация в итоге займет гораздо больше времени, чем внедрение Apache Kafka, а результаты оставят желать лучшего. Далее мы рассмотрим, почему.
Администрирование Arenadata Streaming Kafka
Код курса
ADS-KAFKA
Ближайшая дата курса
по запросу
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Сложности разработки
С функциональной точки зрения реализовать систему обмена сообщениями поверх СУБД осуществимо. Однако, база данных будет обеспечивать только самые примитивные требования к постоянству хранения и извлечения записей с поддержкой транзакций. В то время как Kafka предоставляет полноценные возможности потоковой передачи данных, включая распределение, а не только сохранение записей. В частности, Kafka позволяет легко разделять данные для распараллеливания обработки, сохраняя при этом порядок связанных записей и равномерное распределение нагрузки с помощью встроенного балансировщика.
Топик Kafka похож на таблицу базы данных, где сохраняются записи о событиях с индексированным атрибутом для обозначения их типа. Сегментация NoSQL и NewSQL СУБД обеспечивает масштабируемость, позволяя распределять разделы по узлам кластера. Периодический опрос базы данных от экземпляра потребителя обновляет его состояние при обработке записи. Непрерывный запрос на стороне потребителя минимизирует накладные расходы на ресурсы. При этом стоит помнить о положениях CAP-теоремы в распределенных системах: модель должна позволять нескольким производителям и потребителям работать одновременно, иначе будет нарушена масштабируемость. А без поддержки одновременных потребителей необходимо обеспечить активно-пассивное переключение при отказе, чтобы не пострадала доступность.
При разработке системы обмена сообщениями на базе СУБД придется самостоятельно определять механизм отслеживания состояния потребителей и работы с их непересекающимися группами, например, через дублирование записей в точке вставки и удаления записей после потребления. Можно даже использовать другую базу данных для отслеживания смещений или дисковый кэш в памяти, как Redis, Hazelcast или Apache Ignite. Это делает ввод-вывод данных дешевле за счет сложности. А в Apache Kafka такие задачи отлично решаются за счет архитектуры с помощью смещений (offset) и consumers group [2].
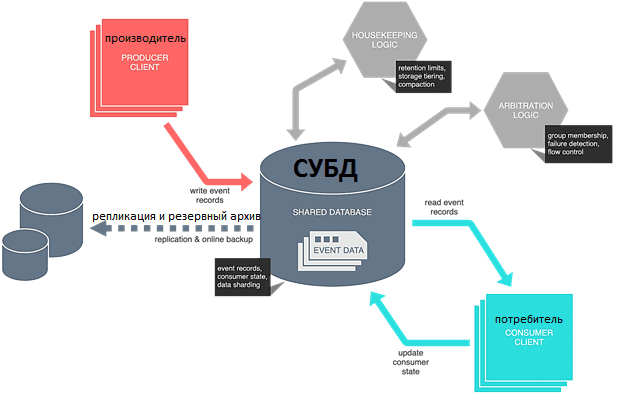
Поддержка и развитие
Сегодня хранение данных стоит достаточно дешево, но оно все же бесплатно, как и операции ввода-вывода, особенно в случае очень больших индексов B-дерева, которые со временем растут и фрагментируются. Самостоятельно реализовать базовую очистку на основе метки времени технически несложно, например, в выделенном процессе задания CRON. Также можно разместить сборщик мусора в процессах производителя или потребителя, что уже требует определения логики координации и не обеспечивает повторное использования в многоязычной экосистеме. Создание многоуровневого хранилища еще более трудоемко. Наконец, потребуется сжатие — удаление записей, которые были заменены недавними событиями, чтобы сократить обработку на стороне потребителя. В Apache Kafka такие сложные и ресурсоемкие запросы по умолчанию сочетаются с удобством обслуживания и производительностью.
Кроме того, Kafka предлагает детальный контроль за потребителями, продюсерами и администраторами системы за счет гибкого задания типов разрешенных операций (чтение, запись, создание удаление изменение) и ресурсов к их применению (топик, группы потребителей, конфигурации). В локальной системе, где два процесса взаимодействуют через СУБД, безопасность может быть упущена, т.к. в большинстве баз данных контроль доступа ограничен уровнем таблицы. А если в таблице размещены логически отдельные наборы записей, придется дополнительно разбивать их по таблицам и назначать детальные разрешения [2].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
25 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Потоковая аналитика больших данных: только Kafka, только хардкор
Наконец, выбирая вариант решения для какой-то задачи, стоит рассматривать его не только в текущем моменте, но и с точки зрения будущих перспектив. Kafka оптимизирована для высокой пропускной способности с обеих сторон:
- со стороны продюсера, разрешая публикацию множества записей в единицу времени;
- со стороны потребителя, позволяя обрабатывать большое количество записей параллельно.
СУБД не предназначена для такого варианта использования, тогда как Kafka может без проблем обрабатывать перемещение миллионов записей в секунду на локальном или облачном кластере с максимальной задержкой до 100 миллисекунд. Достижение аналогичных показателей пропускной способности и задержки в базе данных, вероятно, потребует комбинации специализированного оборудования и ювелирных настроек, а в реальности может быть практически недостижимо. Такая производительность Apache Kafka достигается за счет ее архитектурных особенностей, таких как [2]:
- отсутствие случайного ввода-вывода в журнале;
- пакетное чтение и запись;
- пакетное сжатие;
- незафиксированная буферизованная запись (без fsync) с нулевым копированием (ввод-вывод, который задействует ЦП и сводит к минимуму переключение режимов);
- обход сборки мусора.
И наоборот, Kafka не предлагает эффективных способов поиска и извлечения записей на основе их содержимого — то, что достаточно эффективно делают базы данных. Кроме того, в отличие от традиционных брокеров сообщений, таких как RabbitMQ, которые удаляют сообщения в точке потребления, Kafka не очищает записи после их использования. Вместо этого платформа независимо отслеживает смещения для каждой группы потребителей, рекурсивно публикуя специальный offset записи по внутреннему топику. Потребители в Kafka не изменяют лог-файлы, а потому множество потребителей могут одновременно читать данные из одного топика, не перегружая кластер. Добавление нового потребителя связано с некоторыми затратами, но в основном это последовательное чтение с низкой скоростью последовательной записи. Поэтому один топик Kafka может использоваться в разнообразной потребительской экосистеме [2].
Таким образом, готовая платформа потоковой передачи событий, такая как Apache Kafka предоставляет ключевые результаты труда множества талантливых дата-инженеров, предоставляя пользователю огромное количество важных функций вместо со стабильностью, производительностью и поддержкой. Поэтому самостоятельные попытки эмулировать event-streaming платформу или масштабную систему обмена сообщениями на базе типовой СУБД бесполезны и бессмысленны. В заключение еще раз подчеркнем, что Kafka не заменяет базы данных, а дает совершенно другой масштаб и характер обработки данных [1]. СУБД ориентированы на хранение информации для организации эффективного поиска и не стоит применять их как распределенную систему обработки событий в реальном времени.
Код курса
NOSQL
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Освоить тонкости работы с NoSQL-СУБД, а также узнать особенности администрирования кластеров Apache Kafka и разработки распределенных приложений потоковой аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://www.kai-waehner.de/blog/2020/03/12/can-apache-kafka-replace-database-acid-storage-transactions-sql-nosql-data-lake/
- https://towardsdatascience.com/you-can-replace-kafka-with-a-database-39e13b610b63