Сегодня в области Data Science именно машинное обучение является такой одновременно научной и прикладной сферой, где постоянно возникают новые прорывные идеи и технологии их реализации. Одной из самых популярных ML-тем сегодня считается федеративное машинное обучение. Что это такое и при чем здесь хайповый MLOps, читайте далее.
Что такое федеративное машинное обучение
Впервые идеи федеративного Machine Learning были представлены Google в 2017 году для улучшения прогнозирования текста на мобильной клавиатуре с использованием моделей машинного обучения, обученных на основе данных с нескольких устройств. Это не требует загрузки личных данных на центральный сервер для обучения моделей, что стало прорывом в традиционном ML для решения проблем c конфиденциальностью данных.
Федеративное обучение также называют совместным, поскольку ML-модели обучаются на нескольких децентрализованных периферийных устройствах или серверах, содержащих локальные выборки данных, без обмена ими. Этот подход отличается от традиционных централизованных ML-методов, когда все локальные наборы данных загружаются на один сервер, а также от более классических децентрализованных подходов с одинаковом распределением локальных данных. Сегодня федеративное обучение активно применяется в оборонной промышленности, телекоммуникациях, фармацевтике и платформах Интернета вещей.
Первоначально федеративное обучение использовалось Google для решения проблем взаимодействия между компаниями и клиентами, но позже Federated Machine Learning стало активно использоваться и другими компаниями, устраняя конфликты между проблемами конфиденциальности данных и потребностями в их совместном использовании. ML-модели отправляются в данные, а не наоборот, что устраняет сбор и передачу данных на центральный сервер, которые представляют собой угрозу безопасности. Соображения конфиденциальности и правила предотвращают и ограничивают перемещение данных, поэтому защита конфиденциальности пользователей обеспечивается за счет обучения моделей источникам данных, а не передачи необработанных данных на централизованный сервер.
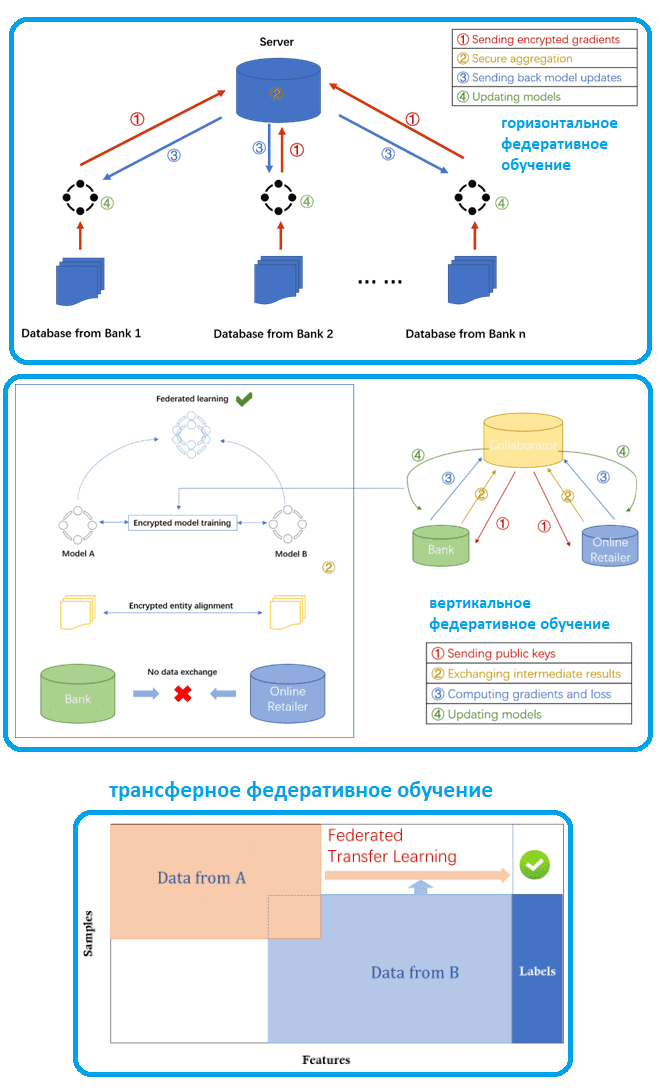
С точки зрения фич и распределения идентификаторов образцов датасетов федеративное ML делят на горизонтальное, вертикальное и трансферное обучение, а также межсистемное обучение, модельно-ориентированное, ориентированное на данные и пр. Например, с горизонтальными данными доступные наборы данных имеют согласованный набор фич, но различаются выборками. Например, банки в Москве и в Тюмени предлагают аналогичные финансовые онлайн-услуги, но имеют совершенно разные группы пользователей из-за разницы в местоположении. Характеристики данных почти идентичны, а пересечение пользовательских датасетов небольшое. В этом случае каждый банк обучает свои ML-модели локально и отправляет зашифрованные результаты на сервер для обучения универсальной модели Machine Learning. Оба банки получат новую ML-модель после того, как сервер агрегирует результаты.
Вертикальное федеративное обучение позволяет крупным компаниям существенно расширить и обогатить клиентский опыт через сотрудничество с фирмами из других доменов, чтобы предлагать своим пользователям более персонализированные услуги без ущерба для конфиденциальности. Вертикальное федеративное обучение применимо к случаям, когда наборы данных взяты из одних и тех же образцов, но имеют очень разные характеристики. Например, банк сотрудничает с интернет-магазином, чтобы создать модель прогнозирования покупок финансовых продуктов. Банк регистрирует доходы, расходы и кредитную историю клиентов, в а ecommerce-партнер имеет историю просмотров и покупок клиентов, включая их конфиденциальные личные данные. В этом случае применяется вертикальное федеративное обучение для объединения различных фич, вычисления потерь и градиентов при обучении с сохранением конфиденциальности. Зашифрованные идентификаторы пользователей выравниваются, чтобы подтвердить пересечение клиентов из банка и интернет-магазина. При этом компании-партнеры не взаимодействуют друг с другом напрямую: вместо этого они отправляют друг другу маскированные результаты обучения ML-моделей, возвращая расшифрованные градиенты и потери вычислительных алгоритмов после обучения общей глобальной модели.
Трансферное обучение подходит для компаний, у которых почти нет пересекающихся клиентов, т.к. они работают в разных доменах и регионах. Федеративное трансферное ML заполняет недостающие метки из предварительно обученной модели, чтобы расширить масштаб доступных данных и, по сути, представляет собой комбинацию вертикального и горизонтального обучения. Например, федеративное трансферное обучение оптимизирует модель прогнозирования на стороне целевого домена B, используя знания стороны исходного домена A, изучая общее представление фич между A и B.
В федеративном Machine Learning модели обучаются на нескольких локальных датасетах на локальных узлах без явного обмена данными, но с периодическим обменом параметрами, например, весами и смещениями глубокой нейросети между локальными узлами для создания общей глобальной модели. В отличие от распределенного обучение, изначально направленного на распараллеливание вычислений, федеративное нацелено на обучение разнородным наборам данных. В федеративном ML наборы данных обычно сильно неоднородны по размеру. А клиенты, т.е. конечные устройства, где обучаются локальные модели, могут быть ненадежными и больше подвержены сбоям, чем в системах распределенного обучения, где узлами являются центры обработки данных с мощными вычислительными возможностями. Поэтому, чтобы обеспечить распределенные вычисления и синхронизацию его результатов, федеративное ML требует частого обмена данными между узлами.
Несмотря на отмеченные достоинства, федеративное машинное обучение имеет ряд недостатков:
- неоднородность между различными локальными наборами данных — каждый узел имеет погрешность по отношению к генеральной совокупности, а размеры выборок могут значительно различаться;
- временная неоднородность — распределение каждого локального датасета меняется со временем;
- необходимо обеспечить совместимость набора данных на всех узлах;
- скрытие обучающих датасетов чревато риском внедрения уязвимостей в глобальную модель;
- отсутствие доступа к глобальным обучающим данным затрудняет выявление нежелательных предубеждений во входных данных для обучения;
- есть риск потери обновлений локальных ML-моделей из-за сбоев на отдельных узлах, что может повлиять на глобальную модель.
Сократить влияние этих проблем на результаты федеративного обучения помогают специализированные платформы, где в качестве инструментальных средств также применяются MLOps-решения, о которых мы поговорим далее.
MLOps-инструменты для Federated Machine Learning
Хотя ставить знак равенства между федеративным машинным обучением и MLOps не совсем корректно, не удивительно, что эти идеи становятся более эффективны в случае их совместного использования. Напомним, MLOps – это набор инженерных практик для эффективного и непрерывного процесса автоматизированной разработки, развертывания и сопровождения ML-систем, который объединяет идеи и инструментальные средства для комплексного и согласованного управления версиями вычислительных алгоритмов, данных, программного кода и инфраструктуры. Поскольку федеративное машинное обучение предполагает непрерывную синхронизацию локальных моделей, MLOps-концепция отлично подойдет для этих целей. Это используется в следующих популярных платформах для федеративного машинного обучения:
- FATE (Federated AI Technology Enabler) — проект с открытым исходным кодом для поддержки безопасной и федеративной ИИ-экосистемы. FATE доступен для автономных и кластерных развертываний. Эта платформа поддерживается WeBank, частным банком Китая. Помимо средств разработки конвейеров и дэшбордов, FATE также включает инфраструктуру распределенных систем для управления федеративными рабочими нагрузками с настройкой развертывания кластера docker-compose и Kubernetes.
- Substra — это программная платформа для федеративного обучения, разработанная в рамках французского медтех-стартапа Owkin, основанного в 2016 году. Сегодня Substra используется в проекте MELLODY по поиску лекарств в фармацевтической промышленности. Substra поддерживает множество интерфейсов для разных типов пользователей: библиотеки Python для Data Scientist’ов, CLI-интерфейсы для администраторов и GUI для бизнес-пользователей. С точки зрения развертывания Substra включает в себя сложную настройку Kubernetes для каждого узла. Substra использует доверенные среды выполнения (анклавы), которые позволяют выделять частные области для кода и данных. Для обеспечения отслеживаемости Substra записывает все операции на платформе в неизменяемый реестр, а для безопасности шифрует обновления модели, данные и сетевую связь.
- Python-библиотеки PySyft и PyGrid. PySyft определяет объекты, алгоритмы машинного обучения и абстракции. С PySyft нельзя работать над реальными проблемами, которые связаны с обменом данными по сети. Для этого нужна библиотека PyGrid, которая реализует федеративное обучение на мобильных и периферийных устройствах, а также различных типах терминалов. PyGrid — это API для масштабного управления и развертывания PySyft. PyGrid состоит из приложения на основе Flask для хранения личных данных и моделей федеративного обучения, эфемерного вычислительного инстанса, управляемого компонентами домена для выполнения вычислений с данными и еще одного Flask-приложения для мониторинга и управления различными компонентами домена.
- Open FL — проект Python 3 с открытым исходным кодом от Intel для реализации FL на конфиденциальных данных. OpenFL имеет сценарии развертывания в bash и использует сертификаты для защиты связи. Библиотека состоит из соавтора, который использует локальный набор данных для обучения глобальных моделей, и агрегатора, который получает обновления модели и объединяет их для создания глобальной модели. OpenFL поставляется с Python API и интерфейсом командной строки. Связь между узлами осуществляется с использованием mTLS, поэтому требуются сертификаты. Необходимо сертифицировать каждый узел в федерации. OpenFL поддерживает сжатие данных с потерями и без потерь для снижения затрат на связь, позволяя разработчикам настраивать логирование, методы разделения данных и логику агрегирования. Дизайн OpenFL основан на плане федеративного обучения – файле YAML, где определяются необходимые соавторы, агрегаторы, соединения, модели, данные и любая необходимая конфигурация. OpenFL работает в Docker-контейнерах для изоляции федеративных сред.
- TensorFlow Federated (TFF) — платформа с открытым исходным кодом для машинного обучения и других вычислений с децентрализованными данными. Фреймворк состоит из двух основных уровней API: уровня ядра (Core) и самого федеративного обучения. Core API представляет собой среду программирования для реализации распределенных вычислений. Каждое вычисление выполняет сложные задачи и обменивается данными по сети для координации и согласования, используя абстракцию псевдокода для выражения локального исполняемого файла программы в различных целевых средах выполнения (мобильные устройства, датчики, компьютеры, встроенные системы и пр.). Высокоуровневый API федеративного обучения поверх Core позволяет подключать существующие ML-модели к TFF без сильного углубления в детали технологии. В этот API входят модели (классы и вспомогательные функции), функции создания федеративных вычислений и готовые наборы данных для использования в различных сценариях моделирования. Разделение уровней между FL и FC предназначено для облегчения работы, выполняемой разными пользователями. Federated Learning API помогает разработчикам внедрять ML-модели FL в TensorFlow, а Data Scientist’ам — внедрять новые алгоритмы, тогда как Core API предназначен для системных исследователей. О другом фреймворке глубокого обучения на основе TensorFlow читайте в нашей новой статье.
- IBM Federated Learning предоставляет базовую структуру для федеративного обучения, куда можно добавлять расширенные фичи. Он не зависит от какой-либо конкретной ML-платформы и поддерживает различные топологии обучения, чтобы использовать множество моделей федеративного обучения и топологий в корпоративных и гибридных облачных средах. IBM Federated Learning поддерживает модели на Keras, PyTorch и TensorFlow, линейные классификаторы/регрессии (с регуляризатором), деревья решений ID3, алгоритмы глубокого обучения с подкреплением и наивные байесовские модели.
- NVIDIA CLARA — это платформа приложений для здравоохранения, которая включает полнофункциональные библиотеки с ускорением на GPU, пакеты SDK и справочные приложения для разработчиков, Data Scientist’ов и аналитиков для создания безопасных и масштабируемых федеративных обучающих решений в режиме реального времени. Например, CLARA применяется во французском стартапе Therapixel, который использует технологию NVIDIA для повышения точности диагностики рака молочной железы.
Читайте в нашей новой статье про еще одно перспективное направление в области инженерии данных и машинного обучения — ModelOps. А как применить лучшие практики MLOps в реальных проектах для эффективной аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://openzone.medium.com/a-brief-introduction-to-federated-learning-fl-series-part-1-b81c6ec15fb8
- https://wiki5.ru/wiki/Federated_learning
- https://www.apheris.com/blog-top7-open-source-frameworks-for-federated-learning
- https://www.tensorflow.org/federated