
Мы уже рассказывали про коннектор Greenplum-Spark, 2-я версия которого вышла в октябре 2020 года. А сегодня рассмотрим российскую альтернативу для отечественной MPP-СУБД Arenadata DB на базе Greenplum, выпущенную компанией Аренадата в июле 2021 года. Краткий обзор ADB-Spark Connector: архитектура, принципы работы, сценарии использования, а также отличия от PXF-фреймворка и варианта...

При том, что Apache Hadoop – высоконадежная экосистема хранения и аналитики больших данных, отказы случаются и в ней. Сегодня в рамках обучения начинающих администраторов и разработчиков Hadoop разберем, какие типы сбоев возможны в распределенной файловой системе HDFS и механизмы их предупреждения, а также рассмотрим процедуру вывода узлов из кластера для...

Продолжая разбирать тонкости сериализации данных в Apache Kafka на практических примерах, сегодня рассмотрим кейс индийской ИТ-компании Naukri Engineering о повторной обработке сообщений и особенностях форматов. Читайте далее, чем хороши заголовки Kafka и почему их не так просто использовать, а также зачем писать свой сериализатор с десериализатором для достижения 100%-ного SLA....

Вчера мы упоминали, что использование Spark или Tez в качестве движка исполнения SQL-запросов в Apache Hive вместо классического Hadoop MapReduce намного ускоряет аналитику больших данных. Сегодня рассмотрим подробнее, чем отличаются эти механизмы и какой из них выбирать в разных случаях использования. Что такое Apache Tez и как он работает с...

Apache Hive – востребованный инструмент класса SQL-on-Hadoop, который также активно используется в работе с фреймворком Spark. Поэтому сегодня разберем важную тему из обучения дата-инженеров и аналитиков больших данных про оптимизацию SQL-запросов в этом NoSQL-хранилище. Смотрите, чем полезна векторизация HiveQL-операций, какие форматы файлов обрабатываются быстрее, почему денормализация данных в Hive –...

Чтобы добавить в наши курсы по Spark еще больше практических кейсов, сегодня ответим на самые частые вопросы относительно масштабирования распределенных приложений, написанных с помощью этого фреймворка. Читайте далее о пользе динамического распределения, оптимальном выделении ресурсов на драйверы и исполнители, а также каковы тонкости управления разделами в Apache Spark. Лебедь, рак...
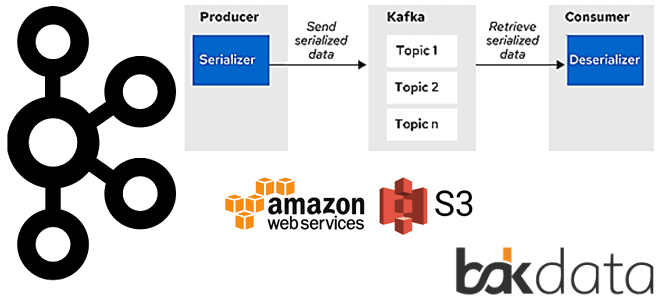
Сегодня рассмотрим проблему обработки больших сообщений в Apache Kafka Streams и способы ее решения с помощью средства сериализации и десериализации (SerDe) от немецкой ИТ-компании Bakdata. Узнайте, почему максимального лимита конфигурации max.message.bytes не хватает, зачем и как приложение Kafka Streams материализует данные, а также каким образом kafka-s3-backed-serde читает и записывает большие...

В недавней статье про оптимизацию SQL-запросов в Greenplum мы рассказывали про планы их выполнения и операторы просмотра этих планов. Сегодня разберем подробнее, какие операции с данными могут встретиться в отчете, сгенерированном командой EXPLAIN, а также рассмотрим, чем эта информация полезна дата-инженеру и аналитику данных. 5 операций в плане выполнения SQL-запросов...

Обучая разработчиков Big Data, сегодня рассмотрим, почему в распределенных приложениях Apache Spark случаются OOM-ошибки. Читайте далее, как работает сборка мусора JVM в Spark-приложениях, почему из-за нее случаются утечки памяти и что можно сделать на уровне драйвера и исполнителя для предупреждения OutOfMemoryError. Сборка мусора JVM и OOM-ошибки в Spark-приложениях На практике...
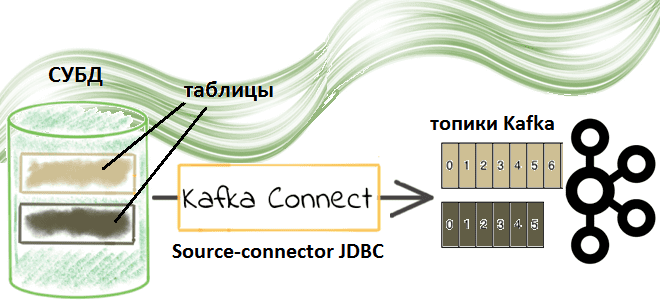
Недавно мы рассматривали пример потоковой передачи данных между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Сегодня заглянем под капот такой интеграции и разберем подробнее, что именно представляет собой JDBC-коннектор источника Kafka от Confluent. Компоненты Kafka Confluent для потоковой интеграции данных: коннекторы и реестр схем...