
В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data). Где хранить...

Мы уже рассказывали про профессиональный стандарт бизнес-аналитика – руководство BABOK и его значимость в области больших данных. Сегодня рассмотрим еще 3 подобных свода знаний, которые полезны для архитектора, разработчика, менеджера, инженера, исследователя и аналитика Big Data: PMBOK, SWEBOK и DMBOK. А также разберем, что такое EABOK и насколько это применимо...
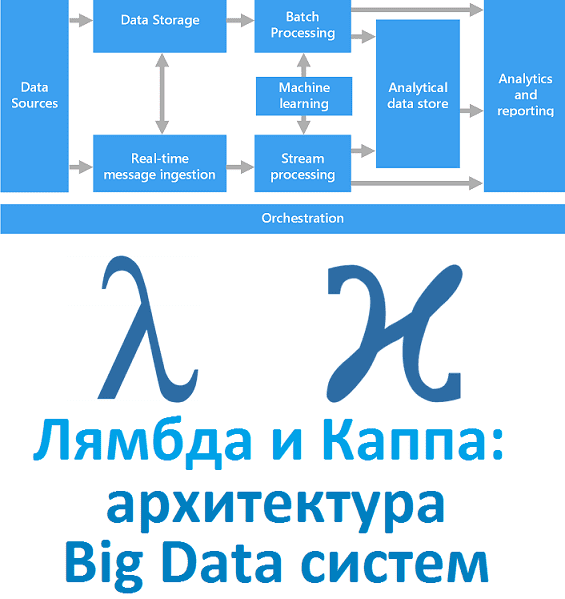
Вчера мы рассказали, что такое лямбда-архитектура. Сегодня рассмотрим Каппа - альтернативный подход к проектированию Big Data систем. Читайте в нашей статье, зачем нужна эта концепция, каковы ее достоинства и недостатки, чем Каппа отличается от Лямбда, где это используется на практике и при чем тут Apache Kafka с Machine Learning. Зачем...
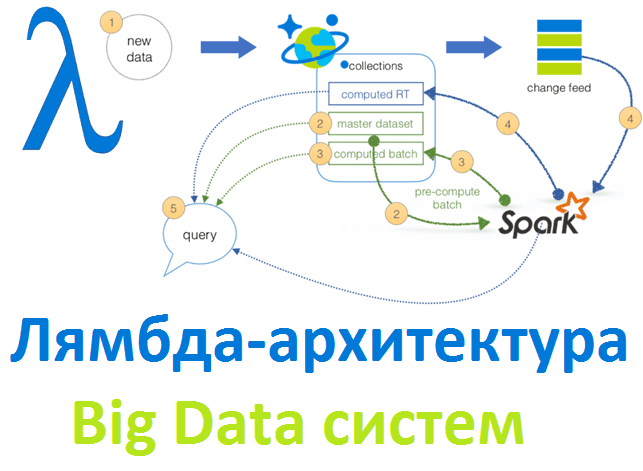
Рассматривая основы больших данных, сегодня мы расскажем лямбда-архитектуру, одну из двух главных подходов к построению Big Data систем. Читайте в нашей статье, зачем нужна эта концепция и как она работает, а также при чем тут машинное обучение, интернет вещей, Apache Spark и Hadoop. Что такое Лямбда-архитектура и зачем она нужна...
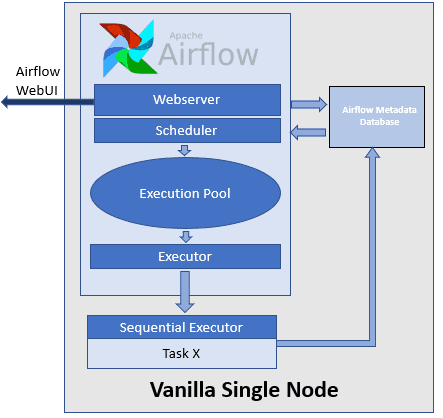
Недавно мы рассказывали про Airflow Kubernetes Executor, который позволяет выполнять задачи DAG-графа Эйрфлоу в среде Kubernetes, развертывая Docker-контейнер на отдельном пользовательском модуле (pod). Сегодня рассмотрим, какие еще есть исполнители задач в Apache Airflow, как они используются при автоматизации batch-процессов обработки больших данных и с какими проблемами можно столкнуться при их...
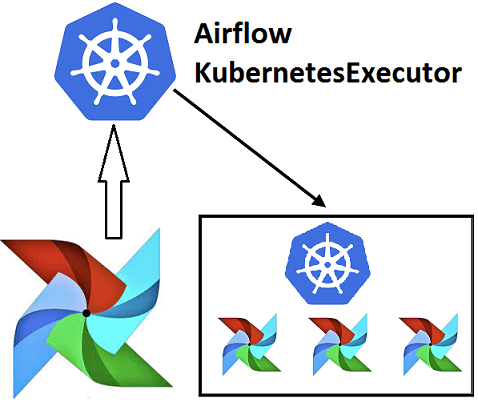
Эффективное обучение AirFlow, также как курсы по Spark, Hadoop, Kafka и другим технологиям больших данных (Big Data) также включают нюансы интеграции этого фреймворка с другими средами. Например, вчера мы рассматривали преимущества DevOps-подхода к разработке Data Flow на примере взаимосвязи Apache Airflow с Kubernetes посредством специальных операторов. Продолжая эту тему, сегодня...

Вчера мы рассказали, почему запускать Airflow на Kubernetes – это эффективно и выгодно для всех участников batch-процессов с большими данными (Big Data): разработчиков Data Flow, Data Scientist’ов, аналитиков и инженеров. Сегодня рассмотрим, что такое Airflow Kubernetes Operator и чем он отличается от подобной разработки компании Google. Как работает AirFlow Kubernetes...

Чтобы обучение Airflow было максимально приближенным к практике, сегодня мы поговорим про особенности реального внедрения этого фреймворка для разработки, планирования и мониторинга пакетных процессов обработки больших данных (Big Data) с учетом современного DevOps-подхода. Читайте в нашей статье, зачем вообще нужна связка Apache Эйрфлоу с Kubernetes и как это реализовать технически....

Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования. Чем хорош Apache AirFlow:...

Обычно курсы по Spark подробно рассказывают, чем хорош этот Big Data фреймворк для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных. Но, чтобы обучение Apache Spark было максимально полезным, стоит знать и о недостатках этого многофункционального инструмента обработки больших данных. Сегодня мы рассмотрим некоторые проблемы, которые возникают при практическом...