
Партиционирование таблиц – надежный способ повышения производительности Greenplum, который тесно связан с особенностями распределения данных по сегментам кластера. Читайте далее, чем опасно неравномерное распределение данных и вычислений по узлам, а также как найти дата-инженеру и устранить эти перекосы в MPP-СУБД, чтобы повысить скорость выполнения SQL-запросов и решить проблемы с нехваткой...
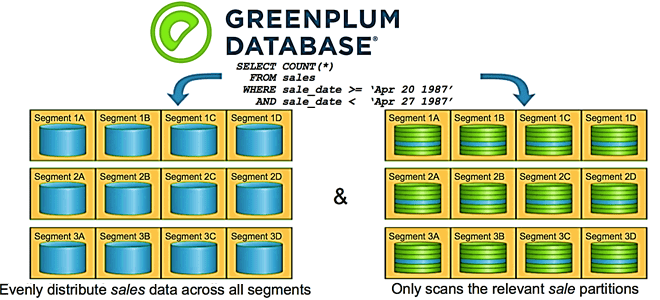
Мы уже рассказывали про основы хранения и аналитики больших данных в Greenplum, а также рассматривали особенности индексации и сжатия данных в этой MPP-СУБД. Продолжая разговор о нашем новом курсе «Greenplum для инженеров данных», сегодня разберем лучшие практики разбиения данных на разделы и пример их распределения по сегментам кластера. Кратко о...

В продолжение вчерашней статьи по нашему новому курсу «Greenplum для инженеров данных», сегодня рассмотрим особенности индексации и сжатия данных в этой MPP-СУБД. Читайте далее, почему в Greenplum можно обойтись без индексов, когда выбирать RLE-сжатие вместо zlib, зачем сжимать рабочие файлы при выполнении SQL-запросов и что такое селективность индекса. ТОП-10 советов по...

Продвигая наш новый курс «Greenplum для инженеров данных», сегодня мы рассмотрим особенности организации таблиц в этой MPP-СУБД, типы данных и оптимальное расположение столбцов. Читайте далее, чем heap storage отличается от append-optimized, когда выбирать колоночную, а когда – строковую модель хранения данных для таблицы, почему BIGINT с TIMESTAMP следует размещать перед...

Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
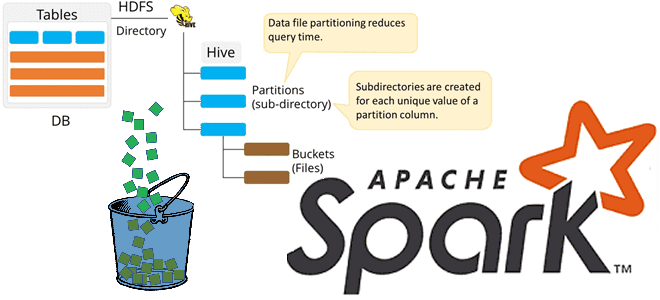
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к сервисам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать...

В этой статье продолжим говорить про обучение разработчиков Apache Spark и рассмотрим, какие сегменты памяти есть в этом Big Data фреймворке и как с ними работать наиболее эффективно. Читайте далее, почему процессы PySpark и SparkR потребляют внешнюю память, чем пользовательская память кучи JVM отличается от памяти хранилища и какие конфигурации...

Продолжая разговор про практическое обучение разработчиков Apache Spark, сегодня рассмотрим пример повышения скорости выполнения SQL-запросов к большому датафрейму. Читайте далее, как определить и исправить асимметрию распределения данных по разделам, зачем добавлять контрольные точки в длинные DAG и в чем здесь опасность, чем хороша широковещательная трансляция, для чего фильтровать данные перед...

На практике каждый аналитик Big Data и Data Scientist часто сталкивается с удалением дублирующихся значений в датасете. Поэтому, чтобы добавить в наши курсы по Apache Spark еще больше полезных примеров, сегодня рассмотрим 5 простых способов решения этой востребованной задачи. Читайте далее, чем distinct() отличается от dropDuplicates(), а reduceByKey() - от...