
Хотя наши практические курсы по Greenplum и Arenadata DB больше ориентированы на аналитиков и дата-инженеров, чем на администраторов, в программы обучения также включены важные сведения по настройке этих MPP-СУБД. В этой статье мы собрали лучшие практики системного конфигурирования кластера Greenplum, которые помогут повысить эффективность аналитики больших данных в этой Big...

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...
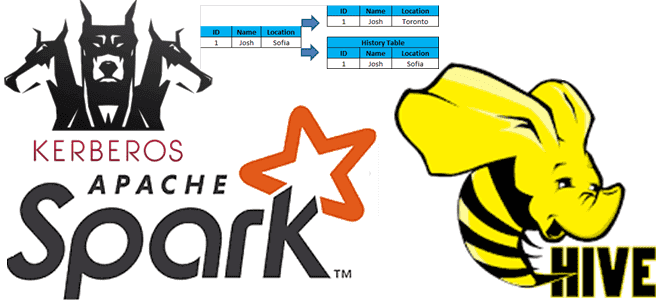
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...

Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне. Постановка задачи: бизнес-контекст и используемые технологии В...

В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...

Сегодня разберем кейс компании Renault по масштабированию своей цифровой платформы и снижению затрат с помощью BigQuery и Apache Spark на Google Dataproc. Цифровизация в автомобильной промышленности: конвейер сбора и аналитики больших данных с производства средствами Google сервисов и снижение затрат на облако в 2 раза через изменение конфигурации Spark SQL....

В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...
В рамках программы курсов по Greenplum и Arenadata DB, сегодня рассмотрим важную для разработчиков и администраторов тему об особенностях оптимизатора SQL-запросов GPORCA, который ускоряет аналитику больших данных лучше встроенного PostgreSQL-планировщика. Читайте далее, как выбирать ключ дистрибуции, почему для GPORCA важна унифицированная структура многоуровневой партиционированной таблицы и каким образом оптимизаторы обрабатывают...

Сегодня в рамках обучения дата-аналитиков и разработчиков Spark-приложений, рассмотрим еще несколько особенностей этого фреймворка. Почему count() работает по-разному для RDD и DataFrame, как отличается уровень хранения при применении метода cache() для этих структур, когда использовать SortWithinPartitions() вместо sort(), а также парочка тонкостей обработки Parquet-таблиц в Spark SQL и кэширование метаданных...

Сегодня рассмотрим, что такое Beekeeper и как этот сервис помогает администраторам Hadoop и пользователям Apache Hive очищать метаданные этого NoSQL-хранилища. Читайте далее, зачем удалять устаревшие пути из Metastore и как настроить конфигурацию Hive-таблиц для автоматического прослушивания событий их изменения. Для чего очищать потерянные метаданные в Apache Hive Напомним, Apache Hive...