
В одной из статей мы говорили о TaskFlow API, который позволяет задачам передавать и получить друг от друга информацию. За кулисами этого приема и передачи в Apache Airflow лежит XCom. Сегодня расскажем вам о том, как взаимодействуют задачи через XCom, а также, как задаются параметры конфигурации через особые переменные Apache...

В рамках обучения разработчиков Spark-приложений, аналитиков данных и дата-инженеров, сегодня рассмотрим, как улучшить и визуализировать понимание обработки данных в этом Big Data фреймворке. Читайте далее про API встроенных механизмов наблюдения за качеством данных в Apache Spark и открытые библиотеки профилирования на примере Deequ. 2 уровня абстракции мониторинга Spark-приложений для дата-инженера...

Добавляя в наши курсы для дата-инженеров по Apache Airflow полезные примеры, сегодня рассмотрим тонкости контроля доступа к DAG в этой платформе. Читайте далее, какие роли есть в Apache Airflow, каковы разрешения для них и как Flask AppBuilder осуществляет управление доступом к пользовательскому интерфейсу веб-сервера. Безопасность DAG’ов в Apache AirFlow: роли...

Когда имеются графы (dags), зависимые от других, то лучше всего объединить их в один или использовать TaskGroup, о котором говорили в прошлой статье. Но если по каким-то причинам сделать это не удается, то Apache Airflow предоставляет различные способы запуска графа внутри другого. Одним из таких является TriggerDagRunOperator. В этой статье...
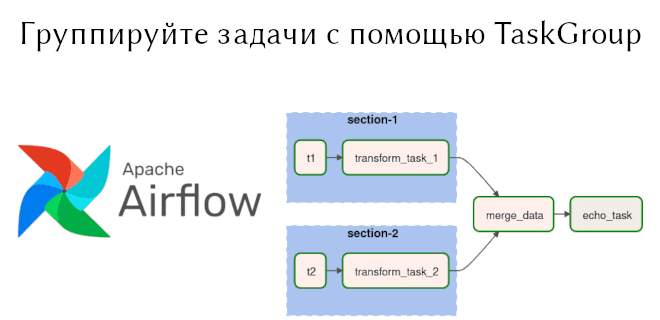
В предыдущей статье мы рассмотрели TaskFlow API, появившийся в Apache Airflow 2.0. Сегодня поговорим о способах задания операторов, отличных от PythonOperator, а также о способе группировки задач TaskGroup. Читайте далее: как сформировать BashOperator, используя TaskFlow API, когда следует использовать TaskGroup, в чем преимущества TaskGroup перед SubDag. Используем Bash Operator в...

В предыдущей статье мы говорили о том, как начать работать с Apache Airflow. Сегодня пойдет речь о новом инструменте, появившемся в Airflow 2, — TaskFlow API. Он обеспечивает кросс-коммуникацию между задачами с помощью обычных функций Python. На примере ETL-конвейера мы объясним, как соорудить DAG на основе TaskFlow API, а также...
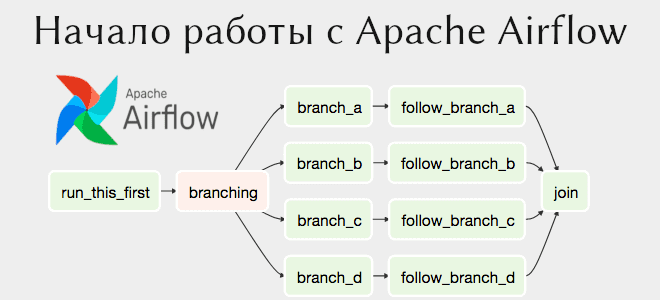
В прошлой статье мы рассмотрели установку Apache Airflow на свой компьютер. Данная платформа предназначена для планирования задач, например, выполнения скриптов Bash и Python в заданное время, в заданной последовательности. Сегодня на примере выполнения двух Bash-команд расскажем, как создать свой первый граф. Читайте в этой статье: связи между задачами, создание графа...
Чтобы добавить в курсы по Apache AirFlow еще больше полезных примеров, сегодня рассмотрим, как избежать дублирования кода при загрузке данных. Этот пример пригодится дата-инженерам в работе с ELT-процессами наполнения информацией корпоративных хранилищ и озер данных. Читайте про фреймворк динамической загрузки данных на базе конфигурационных YAML-файлов, DAG-фабрик и загрузчиков. Проблема дублирования...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...

Сегодня в рамках обучения разработчиков Apache Spark и дата-аналитиков, поговорим про детерминированность UDF-функций и особенности их обработки оптимизатором SQL-запросов Catalyst. На практических примерах рассмотрим, как оптимизатор Spark SQL обрабатывает недетерминированные выражения и зачем кэшировать промежуточные результаты, чтобы гарантированно получить корректный выход. Еще раз про детерминированность функций и планы выполнения...