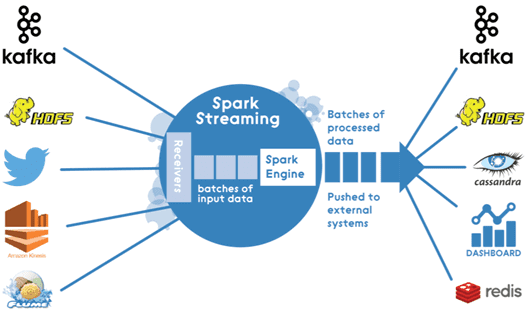
В этой статье мы рассмотрим архитектуру Big Data конвейера по непрерывной обработке потоковых данных в режиме реального времени на примере интеграции Apache Kafka и Spark Streaming. Что такое Spark Streaming и для чего он нужен Spark Streaming – это надстройка фреймворка с открытым исходным кодом Apache Spark для обработки потоковых...
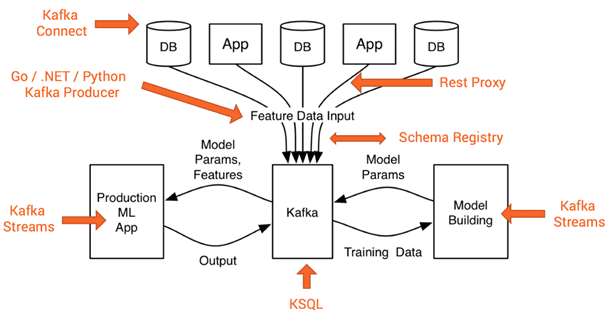
Рассмотрев основы Apache Kafka, сегодня мы расскажем о месте этого распределённого брокера сообщений в архитектуре Big Data систем. Читайте в нашей статье, какие компоненты Кафка обеспечивают ее использование в программных продуктах машинного обучения (Machine Learning, ML), интернете вещей (Internet Of Things, IoT), системах бизнес-аналитики (Business Intelligence, BI), а также других...

В этом выпуске мы продолжаем введение в Data Science для чайников, разбирая профессии Big Data, и рассказываем, кто такой Data Scientist: что необходимо знать ученому по данным и чем исследователь отличается от аналитика. Что делает ученый по данным Как и Data Analyst, исследователь данных тоже работает с информационными массивами путем...

Продолжая разговор про то, с чего начать вход в большие данные, и какие бывают ИТ-специальности, сегодня мы расскажем, чем именно занимается аналитик Big Data, что он должен знать и уметь, а также где и как получить необходимые профессиональные компетенции. Что делает аналитик данных Как правило, Data Analyst работает с информационными...

Этой статьей мы продолжаем серию материалов по ИТ-специальностям мира больших данных и начинаем описывать профессиональные компетенции в области Big Data и машинного обучения (Machine Learning). Ищите в сегодняшнем выпуске ответ на главный вопрос новичка Big Data – с чего начать, что нужно знать и уметь, а также где этому учиться...
Мы уже рассказывали, как интернет вещей (Internet of Things, IoT) вместе с технологиями Big Data и машинного обучения (Machine Learning) используются в нефтегазовой, транспортной, сельскохозяйственной и машиностроительных отраслях. Сегодня поговорим подробнее про промышленный IoT (Industrial Internet of Things, IIoT) на примерах его применения в тяжелом машиностроении и рассмотрим, почему индустриальный...

Продолжая тему «умного» города (data-driven city), сегодня мы собрали для вас 5 практических примеров, как в крупнейших мегаполисах по всему миру интернет вещей и большие данные с датчиков, проездных билетов и дорожных камер помогают бороться с пробками и улучшать состояние дорог, повышая уровень их безопасности и удобства использования. Internet of...

Big Data – это основа бизнеса страховых компаний, работа которых полностью основана на информации: статистике, сведениях о клиентах, страховых случаях и вероятностях их наступления, а также финансовой оценке всех этих данных. Читайте в нашей сегодняшней статье, как «большая тройка» современных информационных технологий (большие данные, машинное обучение и интернет вещей) увеличивают...

Цифровизация различных прикладных отраслей продолжается - сегодня мы нашли для вас интересные кейсы, как большие данные, машинное обучение и интернет вещей используется в жилой и коммерческой недвижимости. Чем Big Data, Machine Learning и Internet Of Things (IoT) полезны строителям и риелторам, и каким образом внедрение этих технологий поможет потребителям. Big...

Цифровизация возможна не только на предприятиях. Цифровая трансформация настигает даже города, чтобы сделать их более удобными для жителей и менее вредными для планеты. Сегодня мы подготовили для вас 8 интересных примеров по 4 разным направлениям об использовании больших данных (Big Data), машинного обучения (Machine Learning) и интернета вещей (Internet of...