
Мы уже разобрали, что общего между Apache Hive и Cloudera Impala. В этой статье рассмотрим работу этих систем с точки зрения программиста, а также поговорим про язык HiveQL. Читайте в сегодняшнем материале, как эти системы выполняют SQL-запросы для аналитики больших данных (Big Data), хранящихся в кластере Hadoop. Что такое HiveQL,...

В прошлой статье мы рассмотрели основные возможности и ключевые характеристики Apache Hive и Cloudera Impala. Сегодня подробнее поговорим про то, что между ними общего и чем отличаются друг от друга эти SQL-инструменты для обработки больших данных (Big Data), хранящихся в кластере Hadoop. Что общего между Apache Hive и Cloudera Impala:...

Сегодня мы рассмотрим Apache Hive и Cloudera Impala – аналитические SQL-средства для работы с данными, хранящимися в экосистеме Apache Hadoop и других Big Data хранилищах: HDFS, HBase, Amazon S3. Читайте в нашей статье, что такое Hive и Impala, где они используются и почему они не заменяют, а дополняют друг друга....
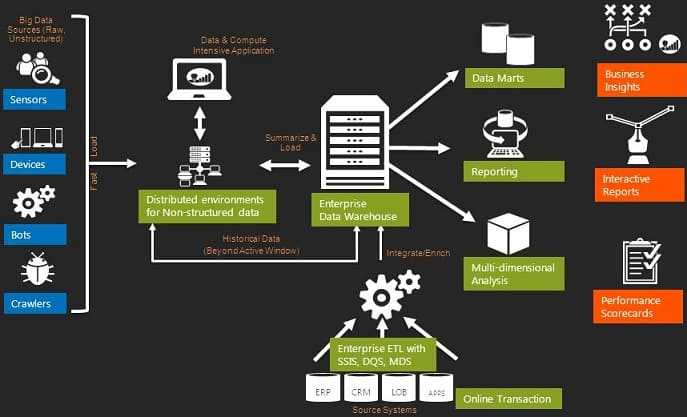
Продолжая разговор про Apache NiFi и другие ETL-инструменты больших данных, сегодня мы подробнее расскажем про пакетные средства загрузки и маршрутизации информации из различных источников: Sqoop, Chuckwa и Falcon. Читайте в нашей статье, чем они похожи и чем отличаются, а также как применяются в Big Data системах и интернете вещей (Internet...
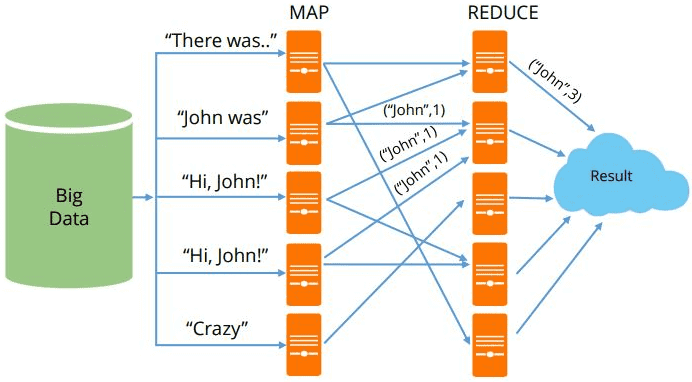
MapReduce можно назвать основой Big Data, т.к. именно данная технология позволяет обрабатывать огромные массивы информации параллельно в распределенных кластерах. Эту вычислительную модель поддерживают множество различных коммерческих и свободных продуктов: Apache Hadoop, Spark, Greenplum, Hive, MongoDB, Phoenix, DryadLINQ и прочие Big Data фреймворки и библиотеки, написанные на разных языках программирования [1]. Сегодня...

Apache Samza часто сравнивают с другими Big Data фреймворками распределенных потоковых вычислений в реальном времени (Real Time, RT): Kafka Streams, Spark Streaming, Flink и Storm. Apache Spark и Flink обладают практически одинаковым набором функциональных возможностей и компонентов, поэтому их можно сравнивать между собой более-менее объективно. Apache Samza является более простой...

Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм,...

Сегодня мы рассмотрим популярные Big Data инструменты обработки потоковых данных: Apache Kafka Streams и Spark Streaming: чем они похожи и чем отличаются. Стоит сказать, что Спарк Стриминг и Кафка Стримс – возможно, наиболее популярные, но не единственные средства обработки информационных потоков Big Data. Для этой цели существует еще множество альтернатив,...
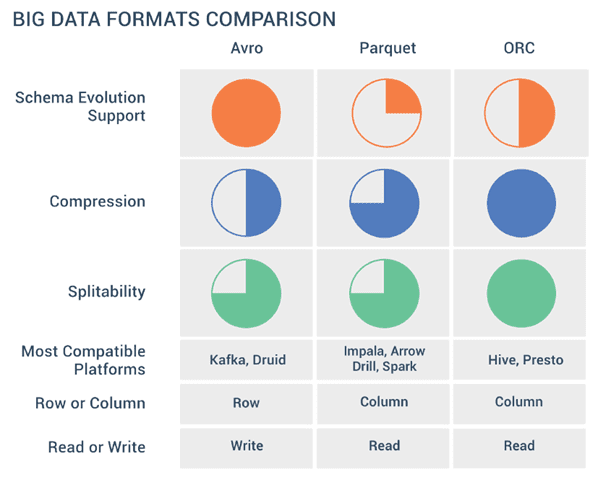
Продолжая разговор про форматы Big Data файлов, сегодня мы рассмотрим разницу между линейными и колоночными типами, а также расскажем о том, как выбирать между AVRO, Sequence, Parquet, ORC и RCFile при работе с Apache Hadoop, Kafka, Spark, Flume, Hive, Drill, Druid и других средствах работы с большими данными. Итак, форматы...

Мы уже упоминали формат Parquet в статье про Apache Avro, одну из наиболее распространенных схем данных Big Data, часто используемую в Kafka, Spark и Hadoop. Сегодня рассмотрим более подробно, чем именно хорошо Apache Parquet и как он отличается от других форматов Big Data. Что такое Apache Parquet и как он...