 1344
1344 
Содержание
Мы уже разобрали, что общего между Apache Hive и Cloudera Impala. В этой статье рассмотрим работу этих систем с точки зрения программиста, а также поговорим про язык HiveQL. Читайте в сегодняшнем материале, как эти системы выполняют SQL-запросы для аналитики больших данных (Big Data), хранящихся в кластере Hadoop.
Что такое HiveQL, зачем он нужен и чем отличается от классического SQL
Напомним, среда Hadoop неэффективна в интерактивной (потоковой) обработке масштабных структурированных данных из-за пакетной специфики вычислительной модели MapReduce, которая не позволяет выполнять сложные аналитические запросы в режиме реального времени с максимально допустимой задержкой в несколько миллисекунд. Эта проблема успешно решается в реляционных OLTP-системах с помощью SQL-запросов, которые дают разработчику возможность формулировать задачи на декларативном языке высокого уровня и оставлять детали оптимизации внутреннему механизму.
В Apache Hive и Cloudera Impala запросы к данным, хранящимся в Hadoop, реализуются на SQL-подобном декларативном языке Hive Query Language (HiveQL), который является подмножеством SQL92. Однако, в ряде случаев HiveQL отличается от стандартного SQL, в частности [1]:
- разные способы определения операций join для максимальной производительности;
- в HiveQL нет некоторых функций, операций и операторов SQL (UPDATE и DELETE statements, INSERT для отдельных строк);
- HiveQL позволяет вставлять пользовательский код для ситуаций, которые не вписываются в типовой SQL, предоставляя соответствующие инструменты для обработки входа и выхода – определенные пользователем функции: User Defined Function (UDF), User Defined Aggregate Function (UDAF), User Defined Tabular Function (UDTF);
- HiveQL не поддерживает типы данных даты и времени, т.к. они рассматриваются как строки.
Как и в SQL, в HiveQL имеется собственные парсер, планировщик, исполнитель и оптимизатор запросов, который ускоряет трансляцию запроса в исполняемый код, о чем мы рассказывали здесь на примере Catalyst – оптимизатора Apache Spark. Хайв и Импала по-разному работают с HiveQL, реализуются свои механизмы выполнения запросов, которые мы рассмотрим далее.
Как выполняется SQL-запрос в Cloudera Impala
Импала выполняет структурированные запросов к данным, хранящимся в Apache Hadoop, последовательно в несколько этапов [2]:
- Big Data приложение со стороны пользователя отправляет SQL-запрос в Impala через ODBC или JDBC. Эти драйверы предоставляют стандартизованные интерфейсы запросов, благодаря чему пользовательское приложение может подключаться к любой системной службе Импала (impala daemon, impalad) в кластере. Далее этот impalad становится координатором текущего запроса.
- Импала анализирует SQL-запрос, чтобы определить, какие задачи должны выполняться impalad-экземплярами в кластере. С учетом оптимальной эффективности планируется выполнение запроса.
- Доступ impalad к данным в HDFS и HBase осуществляется напрямую локальными экземплярами сервисов для предоставления данных.
- Каждый daemon возвращает данные координирущему impalad, который отправляет эти результаты клиенту в пользовательское приложение.
Отметим, что Impala избегает любых возможных накладных расходов при запуске, поскольку все процессы системных демонов запускаются непосредственно во время загрузки. Это существенно экономит время выполнения запроса. Дополнительное повышение скорости работы Импала обусловлено тем, что этот SQL-инструмент для Hadoop, в отличие от Hive, не сохраняет промежуточные результаты и обращается напрямую к HDFS или HBase. Кроме того, Impala генерирует программный код во время исполнения (runtime), а не при компиляции (compile time), как это делает Hive. Однако, побочным эффектом такой высокой скорости работы Impala является понижение надежности. В частности, если во время выполнения SQL-запроса узел данных отключится, экземпляр Импала запустится заново, а Hive продолжит держать соединение с источником данных, обеспечивая отказоустойчивость [3].
При кодогенерации во время выполнения программы в Impala используется LLVM (Low Level Virtual Machine) — проект инфраструктуры для создания компиляторов и сопутствующих утилит. Этот компилятор на виртуальной машине с RISC-подобными инструкциями генерирует оптимальный код выполнения SQL-запроса, представляя собой набор компиляторов из языков высокого уровня, системы оптимизации, интерпретации и компиляции в машинный код [4].
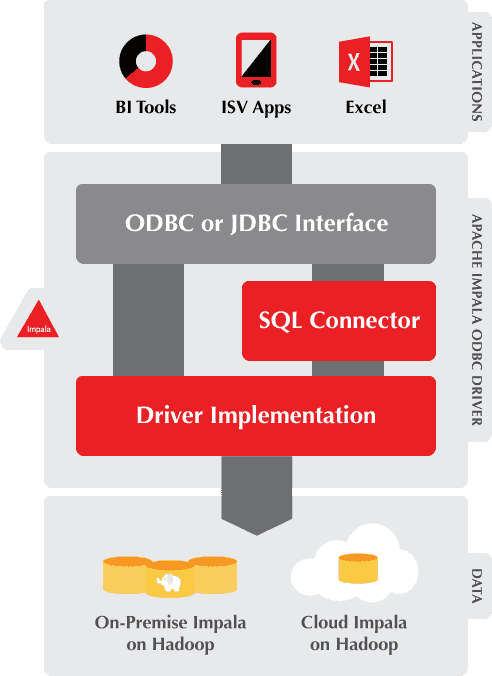
Как работает Apache Hive: Big Data аналитика для Hadoop
Как в большинстве СУБД, в Hive есть несколько способов запуска SQL-запросов [5]:
- интерфейс командной строки – Hive Shell (CLI, Command Line Interface);
- подключение к БД через JDBC или ODBC с помощью драйвера Hive;
- использование клиента, установленного на уровне пользователя (среднее звено классической трехуровневой архитектуры). Этот клиент общается с сервисами Hive, работающими на сервере. Такой подход можно применять в приложениях, написанных на разных языках (C++, Java, PHP, Python, Ruby), используя эти клиентские языки со встроенным SQL для доступа к базам данных. По сути, таким образом реализуется web-UI Хайв.
Hive включает в себя следующие обязательные компоненты [5]:
- HCatalog для управления таблицами и хранилищами Hadoop, который снабжает пользователей различными инструментами обработки больших данных, включая MapReduce и Apache Pig для более простого чтения и записи данных.
- WebHCat предоставляет сервисы, которые можно использовать для запуска задач Hadoop MapReduce, Pig, заданий (jobs) или операций с метаданными Hive с помощью интерфейса HTTP в стиле REST.
Для доступа к метахранилищу (MetaStore) используется Apache Thrift – фреймворк удаленного вызова процедур (RPC, Remote Procedure Call), высокоуровневый язык описания интерфейсов, который позволяет определять и создавать службы под разные языки программирования [6].
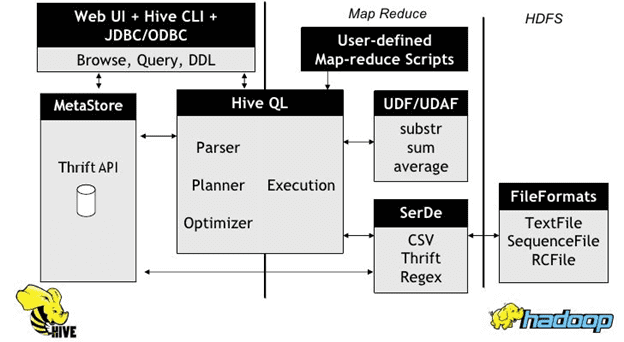
Hive является средством трансляции SQL-запросов в задачи MapReduce: HiveQL-выражения преобразуются в задания MapReduce, которые выполняются в Apache кластере Hadoop и формируются в окончательный результат. Из-за этого даже простейшие запросы к таблице приводят к полному сканированию данных, содержащихся в ней. Это приводит к временной задержке при обработке данных. Что избежать такого полного сканирования данных, можно некоторые столбцы таблицы распределить по разным разделам (partition). Эта операция называется партиционирование и означает, что данные, относящиеся к разным колонкам, будут физически храниться в разных папках на HDFS. Партиционирование позволяет существенно сократить время исполнения SQL-запроса. Например, таким образом можно разделить хранимые логи по датам, что является частой задачей при анализе статистических данных с привязкой в временным периодам [5].
Партиционирование таблиц возможно и в Impala, однако при выделении разделов стоит помнить о размерах блока HDFS. Например, в случае таблиц из файлов Parquet размер блока HDFS составляет 256 МБ в Impala 2.0 и более поздних версиях. Таким образом, механизм секционирования (партиционирования) таблиц значительно повышает быстродействие HiveQL-запросов как в Хайв, так и в Импала [4].
Наконец, резюмируя отличия Hive и Impala в плане выполнения SQL-запросов с точки зрения разработчика Big Data, отметим разницу в поддерживаемых типах данных. Хайв поддерживает все основные примитивные (integer, float и string), а также сложные типы данных (map, list и struct), в отличие от Impala [7]. В плане обеспечения информационной безопасности Импала и Хайв также отличаются друг от друга. Об этом мы расскажем в следующей статье. А про методы оптимизации SQL-запросов в Apache Hive читайте здесь.
Как настроить и эффективно запустить аналитики больших данных с помощью этих инструментов SQL-on-Hadoop, вы узнаете на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://www.ibm.com/developerworks/ru/library/ba-compare-sql-access-hadoop/index/
- https://ru.bmstu.wiki/Apache_Impala
- https://data-flair.training/blog/impala-vs-hive/
- https://www.vtbcareer.com/article/ozero-dannih/
- https://ru.bmstu.wiki/Apache_Hive
- https://ru.wikipedia.org/wiki/Apache_Thrift
- https://www.educba.com/hive-vs-impala/

