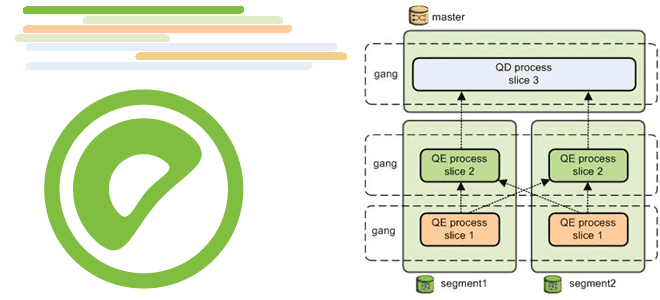
Как координатор Greenplum на мастер-хосте рассылает сегментам планы выполнения запросов, что такое курсор параллельного получения результатов оператора SELECT и каким образом его использовать для аналитики больших данных в этой MPP-СУБД. Особенности рассылки планов SQL-запросов в Greenplum на выполнение Хотя Greenplum основана на PostgreSQL, некоторые механизмы работы этих СУБД отличаются. Например,...

Чем кэширование в OLAP-системах отличается от OLTP и как устроен кэш запросов ClickHouse: принципы работы, конфигурационные настройки и примеры использования SELECT-оператора. Особенности кэширования в ClickHouse Кэширование является одним из методов повышения производительности, который сокращает время на получение результатов вычислений за счет их хранения в области быстрого доступа. Обычно кэшируются результаты...
Как с Apache Flink настроить локальную службу OLAP, а также развернуть ее в рабочей среде производственного кластера: архитектура, принципы работы и параметры конфигурации для сложных аналитических сценариев. Служба Flink OLAP: архитектура и принципы работы Идея выделить в Apache Flink механизм OLAP для анализа данных в потоковом хранилище появилась еще год...

30 апреля 2024 года опубликован очередной выпуск ClickHouse, который включает 13 новых функций, 16 улучшений производительности и 65 исправлений ошибок. Знакомимся с самими интересными новинками релиза 24.4. Значимые новинки Clickhouse 24.2 Начнем с повседневных операций с таблицами: теперь в ClickHouse можно зараз удалить несколько таблиц со всем их содержимым, используя...
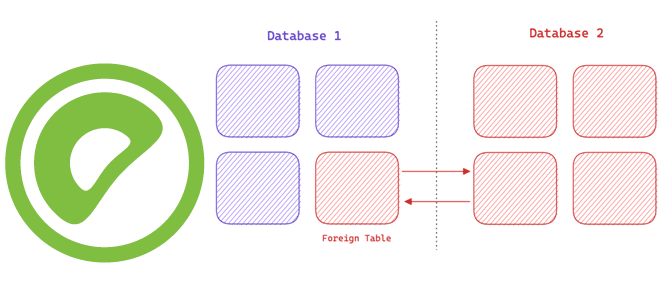
Чем внешняя таблица Greenplum отличается от сторонней, и как они преобразуются друг в друга: организация доступа к данным вне базы, FDW-обертки и протоколы для интеграции MPP-СУБД с другими источниками информации. Сторонняя таблица в Greenplum Термины внешняя (external) и сторонняя (foreign) table похожи, но нюансы их использования в Greenplum отличаются. Такие...
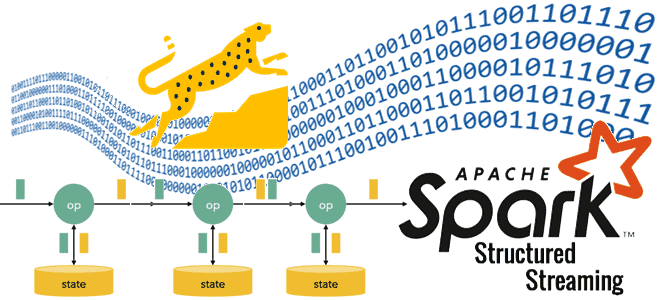
Где stateful-операторы хранят состояния, почему RocksDB лучше HDFSBackedStateStore и как Databricks адаптировал key-value хранилище к особенностям Spark Structured Streaming, чтобы сделать потоковую обработку больших данных еще быстрее. Где stateful-операторы Spark Structured Streaming хранят состояния? Хотя Apache Spark Structured Streaming реализует потоковую парадигму обработки информации, он по-прежнему использует микропакеты, т.е. ограниченные...
Как связать ClickHouse с Apache Kafka: примеры проектирования и реализации онлайн-аналитики с использованием облачного сервиса колоночной СУБД, брокера сообщений и BI-системы Яндекса. Постановка задачи и проектирование потокового конвейера Для взаимодействия с внешними хранилищами ClickHouse использует специальные механизмы – интеграционные движки таблиц. Вчера я показывала пример интеграции ClickHouse со встроенной key-value...

Сегодня разберем, как из ClickHouse обратиться к встроенной key-value БД RockDB, используя табличный движок EmbeddedRocksDB, и познакомимся с возможностями новой песочницы колоночной базы данных. Постановка задачи и DDL-скрипты Колоночная СУБД ClickHouse поддерживает несколько движков таблиц, включая интеграционные механизмы для взаимодействия со сторонними системами, одной из которых является key-value база данных...

18 марта 2024 года вышел очередной релиз Apache Flink. Знакомимся с его главными новинками и разбираемся, чем они полезны для потоковой обработки больших данных: ключевые изменения выпуска 1.19 для разработчика stateful-приложений. Динамическая настройка параллелизма Выпуск Apache Flink 1.19 можно назвать значимой вехой, поскольку он не только включает новые функции, улучшения...
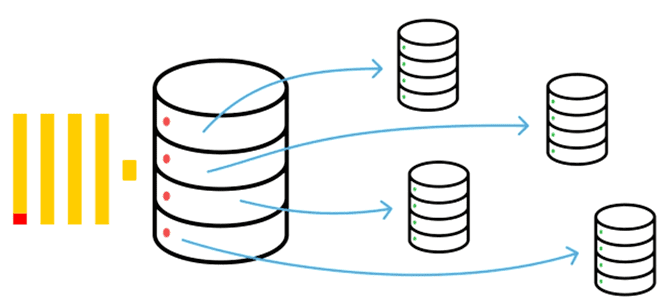
Как повысить производительность ClickHouse с помощью горизонтального масштабирования, разделив данные на шарды: принципы шардирования, стратегии выбора ключа, особенности работы с distributed-таблицами и настройки конфигураций сервера. Шардирование в ClickHouse Именно хранилище данных всегда является узким местом любой системы. Поэтому именно его надо расширить для повышения производительности. Это можно сделать с помощью...
Где хранятся состояния операторов в stateful-приложениях Apache Spark Structured Streaming, зачем разработчику нужны данные о состояниях, как их получить и чем для этого полезен новый API State Reader от Databricks. Хранение состояние в Apache Spark Structured Streaming В феврале 2024 года компания Databricks выпустила очередную версию Databricks Runtime – среду...
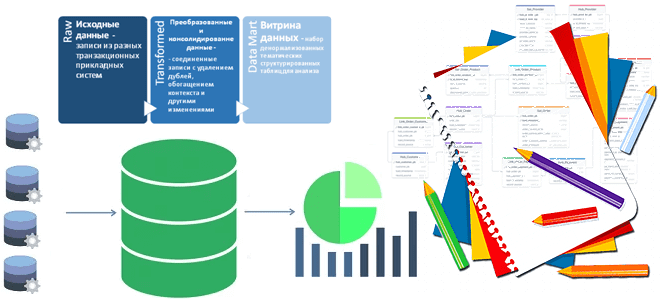
Как построить хранилище данных с подходом Data Vault: пример проектирования схемы данных и разработка DDL-скрипта для Transformed-слоя DWH интернет-магазина. Слоистая структура DWH и подход Data Vault Корпоративное хранилище данных (DWH, Data Warehouse) часто бывает гетерогенным, т.к. организованным с помощью нескольких баз данных, связанных ETL-процессами. Согласно концепции слоистой архитектуры (LSA, Layered...

От оркестрации и синхронизации конвейеров обработки данных до управления хранилищами, включая хранение состояний для stateful-приложений: сложности проектирования архитектуры потоковой обработки событий и способы их решения. Основные сложности проектирования современной архитектуры данных Из-за принципиальных отличий потоковой парадигмы обработки данных от пакетной, что разбиралось здесь, задача проектирования дата-конвейеров сильно усложняется, т.к. редко...

Как с помощью Flink SQL организовать потоковую агрегацию данных из таблицы PostgreSQL: знакомство с API таблиц в Ververica Cloud на практическом примере. API таблиц Ververica Cloud: создаем внешние источники и приемники данных Как я недавно рассказывала, немецкая фирма Ververica создала высокопроизводительный облачный сервис для обработки данных в реальном времени на...
Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven. Постановка задачи и проектирование конвейера Как обычно, в...
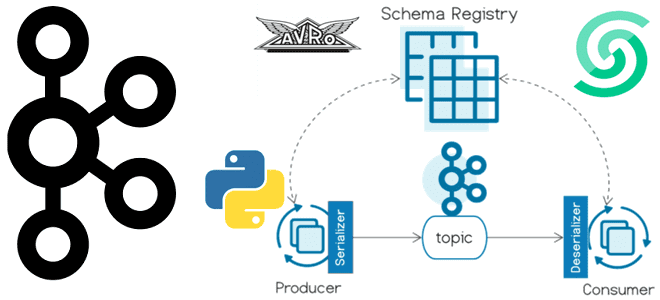
Сегодня я покажу пример использования реестра схем для Apache Kafka на платформе Upstash, API которого полностью совместим со Schema Registry от Confluent. Пишем продюсер на Python, используя библиотеку confluent_kafka. Еще раз о том, что такое реестр схем Kafka и чем он полезен Реестр схем (Schema Registry) – это модуль Confluent...

Когда журналирование событий может привести к OOM-ошибке, где отслеживать системные метрики приложения Apache Spark, зачем сжимать лог-файлы и как это сделать. Логирование системных метрик в приложении Apache Spark Поскольку фреймворк Apache Spark изначально предназначен для создания высоконагруженных распределенных приложений пакетной и потоковой обработки больших объемов данных, он позволяет отслеживать системные...
Зачем Databricks выпустил Arc, чем это отличается от Splink, и как эти инструменты позволяют решать проблему связывания данных с помощью алгоритмов машинного обучения. Как работает связывание данных Продолжая разговор про качество данных и разрешение сущностей (entity resolution) , сегодня подробно рассмотрим этап связывания записей с использованием логики на основе правил...
Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать. Борьба за качество данных с entity resolution Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь....
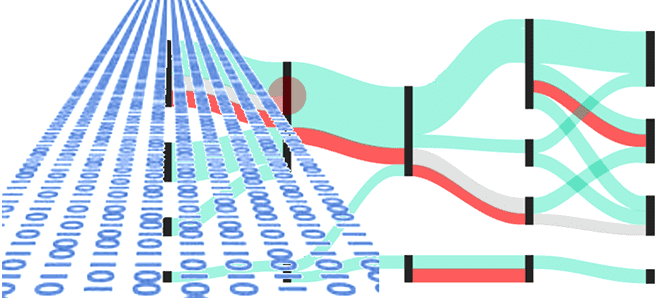
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink. Еще раз о разнице потоковой и пакетной парадигмы обработки данных Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных....