
Развивая наши курсы по Apache AirFlow для дата-инженеров и администраторов, сегодня рассмотрим, как автоматизировать обслуживание этого фреймворка, запуская поддерживающие операции как рабочие задачи по расписанию. В этой статье разбираем опыт дата-инженеров американской ИТ-компании Clairvoyant, предложивших сообществу 3 разных DAG по обслуживанию Apache AirFlow в виде open-source проектов, доступных для свободного...

Чтобы сделать наши курсы по Greenplum и аналитике больших данных еще более полезными, сегодня рассмотрим особенности выполнения SQL-запросов в этой MPP-СУБД. Читайте далее, зачем и когда запускать оператор анализа табличной статистики ANALYZE, как он связан с планом выполнения SQL-запроса и какие инструменты помогут дата-инженеру, аналитику или разработчику повысить их производительность....
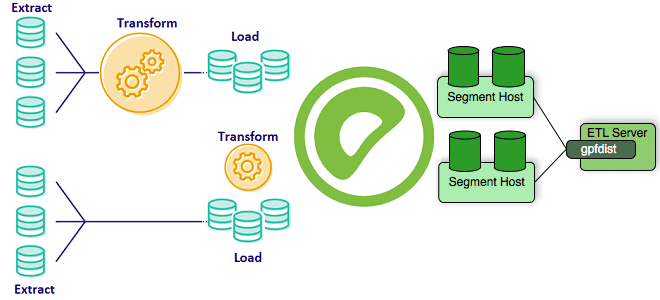
Greenplum часто используется в качестве корпоративного хранилища или аналитического озера данных (Data Lake). Поэтому важно знать особенности реализации ETL-процессов при работе с этой MPP-СУБД, что входит в наш новый курс «Greenplum для инженеров данных». Сегодня рассмотрим способы загрузить большие данные в Greenplum, разберем отличия внешних таблиц от внутренних и отметим,...
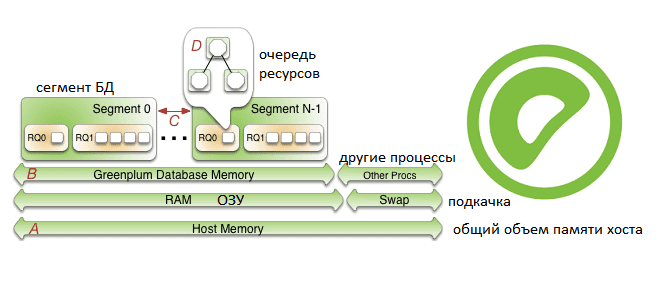
Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня поговорим про особенности конфигурирования памяти в этой MPP-СУБД: разберем, как память хоста распределяется между сегментами и рассмотрим, как администратор кластера может ускорить работу этой базы данных. Также читайте далее о связи RAM с настройками ядра операционной системы и схемами...

Cегодня рассмотрим некоторые инструменты защиты данных в Greenplum. Читайте далее про особенности шифрования в этой MPP-СУБД и лучшие практики обеспечения информационной безопасности и защиты в этой системе хранения и аналитики больших данных. Администраторы и суперпользователи Greenplum Для надежной защиты данных, хранящихся в MPP-СУБД Greenplum, и обеспечения информационной безопасности кластера рекомендуется...

Развивая наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим, почему в этой MPP-СУБД возникают проблемы нехватки памяти, каковы типовые способы их решения и чем очереди ресурсов отличаются от ресурсных групп. Читайте далее про схемы управления ресурсами в Greenplum и особенности параметра конфигурации statement_mem. Очереди vs Группы: 2 схемы управления...

Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим некоторые особенности хранения данных в этой MPP-СУБД, а также разберем связанные с ними лучшие практики ее администрирования. Читайте далее про важность RAID-массивов, механизмы дублирования кластеров, утилиты резервного копирования и восстановления данных в Greenplum. RAID-массивы и зеркалирование жестких дисков...

Один из факторов повышенной надежности Apache Kafka обеспечивается записью сообщений на жесткий диск. Однако, операции ввода-вывода (IO, input-output) с дисковым пространством считаются медленными и часто являются узким местом во всей системе. Спустившись на уровень операционной системы и ядра, сегодня рассмотрим, как Kafka справляется с этим ограничением, позволяя быстро обрабатывать огромные...

В этой статье разберем одну из тем практического обучения администраторов Apache Kafka и рассмотрим разницу между сохранением сообщений и фиксированных смещений в этой Big Data платформе потоковой обработке событий. Читайте далее про конфигурации потребителя и брокера, отвечающие за время хранения сообщений и политику очистки журналов. Еще раз про offset или...

KIP-500, который позволяет наконец-то избавиться от Zookeeper в кластере Apache Kafka, заменив его Quorum Controller – далеко не единственное важное обновление в релизе 2.8.0. Сегодня рассмотрим, какие еще улучшения реализованы в новой версии главной Big Data платформы потоковой обработки событий, выпущенной в апреле 2021 года. Apache Kafka 2.8.0: новинки главных...