
Партиционирование таблиц – надежный способ повышения производительности Greenplum, который тесно связан с особенностями распределения данных по сегментам кластера. Читайте далее, чем опасно неравномерное распределение данных и вычислений по узлам, а также как найти дата-инженеру и устранить эти перекосы в MPP-СУБД, чтобы повысить скорость выполнения SQL-запросов и решить проблемы с нехваткой...
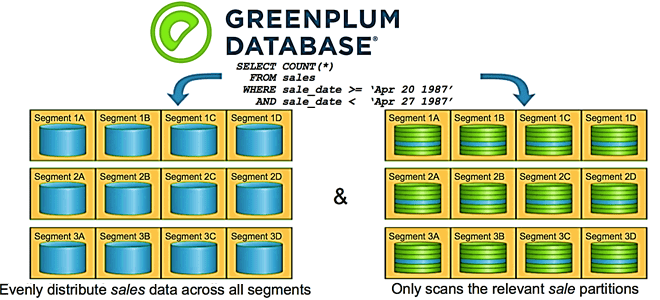
Мы уже рассказывали про основы хранения и аналитики больших данных в Greenplum, а также рассматривали особенности индексации и сжатия данных в этой MPP-СУБД. Продолжая разговор о нашем новом курсе «Greenplum для инженеров данных», сегодня разберем лучшие практики разбиения данных на разделы и пример их распределения по сегментам кластера. Кратко о...

В продолжение вчерашней статьи по нашему новому курсу «Greenplum для инженеров данных», сегодня рассмотрим особенности индексации и сжатия данных в этой MPP-СУБД. Читайте далее, почему в Greenplum можно обойтись без индексов, когда выбирать RLE-сжатие вместо zlib, зачем сжимать рабочие файлы при выполнении SQL-запросов и что такое селективность индекса. ТОП-10 советов по...

Продвигая наш новый курс «Greenplum для инженеров данных», сегодня мы рассмотрим особенности организации таблиц в этой MPP-СУБД, типы данных и оптимальное расположение столбцов. Читайте далее, чем heap storage отличается от append-optimized, когда выбирать колоночную, а когда – строковую модель хранения данных для таблицы, почему BIGINT с TIMESTAMP следует размещать перед...

В этой статье разберем одну из тем практического обучения администраторов Apache Kafka и рассмотрим разницу между сохранением сообщений и фиксированных смещений в этой Big Data платформе потоковой обработке событий. Читайте далее про конфигурации потребителя и брокера, отвечающие за время хранения сообщений и политику очистки журналов. Еще раз про offset или...

Сегодня рассмотрим Apache Spark с точки зрения Data Science специалиста: поговорим про сходства и отличия библиотек машинного обучения в этом фреймворке. Также ответим на вопрос «Spark ML vs MLLib», разберем, зачем Data Scientist’у и аналитику больших данных нужны курсы по Apache Spark, а в заключение отметим наиболее важные улучшения библиотеки...

Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
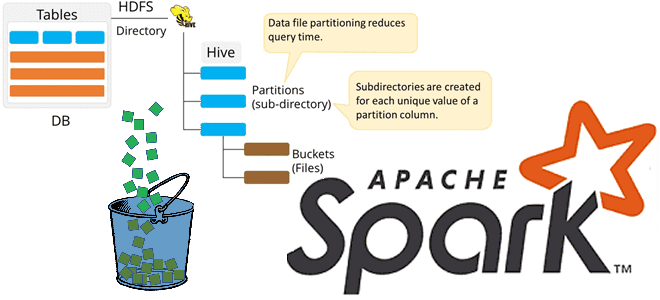
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Вчера мы говорили про важные обновления Apache Kafka 2.8.0, помимо долгожданного KIP-500, который позволяет избавиться от Zookeeper для синхронизации метаданных в распределенном кластере с помощью встроенного Quorum Controller. Сегодня рассмотрим, какие KIP’ы нового релиза коснулись одного из основных инструментов разработчика Apache Kafka – библиотеки Streams для создания распределенных приложений потоковой...