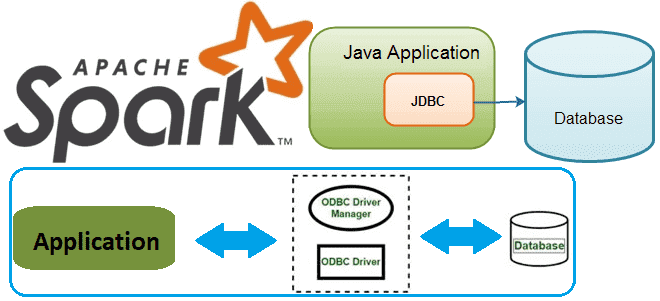
В этой статье для разработчиков распределенных приложений и дата-инженеров разберем, как Spark-задание может подключиться к базе данных через JDBC и ODBC драйверы. В качестве примера рассмотрим код на PySpark и Python-библиотеки pyodbc, а также JDBC-коннекторы в Spark SQL.
Доступ к БД из кластера Spark с ODBC-драйвером
Напомним, получить соединение с БД по URL, т.е. обеспечить подключение приложения к СУБД, позволяют драйверы:
- JDBC (Java DataBase Connectivity) – платформенно независимый промышленный стандарт взаимодействия Java-приложений с различными СУБД в виде пакета java.sql в составе платформы Java Standart Edition.
- ODBC (Open Database Connectivity)– стандартная прикладная программная среда для связи и доступа к СУБД от Microsoft, которая поддерживает любые языки программирования, но работает только на Windows как слой между СУБД и приложением.
По сути, драйверы выполняют роль API с методами доступа клиента к СУБД. В отличие от ODBC, JDBC подходит только для Java, но является универсальным в плане платформы, т.е. операционной системы, работая как на Linux, так и Windows. В строке подключения к БД в коде приложения пишется адрес хоста, где она расположена, порт и имя самой БД, учетные данные (логин и пароль пользователя), а также сертификат шифрования, например, SSL.
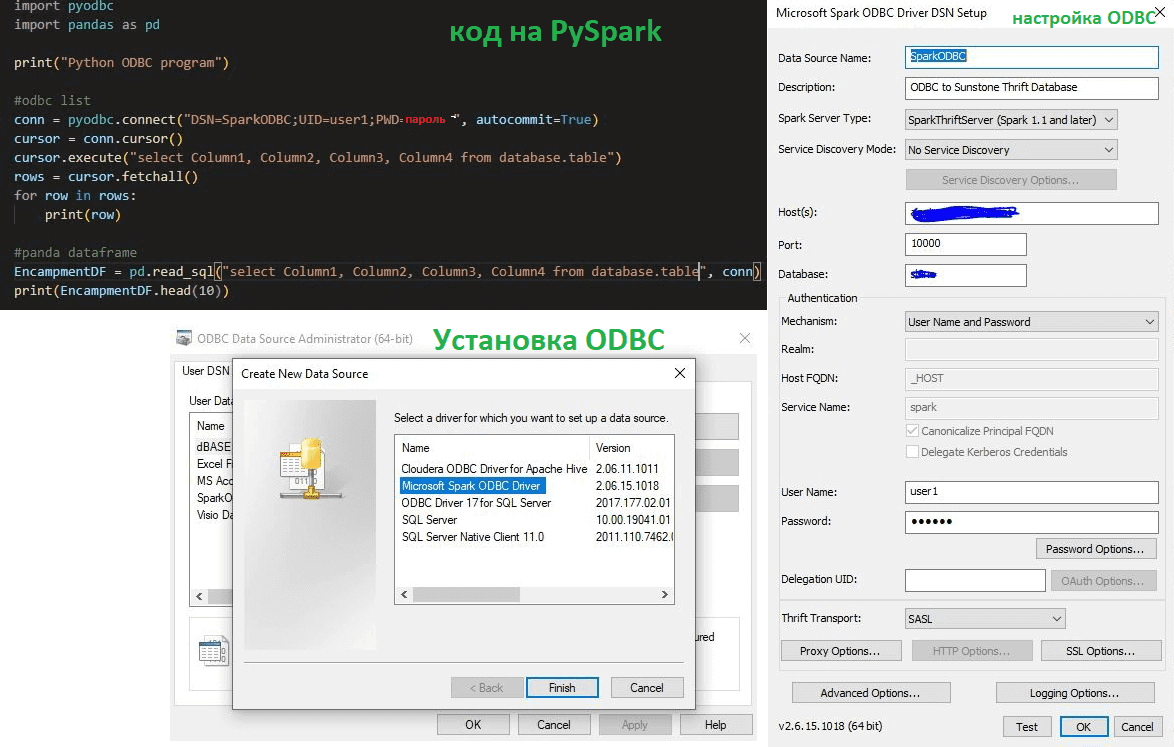
Например, в библиотеке pyodbc, которая представляет собой Python-модуль с открытым исходным кодом, упрощающий доступ к базам данных ODBC, реализуется спецификация DB API 2.0 в стиле Python. Здесь соединения с базами данных выполняются с помощью строк подключения в функции pyodbc.connect(). Однако, pyodbc даже не просматривает строку подключения, а передается напрямую драйверу базы данных без изменений через SQLDriverConnect. Поэтому строки подключения зависят от драйвера. Пакет pyodbc поддерживает все функции ODBC, включая соединения без DSN и файловые DSN.
Хотя pyodbc не изменяет строку подключения, она все равно проходит через несколько уровней экранирования, прежде чем достигнет драйвера: Python и диспетчер драйверов. Это важно для значений в строках подключения, которые могут содержать спецсимволы, например пароли. Поэтому наивный подход объединения ключей и значений в строки соединения без учета возможности использования спецсимволов не сработает при их наличии. К примеру, в Python применяются обычные правила экранирования строк: обратная косая черта и кавычки, которые должны появляться в строке подключения, должны быть экранированы, а фигурные скобки {} должны быть удвоены.
Диспетчер драйверов и, следовательно, драйверы ODBC интерпретируют строку подключения как набор пар ключ-значение, разделенных точкой с запятой. Ключи либо определяются стандартом ODBC, например, DSN, DRIVER и FILEDSN, либо специфичны для драйвера ODBC. Значения могут быть указаны напрямую, или заданы с учетом правил экранирования. Помимо правил экранирования Python и диспетчера драйверов, драйверы ODBC могут сами определять дополнительный синтаксис в строке подключения, например, для значений, которые принимают двоичные данные.
После установки и настройки ODBC на компьютере, где ведется разработка, можно написать простой код на Python для извлечения записей из кластера Apache Spark.
Работа с JDBC
Spark SQL также включает источник данных, который может считывать данные из других баз данных с помощью JDBC-драйвера, что предпочтительнее класса JdbcRDD, т.к. результаты возвращаются в виде датафрейма, и их можно легко обрабатывать в Spark SQL или объединять с другими источниками данных. Источник данных JDBC также легче использовать из Java или Python, поскольку он не требует от пользователя предоставления ClassTag. Не стоит путать источник данных JDBC с сервером JDBC Spark SQL, который позволяет другим приложениям выполнять запросы с использованием Spark SQL, о чем мы писали здесь.
Для работы с источником данных JDBC в Spark SQL сперва следует включить драйвер JDBC для конкретной базы данных в путь к классам Spark. Например, чтобы подключиться к PostgreSQL из Spark Shell, надо выполнить следующую команду:
./bin/spark-shell --driver-class-path postgresql-9.4.1207.jar --jars postgresql-9.4.1207.jar
Важно отметить, что аутентификация Kerberos с помощью keytab не всегда поддерживается драйвером JDBC. В источнике данных JDBC для Spark SQL имеется встроенный провайдер соединений, поддерживающий используемую базу данных. В частности, есть встроенные провайдеры подключения для DB2, MariaDB, MS SQL, Oracle и PostgreSQL. Если этих коннекторов не хватает, можно использовать методы API-интерфейса разработчика JdbcConnectionProvider для обработки пользовательской проверки подлинности.
Следующий участок кода на PySpark показывает, как Spark-задание может прочитать данные из источника данных JDBC, которым является реляционная СУБД PostgreSQL, а также как записать туда данные из датафрейма снова.
# Loading data from a JDBC source
jdbcDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.load()
jdbcDF2 = spark.read \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"})
# Specifying dataframe column data types on read
jdbcDF3 = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.option("customSchema", "id DECIMAL(38, 0), name STRING") \
.load()
# Saving data to a JDBC source
jdbcDF.write \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.save()
jdbcDF2.write \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"})
# Specifying create table column data types on write
jdbcDF.write \
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)") \
.jdbc("jdbc:postgresql:dbserver", "schema.tablename",
properties={"user": "username", "password": "password"})
Освойте администрирование и использование Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники