1168
1168 
Что такое программирование потоков данных и как ключевые идеи FBP-парадигмы обеспечивают высокую скорость и мощь Apache NiFi в потоковой обработке.
Что такое Flow-Based Programming
Каждый дата-инженер, работающий с Apache NiFi, знает, что этот фреймворк поддерживает потоковую обработку информации, понимая под потоком неограниченно поступающие данные. Однако, фундаментальные концепции NiFi основаны на ключевых идеях потоко-ориентированное программирование (FBP, Flow-Based Programming). Эта парадигма программирования имеет длительную историю (с конца 60-х годов XX века) и использует метафору фабрики обработки данных для проектирования и создания приложений. FBP определяет приложения как сети процессов черного ящика — компонентов, взаимодействующих друг с другом через фрагменты данных (информационные пакеты), которые перемещаются по заранее определенным соединениям. FBP — это особый случай программирования потоков данных, характеризующийся асинхронными, параллельными процессами «под обложкой», информационными пакетами с определенным временем жизни, именованными портами, соединениями с «ограниченным буфером» и их определением, внешних по отношению к компонентам.
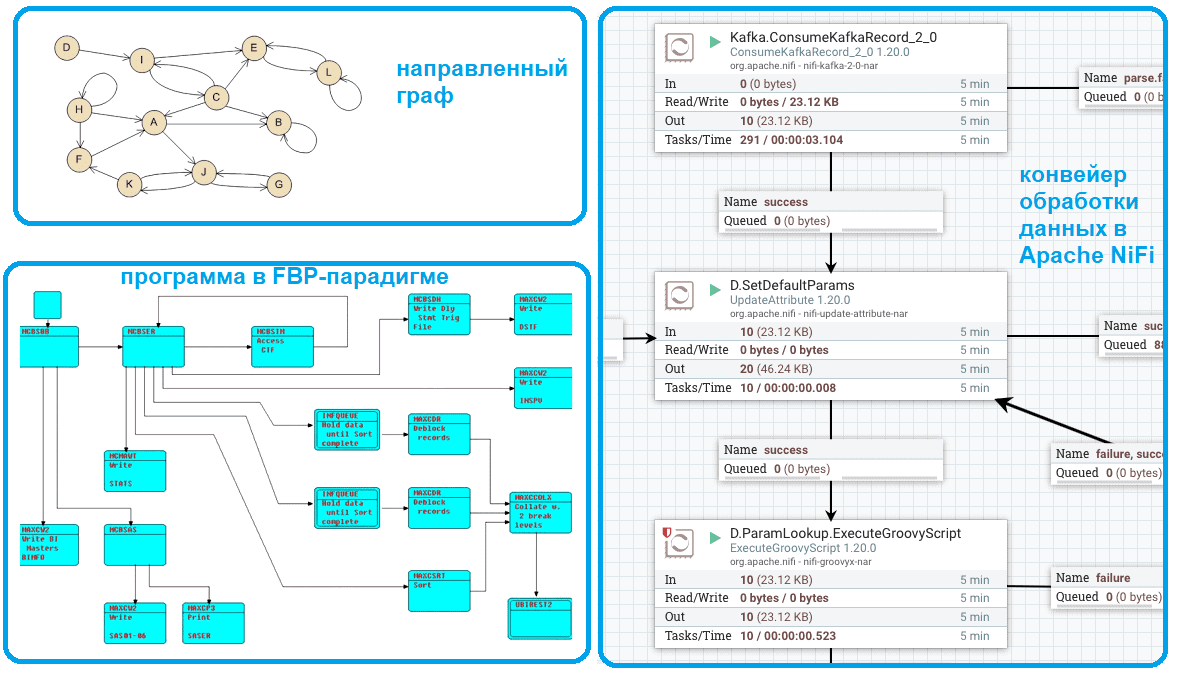
С математической точки зрения FBP оперирует понятиями теории графов, представляя программу как ориентированный граф, в вершинах (узлах) которого выполняются единичные вычисления, т.е. входные данные преобразуются в выходные. Узлы посылают и принимают данные через порты — точки соединения дуг (рёбер графа) и узлов. На практике эта идея используется в нотациях функционально-событийного моделирования бизнес-процессов, например, BPMN.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Как FBP-парадигма отражена в Apache NiFi
Краткий ликбез по FBP-парадигме знакомит нас с термином информационный пакет, роль которого в Apache NiFi играет FlowFile – объект, который перемещается по конвейеру обработки данных и имеет набор атрибутов в виде пары ключ/значение, а также содержимое из нуля или более байтов.
В качестве черного ящика в NiFi выступает процессор (processor) – обработчик, который выполняет операции маршрутизации, преобразования или передачи данных между системами. Процессоры имеют доступ к атрибутам FlowFile и его потока содержимого, могут работать с одним или несколькими FlowFile в заданной единице работы, фиксируя ее или откатывая назад.
Соединение (connection) обеспечивает фактическую связь между процессорами, являясь очередью и позволяя различным процессам взаимодействовать с разной скоростью. Этим очередям можно динамически определять приоритеты и верхние границы нагрузки, обеспечивая обратное давление (backpressure). Каждое соединение содержит очередь FlowFile. Когда FlowFile передается в определенное соединение, он добавляется в очередь, принадлежащую связанному соединению.
Контроллер потока (Flow Controller) в NiFi соответствует понятию планировщика в FBP и хранит сведения о том, как процессы соединяются, а также управляет потоками и их распределением. По сути, он действует как брокер обмена информационными пакетами между процессорами.
А группа процессов (Process Group) в NiFi — это аналог подсети в FBP, которая объединяет набор процессов и их соединений, чтобы получать данные через входные порты и отправлять их через выходные. Так можно создавать совершенно новые компоненты путем объединения других.
Порты (port) тоже есть в Apache NiFi: они позволяет подключить потоки данных, созданные с использованием одной или нескольких групп процессов, к другим компонентам потока данных. Можно добавить любое количество входных и выходных портов в группу процессов и присвоить им соответствующие имена.
Таким образом, FBP-концепции, отраженные в Apache NiFi, позволяют использовать этот фреймворк для проектирования и обработки мощных и масштабируемых потоковых конвейеров, обеспечивая следующие преимущества:
- представление потоковых конвейеров в виде направленного ориентированного графа;
- асинхронный характер, который обеспечивает очень высокую пропускную способность и естественную буферизацию даже при колебаниях скорости обработки данных и их поступления;
- высокая степень параллелизма без ручного вмешательства разработчика;
- модульная архитектура из связных и слабосвязанных компонентов, которые затем можно повторно использовать в других контекстах;
- возможность ограничить ресурсы соединений позволяют избежать сбоев из-за разной скорости публикации и потребления данных;
- упрощенная обработка ошибок благодаря точно известным точкам входа данных в систему и их выхода, а также отслеживаемости событий их происхождения с помощью репозитория Data Provinance, о котором мы писали здесь.
Узнайте больше про администрирование и использование Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники