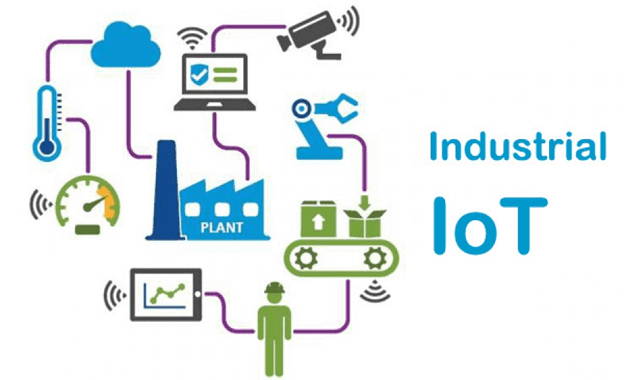
Мы уже рассказывали, как интернет вещей (Internet of Things, IoT) вместе с технологиями Big Data и машинного обучения (Machine Learning) используются в нефтегазовой, транспортной, сельскохозяйственной и машиностроительных отраслях. Сегодня поговорим подробнее про промышленный IoT (Industrial Internet of Things, IIoT) на примерах его применения в тяжелом машиностроении и рассмотрим, почему индустриальный...

Продолжая тему «умного» города (data-driven city), сегодня мы собрали для вас 5 практических примеров, как в крупнейших мегаполисах по всему миру интернет вещей и большие данные с датчиков, проездных билетов и дорожных камер помогают бороться с пробками и улучшать состояние дорог, повышая уровень их безопасности и удобства использования. Internet of...
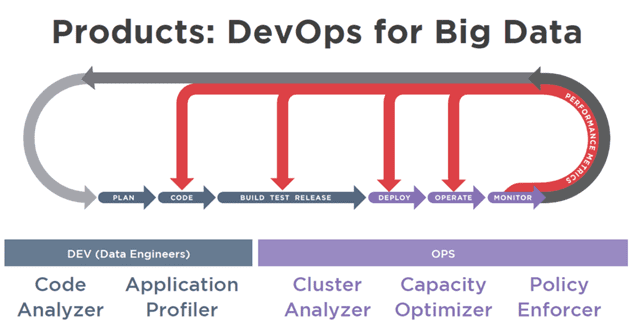
С точки зрения бизнеса DevOps (DEVelopment OPerations, девопс) можно рассматривать как углубление культуры Agile для управления процессами разработки и поставки программного обеспечения с помощью методов продуктивного командного взаимодействия и современных средств автоматизации. Сегодня мы поговорим о том, как эта методология используется в Big Data проектах, почему любой Data Scientist становится немного...

Цифровизация различных прикладных отраслей продолжается - сегодня мы нашли для вас интересные кейсы, как большие данные, машинное обучение и интернет вещей используется в жилой и коммерческой недвижимости. Чем Big Data, Machine Learning и Internet Of Things (IoT) полезны строителям и риелторам, и каким образом внедрение этих технологий поможет потребителям. Big...

Цифровизация возможна не только на предприятиях. Цифровая трансформация настигает даже города, чтобы сделать их более удобными для жителей и менее вредными для планеты. Сегодня мы подготовили для вас 8 интересных примеров по 4 разным направлениям об использовании больших данных (Big Data), машинного обучения (Machine Learning) и интернета вещей (Internet of...

Даже после очистки и нормализации данных, выборка еще не совсем готова к моделированию. Для машинного обучения (Machine Learning) нужны только те переменные, которые на самом деле влияют на итоговый результат. В этой статье мы расскажем, что такое отбор или выделение признаков (Feature Selection) и почему этот этап подготовки данных (Data...

Мы уже рассказали, что такое нормализация данных и зачем она нужна при подготовке выборки (Data Preparation) к машинному обучению (Machine Learning) и интеллектуальному анализу данных (Data Mining). Сегодня поговорим о том, как выполняется нормализация данных: читайте в нашем материале о методах и средствах преобразования признаков (Feature Transmormation) на этапе их...

Нормализация данных – это одна из операций преобразования признаков (Feature Transformation), которая выполняется при их генерации (Feature Engineering) на этапе подготовки данных (Data Preparation). В этой статье мы расскажем, почему необходимо нормализовать значения переменных перед тем, как запустить моделирование для интеллектуального анализа данных (Data Mining). Что такое нормализация данных и чем она...

Извлечение признаков (Feature Extraction) из текста – часто встречающаяся задача Data Mining, а именно этапа генерации признаков. Интеллектуальный анализ текста получил название Text Mining. В этом случае Feature Extraction относится к сфере NLP, Natural Language Processing – обработка естественного языка. Это отдельное направление искусственного интеллекта и математической лингвистики [1]. Здесь...

Генерация признаков – пожалуй, самый творческий этап подготовки данных (Data Preparation) для машинного обучения (Machine Learning). Этот этап еще называют Feature Engineering. Он наступает после того, как выборка сформирована и очистка данных завершена. В этой статье мы поговорим о том, что такое признаки, какими они бывают и как Data Scientist...