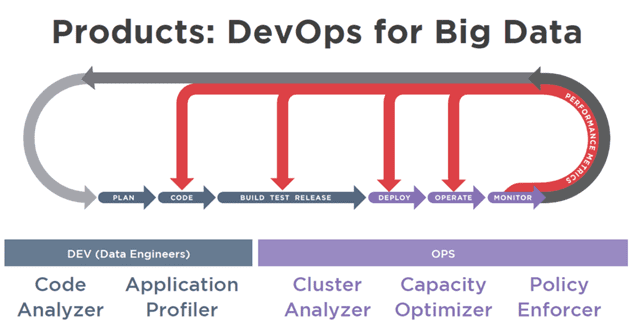
С точки зрения бизнеса DevOps (DEVelopment OPerations, девопс) можно рассматривать как углубление культуры Agile для управления процессами разработки и поставки программного обеспечения с помощью методов продуктивного командного взаимодействия и современных средств автоматизации. Сегодня мы поговорим о том, как эта методология используется в Big Data проектах, почему любой Data Scientist становится немного DevOps-инженером в больших данных и насколько это выгодно бизнесу.
Как связаны DevOps и Agile
В общем случае DevOps, как и Agile, — это набор практик для сокращения сроков выпуска конкурентоспособного программного обеспечения за счет взаимной интеграции процессов его разработки и эксплуатации путем эффективного взаимодействия профильных специалистов (аналитиков, программистов, тестировщиков, администраторов и т.д.) [1]. Этот термин стал популярным с начала 2010-х годов, в рамках развития микросервисной архитектуры, когда программный продукт строится как совокупность небольших взаимодействующих друг с другом слабосвязанных модулей. Это существенно ускоряет разработку решения, поскольку каждый модуль может автономно создаваться отдельным специалистом и интегрироваться с другими с помощью открытых API, например, REST [2]. При этом в зоне ответственности разработчика (DevOps-инженера) находятся не только процессы написания и отладки программного кода, но и вопросы его тестирования, интеграционной сборки, выпуска, развертывания, использования и эксплуатационного мониторинга [3]. Такой комплексный подход устраняет организационные барьеры между этапами создания и эксплуатации продукта, позволяя релиз за релизом быстро увеличивать его функциональность, что соответствует итерациям в методологии Agile.
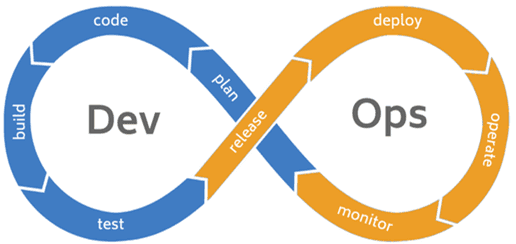
Чем занимается девопс-инженер в проектах Big Data и не только
Можно сказать, что DevOps-инженер синхронизирует все этапы создания программного продукта: от разработки кода до эксплуатации, автоматизируя задачи непрерывного тестирования, развертывания и администрирования приложения с помощью технологий контейнеризации (Kubernetes, Docker, Rocket), виртуализации (Vagrant), интеграции (Jenkins) управления инфраструктурой как кодом (Puppet) и постоянного мониторинга производительности продукта [3].
При этом навыки администрирования локальных и облачных серверов становятся особенно важными в Big Data проектах, поскольку информация хранится и обрабатывается в Hadoop-кластерах. Такой широкий круг задач предполагает высокий уровень компетентности девопс-инженера: наличие специальных знаний и профессионального опыта в процессах разработки (включая тестирование) и эксплуатации. Это соответствует Т-образной модели компетенций, которая реализуется в Agile-командах, где каждый участник обладает обширным кругозором и набором умений, являясь экспертом в одной прикладной области [4]. Таким образом, если Data Scientist обладает навыками развертывания решения в промышленную эксплуатацию (production) и администрирования экосистемы Hadoop, это не отменяет необходимость присутствия DevOps-инженера в проектной команде. Однако, существенно облегчает эффективное взаимодействие в Big Data проекте специалистов разных профилей, которых мы рассмотрим в отдельной статье.

Место DevOps-процессов в жизненном цикле Data Science
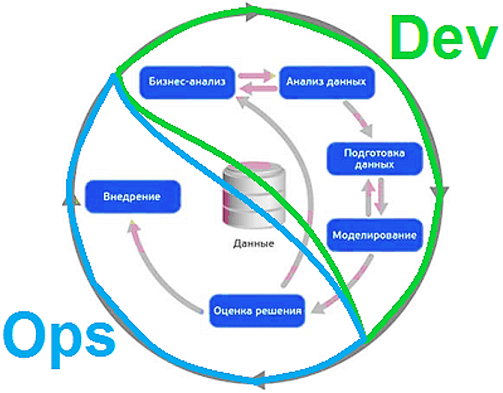
Рассматривая CRISP-DM как основной стандарт работы Data Scientist’а, можно поставить в соответствие его фазам процессы DevOps. При этом под объектами фаз оценки и мониторинга следует понимать не только разработанные модели машинного обучения (Machine Learning), а программный продукт в целом. Такое комплексное видение позволит Data Scientist’у избежать деградации разработанного решения, связанных с увеличением характера или объема обрабатываемых данных, а также изменения инфраструктуры. В результате концепция DevOps помогает Data Scientist’у фокусироваться не только на данных, а учитывать также сложность/стоимость развертывания и эксплуатации создаваемого решения. Последнее с позиции бизнеса не менее важно, чем функциональные возможности системы анализа больших данных и точность алгоритмов Machine Learning.
Распространение технологий Big Data, микросервисных архитектур, облачных платформ, а также цифровая трансформация общества провоцируют развитие принципов Agile вообще и DevOps в частности. Например, для повышения эффективности процессов использования данных и облачных сервисов/платформ появились концепции DataOps [5] и FinOps [6].
Узнайте, как внедрить лучшие практики DevOps и Agile в свои проекты цифровизации на курсах BDAM: Большие данные для руководителей в специализированном учебном центре обучения пользователей, инженеров, администраторов и аналитиков Big Data в Москве.
Источники
- https://ru.wikipedia.org/wiki/DevOps
- https://ru.wikipedia.org/wiki/Микросервисная_архитектура
- https://vc.ru/hr/51144-kto-takoy-devops-inzhener-i-chem-on-zanimaetsya
- http://agileineducation.ru/t-kompetencii-i-kompetencii-v-agile-komandax/
- https://www.osp.ru/os/2018/2/13054175
- https://www.cio.ru/articles/110419-FinOps-Optimiziruyte-oblachnye-zatraty

[…] В свою очередь, практически все элементы экосистемы Hadoop, на которой строится инфраструктура Big Data, развиваются с учетом взаимной интеграции друг с другом и сторонними продуктами. Об этом мы рассказывали в статьях о сравнении локальных дистрибутивов Hadoop и облачных решений для больших данных. Agile-команды также отличаются высоким уровнем самоорганизации: благодаря непрерывному взаимодействию, ретроспективному анализу проделанной работы и механизмам обратной связи, участники проекта быстро и эффективно решают возникшие проблемы [1]. Читайте в нашей следующей статье о развитии идей Agile в концепцию непрерывной поставки работоспособного продукта: DevOps в Big Data. […]
[…] отдельный DevOps-инженер. Задачи […]
[…] https://www.bigdataschool.ru/bigdata/devops-data-science-agile-big-data.html […]
[…] T-образная модель…, когда необходимо иметь широчайший технический кругозор, будучи экспертом в конкретной прикладной области; […]
[…] набором DevOps-процессов, который […]