 568
568 
Содержание
Извлечение признаков (Feature Extraction) из текста – часто встречающаяся задача Data Mining, а именно этапа генерации признаков. Интеллектуальный анализ текста получил название Text Mining. В этом случае Feature Extraction относится к сфере NLP, Natural Language Processing – обработка естественного языка. Это отдельное направление искусственного интеллекта и математической лингвистики [1].
Здесь с помощью машинного обучения (Machine Learning) решаются задачи распознавания и анализа текстовых данных, например, для построения чат-ботов или автоматической обработки документов, как в случае робота-юриста в Сбербанке.
Также интеллектуальный анализ текстовой информации нужен для определения тональности отзывов о компании или продукте при управлении корпоративной репутацией в интернете (Search Engine Reputation Management, SERM). Сегодня мы расскажем, что такое извлечение признаков из текста и как data scientist выполняет этот этап подготовки данных (Data Preparation).
Перед Feature Extraction: 5 NLP-операций для обработки текста
Перед тем, как запускать извлечение признаков из текста, его нужно предварительно подготовить — сделать пригодным для обработки алгоритмами машинного обучения (Machine Learning). Для этого необходимо выполнить над текстом следующие операции [2]:
- Токенизация – разбиение длинных участков текста на более мелкие (абзацы, предложения, слова). Токенизация – это самый первый этап обработки текста.
- Нормализация – приведение текста к «рафинированному» виду (единый регистр слов, отсутствие знаков пунктуации, расшифрованные сокращения, словесное написание чисел и т.д.). Это необходимо для применения унифицированных методов обработки текста. Отметим, что в случае текста термин «нормализация» означает приведение слов к единообразному виду, а не преобразование абсолютных величин к единому диапазону.
- Стеммизация – приведение слова к его корню путем устранения придатков (суффикса, приставки, окончания).
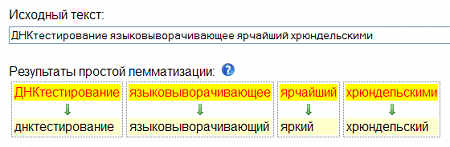
- Лемматизация – приведение слова к смысловой канонической форме слова (инфинитив для глагола, именительный падеж единственного числа — для существительных и прилагательных). Например, «зарезервированный» — «резервировать», «грибами» — «гриб», «лучший» — «хороший».
- Чистка – удаление стоп-слов, которые не несут смысловой нагрузки (артикли, междометья, союзы, предлоги и т.д.).
По завершении всех этих операций текст становится пригодным для его перевода в числовую форму, чтобы дальше продолжить извлечение признаков.
Векторизация: превращение слов в цифры
Итак, как только текст превратился в очищенную нормализованную последовательность слов, запускается процесс их векторизации – преобразования в числовые вектора [3]. Для такой трансформации используются специальные модели, наиболее популярными из которых являются:
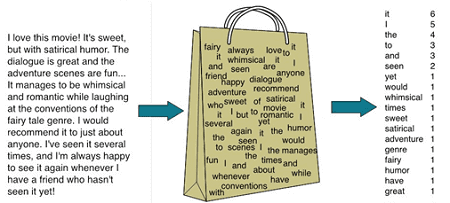
- «cумка слов» (bag of words) – детальная репрезентативная модель для упрощения обработки текстового содержания. Она не учитывает грамматику или порядок слов и нужна, главным образом, для определения количества вхождений отдельных слов в анализируемый текст [2]. На практике bag of words реализуется следующим образом: создается вектор длиной в словарь, для каждого слова считается количество вхождений в текст и это число подставляется на соответствующую позицию в векторе.Однако, при этом теряется порядок слов в тексте, а значит, после векторизации предложения, к примеру, «i have no cats» и «no, i have cats» будут идентичны, но противоположны по смыслу. Для решения этой проблемы при токенизации используются n-граммы [3].
- n-граммы — комбинации из n последовательных терминов для упрощения распознавания текстового содержание. Эта модель определяет и сохраняет смежные последовательности слов в тексте [2]. При этом можно генерировать n-граммы из букв, например, чтобы учесть сходство родственных слов или опечаток [3].
- Word2Vec — набор моделей для анализа естественных языков на основе дистрибутивной семантике и векторном представлении слов. Этот метод разработан группой исследователей Google в 2013 году. Сначала создается словарь, «обучаясь» на входных текстовых данных, а затем вычисляется векторное представление слов, основанное на контекстной близости. При этом слова, встречающиеся в тексте рядом, в векторном представлении будут иметь близкие числовые координаты. Полученные векторы-слова используются для обработки естественного языка и машинного обучения [4].
На основе этих моделей существуют и другие, более сложные, методы векторизации текстов. Практически все эти способы Text Mining реализованы в специальных средах, например, GATE, KNIME, Orange, RapidMiner, LPU, а также специальных библиотеках на языках программирования Pythone и R [5].
Еще больше интересных подробностей и прикладных знаний про Feature Extraction и другие этапы Data Preparation в нашем новом обучающем курсе для аналитиков больших данных: подготовка данных для Data Mining. Следите за новостями!
Источники

