8 апреля 2024 года вышел очередной релиз Apache AirFlow. Знакомимся с ключевыми новинками выпуска 2.9: от функций работы с наборами данных до настроек внешнего объектного хранилища в качестве бэкенда XCom-объектов и особенностей поддержки Python 3.12.
Наборы данных и гибкое планирование DAG Airflow
Выпуск 2.9 содержит более 35 интересных новых функций, более 70 улучшений и более 30 исправлений ошибок в Apache AirFlow. Одним из наиболее значимых улучшений стали расширенные параметры планирования, новые конечные точки и измененный GUI наборов данных. Напомним, наборы данных были впервые введены в версии 2.4 для замены логической группировки данных, позволяя реализовать планирование ETL-конвейеров на основе данных. Датасеты позволяют создавать меньшие по размеру DAG вместо больших монолитных конвейеров, обеспечивая их управляемость и прозрачность даже при совместно используемых данных.
В новом релизе AirFlow теперь можно использовать условные выражения помимо логического оператора AND. Хотя раньше тоже можно было предоставить список наборов данных для расписания DAG, но запускался только после обновления каждого набора данных. Это подходит не для всех сценариев. Например, если DAG обрабатывает данные, поступающие из нескольких разных источников, его надо выполнять каждый раз при возникновении в них новых данных. Для этого в расписании требуется логика запуска OR, которая ранее не была доступна. Теперь можно использовать операторы AND и OR, чтобы указать сложные зависимости набора данных для расписания DAG. Например, следующий DAG будет запускаться каждый раз, когда обновляется один набор данных в каждой категории. При этом надо указывать круглые скобки () вместо квадратных [], чтобы использовать условное планирование набора данных:
@dag(
start_date=datetime(2024, 4, 1),
schedule=(
(Dataset("categoryA_dataset1") | Dataset("categoryA_dataset2"))
& (Dataset("categoryB_dataset3") | Dataset("categoryB_dataset4"))
),
)
Также теперь можно планировать DAG, используя комбинацию наборов данных и времени. Это полезно, чтобы запускать DAG с минимальными периодическими интервалами, а также при обновлении одного или нескольких наборов данных. Чтобы реализовать этот тип расписания, надо использовать новое расписание DatasetOrTimeSchedule, передав ему выражение cron и выражение набора данных:
@dag(
start_date=datetime(2024, 3, 1),
schedule=DatasetOrTimeSchedule(
timetable=CronTriggerTimetable("*/2 * * * *", timezone="UTC"),
datasets=(Dataset("dataset3") | Dataset("dataset4")),
),
)
Для улучшения пользовательского опыта работы с наборами данных в Apache AirFlow 2.9 также добавлены две новые конечные точки для управления событиями датасета. Одна из них позволяет создавать события набора данных извне, помечая датасет как обновленный без выполнения производственной задачи. Обновление может быть получено из DAG в другом развертывании Airflow или внешней системы. Это можно использовать как способ реализации зависимостей DAG между разными развертываниями фреймворка. Обратиться к конечной точке можно программно по HTTP или в GUI для ручного обновления. Вторая новая конечная точка позволяет очистить события набора данных из очереди, чтобы сбросить обновления датасета. Это полезно в сценариях, когда DAG имеет несколько исходящих наборов данных, работающих в разное время, и нужно время на синхронизацию из-за сбоя группы данных или задачи.
Наконец, наборы данных теперь также поддерживаются объектными хранилищами, что позволяет определить путь хранения объектов и подключение к нему. Например, при размещении данных в AWS S3 это может выглядеть так:
bucket_path = ObjectStoragePath(Dataset("s3://my-bucket/"), conn_id=my_aws_conn)
Динамическое сопоставление задач и пользовательские бэкенды для XCom
Хотя динамическое сопоставление задач было реализовано еще в версии 2.3, в выпуске 2.9 эта функция стала намного лучше. Теперь она не только позволяет распараллелить операции между доступными рабочими процессами AirFlow и упрощает повторный запуск отдельных задач с представлением их результата, но и может присваивать имена сопоставленным экземплярам задач. Пользовательские названия вместо инкрементного представления Map Index позволяют сразу в GUI увидеть, какой файл сломался в экземпляре задачи, который потерпел сбой. Это особенно удобно при нескольких экземплярах одной задачи, когда они запускаются разными пользователями или для разных случаев.
Для добавления собственных названий к экземплярам сопоставленных задач нужно указать это в файле map_index_template, например:
@task(map_index_template="{{ my_mapping_variable }}")
def map_fruits(fruit_info: dict):
from airflow.operators.python import get_current_context
fruit_name = fruit_info["name"]
context = get_current_context()
context["my_mapping_variable"] = fruit_name
print(f"{fruit_name} sugar content: {fruit_info['nutritions']['sugar']}")
map_fruits.expand(fruit_info=get_fruits())
После этого в GUI AirFlow будут отображаться пользовательские названия сопоставленных экземпляров задач вместо числового значения индекса.
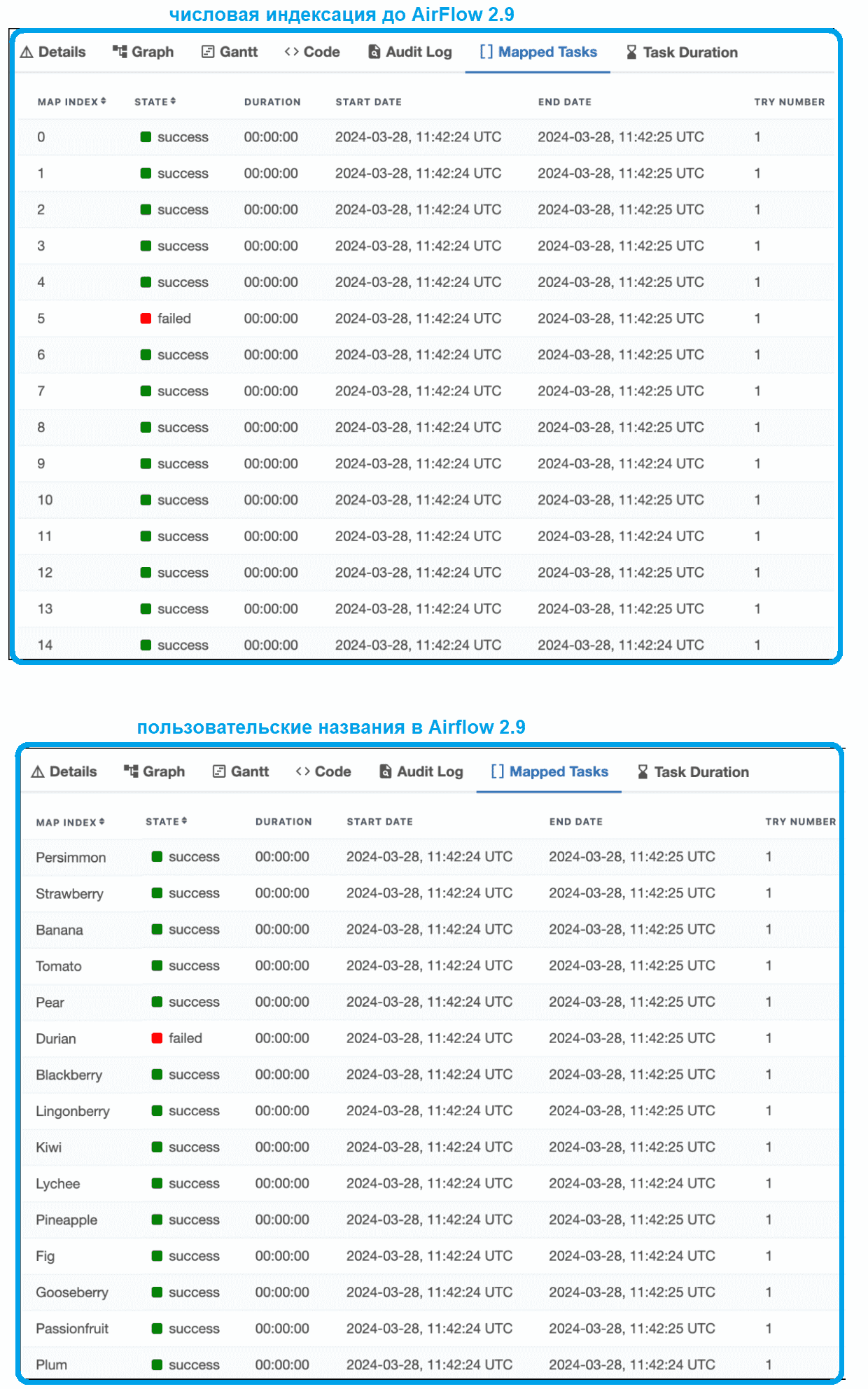
Пользовательское хранилище объектов XCom было реализовано как экспериментальная еще в прошлом выпуске Airflow 2.8. Это позволяет взаимодействовать с файлами в локальной файловой системе или облачными объектными хранилищами (AWS S3, Google Cloud Storage и Azure Blob Storage) с помощью одного и того же кода вместо использования множества операторов. В релизе 2.9 можно объектное хранилище в качестве бэкэнда для объектов XCom, обеспечивая масштабируемую и эффективную связь между задачами. За настройку бэкенда отвечает соответствующая конфигурация:
AIRFLOW__CORE__XCOM_BACKEND="airflow.providers.common.io.xcom.backend.XComObjectStoreBackend"
Это существенно расширяет границы применения простого, но достаточно эффективного, механизма обмена данными между разными задачами. Теперь можно обращаться к внешним сервисам вместо традиционного хранилище XCom на основе базы данных метаданных. Таким образом, теперь XCom потенциально можно использовать и для большого объема передаваемой информации, поскольку ее хранение не будет потреблять внутренний ресурс фреймворка. Однако, стоит помнить, что любое обращение к внешним сервисам имеет определенные накладные расходы, связанные с установкой соединения и передачей данных по сети.
Указать для хранения XCom-объектов внешнюю систему надо явно, используя следующие настройки, например, для работы с AWS S3 надо задать не только путь, но и пороговое значение в байтах, при превышении которого будет использоваться внешнее хранилище:
AIRFLOW__COMMON_IO__XCOM_OBJECTSTORAGE_PATH="s3://my_aws_conn@my-bucket/xcom" AIRFLOW__COMMON_IO__XCOM_OBJECTSTORAGE_THRESHOLD="1000"
Также можно установить поддерживаемые методы сжатия, чтобы сжимать данные перед их сохранением в объектном хранилище и более эффективно утилизировать этот ресурс:
AIRFLOW__COMMON_IO__XCOM_OBJECTSTORAGE_COMPRESSION="zip"
А вот поддержка Microsoft SQL как серверной части базы данных Airflow в версии 2.9 удалена вообще.
Для тех, кто использует MySQL в качестве бэкенда, тоже есть новости: в выпуске 2.9 тип столбца таблицы Xcom value изменился с blob на longblob. Это позволит хранить больше данных в XCom-объекте.
В заключение перечислим еще несколько интересных для дата-инженера новинок AirFlow 2.9:
- новый декоратор @task.bash для создания и запуска команд Bash с помощью TaskFlow%
- новый обратный вызов для пропущенных задач, реализованный с помощью метода on_skipped_callback();
- возможность настроить DAG на приостановку после n-го сбоя подряд с помощью параметра max_consecutive_failed_dag_runs – эта функция пока имеет экспериментальный статус;
- поддержка Python 3.12. При этом вместо Pendulum 2 надо использовать Pendulum 3, т.к. прежняя версия этого Python-пакета работы с датами не поддерживает Python 3.12. Кроме того, библиотека SQLAlchemy должна быть не старше 1.4.36 для всех версий Python. Наконец, не все провайдеры поддерживают Python 3.12, что может оказаться неприятным сюрпризом для разработчика.
О новинках выпуска 2.10 читайте в нашей новой статье.
Источники