 1508
1508 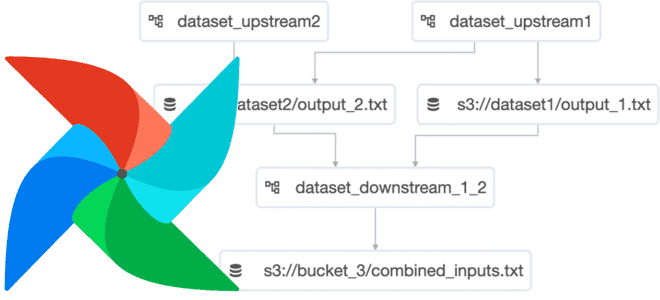
Что такое набор данных в Apache AirFlow и как эта концепция обмена данными между задачами разных DAG улучшает управляемость ETL-конвейера и повышает производительность фреймворка.
Что такое набор данных в Apache AirFlow и где это использовать
Набор данных (Dataset) – это замена логической группировки данных в Apache AirFlow. Наборы данных могут обновляться вышестоящими задачами-продюсерами, а обновления наборов данных помогают планировать следующие DAG, которые являются потребителями результатов. Эта возможность стала доступна в AirFlow версии 2.4 благодаря добавлению нового класса Dataset, который обеспечивает возможность запуска и управления различными типами зависимостей между задачами, связанными с данными. Он предоставляет унифицированный интерфейс для передачи сигналов между задачами.
Наборы данных позволяют реализовать планирование ETL-конвейеров на основе данных. Несколько DAG, которые обращаются к одним и тем же данным, теперь имеют явные, видимые связи, и их можно планировать на основе обновлений этих наборов данных. Это позволяет расширять возможности AirFlow за пределы методов, основанных на времени, таких как cron. Подробнее об этих вариантах планирования запуска DAG мы рассказываем здесь. Например, команда дата-инженеров создает набор данных, а команда аналитиков его анализирует. При использовании наборов данных аналитический DAG запустится только тогда, когда команда дата-инженеров выполнит свой DAG, т.е. опубликует набор данных.
Поскольку планирование на основе данных работает на уровне задачи, сперва надо создать экземпляр класса Dataset и связать его с конкретной задачей, которая будет являться продюсером для одной или нескольких задач-потребителей DAG. Успешный запуск задачи-продюсера автоматически запускает запуск задачи-потребителя DAG. Таким образом, DAG может состоять из множества задач, при этом только одна задача создает набор данных, от которого зависит задача-потребитель. Или DAG может содержать несколько задач-продюсеров, каждый из которых соответствует отдельной задаче-потребителю.
Запуск зависимостей, управляемых данными, на уровне задач позволяет задачам-потребителям DAG запускаться раньше, обеспечивая своевременное обновление данных, используемых для отчетов, дэшбордов, оповещений и пр. Например, одна или несколько задач-продюсеров, которые обновляют таблицы с данными в хранилище данных. Как только эти задачи запускаются и успешно завершаются, AirFlow определяет необходимость запуска задач-потребителей DAG, которые зависят от этих данных.
Поскольку наборы данных позволяют определять явные зависимости между DAG и обновлениями пользовательских данных, это дает следующие возможности для дата-инженера:
- стандартизация общения между командами — наборы данных могут выполнять роль API для связи, когда данные в определенном месте обновлены и готовы к использованию;
- сокращение объема кода, необходимого для реализации зависимостей между DAG. Даже если DAG не зависят от обновлений данных, можно создать зависимость, которая активирует DAG после того, как задача в другом конвейере обновит набор данных.
- понимание того, как DAG зависят от данных с визуализацией в пользовательском интерфейсе Apache AirFlow;
- сокращение затрат, поскольку наборы данных не используют рабочий слот в отличие от сенсоров или других реализаций зависимостей между DAG.
Познакомившись с концепций набора данных и вариантами их использования, далее рассмотрим, как это реализуется в Apache AirFlow.
Как работает класс Dataset
Объект класса Dataset представляет собой результат задачи-продюсера, например, файл JSON или CSV, столбец в таблице Apache Iceberg, таблицу или столбец в базе данных, и т.д. Такой набор данных обычно используется в качестве источника данных для одной или нескольких задач-потребителей DAG. Например, задача-потребитель может сжать несколько исходных наборов данных в CSV-файлы, которые потом будут загружены в дэшборды или BI-системы. Или задача-потребитель может извлекать данные из нескольких CSV-файлов, файлов Parquet и таблиц базы данных, чтобы создать обучающий датасет для ML-модели.
Чтобы определить набор данных, надо создать объект класса Dataset и указать строку, определяющую местоположение набора данных. Эта строка должна быть в форме допустимого универсального идентификатора ресурса (URI). В AirFlow 2.4 URI не используется для подключения к внешней системе, и не содержит информации о контенте или местоположении набора данных. Например, определить набор данных с помощью URI можно так:
from airflow.datasets import Dataset
example_dataset = Dataset("s3://dataset-bucket/example.csv")
URI рассматривается как строка, поэтому любое использование регулярных выражений (например, input_\d+.csv,) или шаблонов подстановок файлов (например, input_2023*.csv,) при попытке создать несколько наборов данных из одного объявления возникнет ошибка. Поскольку URI набора данных сохраняется в виде обычного текста, рекомендуется скрывать конфиденциальные значения с помощью переменных среды или серверной части секретов.
Существует два ограничения на URI набора данных:
- возможность использовать только символы ASCII;
- схема URI не может содержать пути AirF
При несоблюдении этих условий возникнет ошибка ValueError, и AirFlow не импортирует DAG.
Можно ссылаться на набор данных в задаче, передав его в параметр outlets, который является частью BaseOperator и доступен каждому оператору AirFlow.
После определения параметра outlets у задачи, AirFlow пометит ее как задачу продюсера, которая обновляет наборы данных. Пока задача имеет выходной набор данных, AirАlow считает ее задачей продюсера, даже если она не работает с указанным набором данных.
DAG-потребитель запускается всякий раз, когда наборы данных, для которых он запланирован, обновляются задачей продюсера, а не выполняются по расписанию на основе времени. Любой DAG, запланированный для набора данных, считается потребителем, даже если он фактически не имеет доступа к указанному набору данных. Поэтому дата-инженер, как разработчик DAG, должен правильно ссылаться на наборы данных и использовать их.
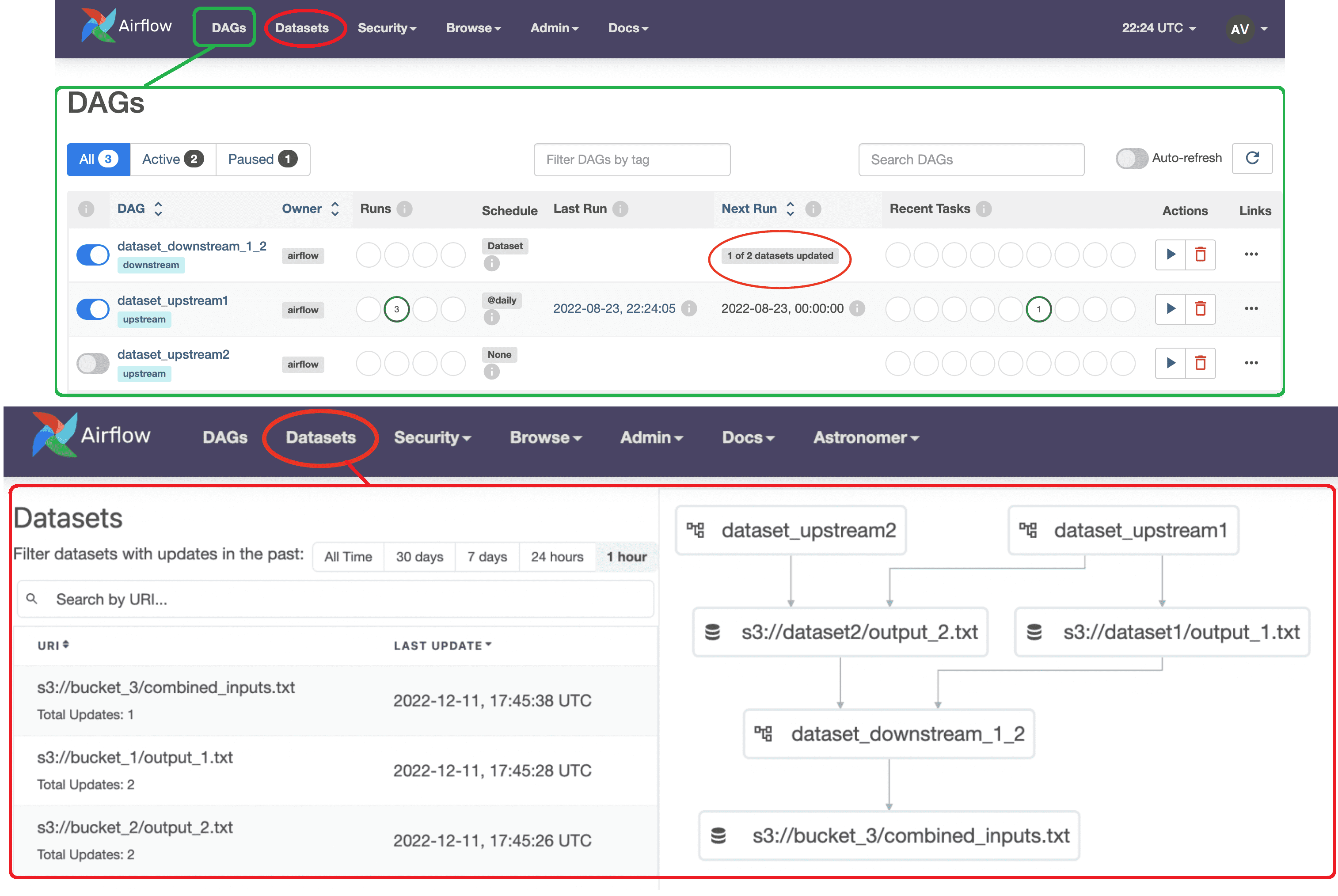
Класс Dataset поддерживается пользовательским интерфейсом Apache AirFlow, начиная с версии 2.4. Вкладка « Наборы данных» и представление «Зависимости DAG» в веб-GUI позволяют отслеживать наборы данных и зависимости данных в расписании DAG. Например, следующий рисунок показывает, что в представлении DAG конвейер dataset_downstream_1_2 запланирован для двух наборов данных продюсеров (dataset_upstream1 и dataset_upstream2), а ее следующий запуск ожидает обновления одного набора данных. На данный момент DAG под названием dataset_upstream запустил и обновил свой набор данных, а DAG dataset_upstream2— нет.
На вкладке «Наборы данных» отображается список всех наборов данных в среде AirАlow и граф, показывающий, как связаны DAG и наборы данных. Можно фильтровать списки наборов данных по последним обновлениям.
В заключение еще раз подчеркнем, что DAG, запускаемые наборами данных, не имеют понятия интервала и не зависят от времени. Если нужна информация о событии-триггере в нижестоящем DAG, можно использовать параметр контекста triggering_dataset_events. Этот параметр предоставляет список всех запускающих событий набора данных с параметрами [timestamp, source_dag_id, source_task_id, source_run_id, source_map_index ]. Смотрите практический пример работы с датасетами в этом материале, а о новых функциях работы с наборами данных, доступных в релизе 2.8, читайте в нашей новой статье.
Освойте Apache AirFlow и его применение в дата-инженерии и аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Data Pipeline на Apache AirFlow и Apache Hadoop
- AIRFLOW с использованием Yandex Managed Service for Apache Airflow™
Источники

