 1385
1385 
Содержание
Impala – это массив-параллельный механизм интерактивного выполнения SQL-запросов к данным, хранящимся в Apache Hadoop (HDFS и HBase), написанный на языке С++ и распространяющийся по лицензии Apache 2.0. Также Импала называют MPP-движком (Massively Parallel Processing), распределенной СУБД и даже базой данных стека SQL-on-Hadoop.
Как появился Apache Impala и чем это связано с Cloudera: история разработки
Изначально рассматриваемый продукт был разработан компанией Cloudera и представлен на рынок в 2012 году, а 2 декабря 2015 года был принят в инкубатор фонда Apache Software Foundation. Поэтому сегодня Apache Импала обычно означает свободно распространяемое решение, а Cloudera Impala – коммерчески поддерживаемую версию от исходной компании-разработчика (Cloudera) [1].
Разумеется, Импала – это не единственное решение класса SQL-on-Hadoop. Помимо рассматриваемого продукта, такими аналитическими средствами для Big Data являются другие проекты Apache: Hive (Хайв), Drill, Phoenix. Потребность в разработке инструментов SQL-on-Hadoop возникла из-за необходимости аналитики больших данных, хранящихся в HDFS и HBase. Например, в рамках BI-приложений (Business Intelligence), когда требуется быстро ответить на сложный логический запрос, например, при поиске оптимального авиамаршрута или другой подобной задачи с непростой логистикой [2]. Благодаря автоматической трансляции запроса в исполнительный код, реализованной внутри средства SQL-on-Hadoop, разработчик Big Data системы может работать с данными, хранящимися в HBase или HDFS, как с реляционными таблицами, формируя различные выборки и условные фильтрации, а также изменяя значение данных.
Как устроена Impala: архитектура
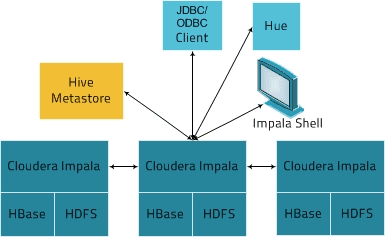
Impala работает в распределенном режиме, когда экземпляры процессов выполняются на разных узлах кластера, получая, планируя и координируя запросы от клиентов. При этом возможно параллельное выполнение фрагментов SQL-запроса. Клиенты – это пользователи и приложения, которые отправляют SQL-запросы к данным, хранящимся в Apache Hadoop (HBase и HDFS) или Amazon S3. Взаимодействие с Импала происходит через веб-интерфейс HUE (Hadoop User Experience), ODBC, JDBC и оболочку командной строки Impala Shell.
Импала инфраструктурно зависит от другого популярного SQL-on-Hadoop инструмента, Apache Hive, используя его хранилище метаданных. В частности, Hive Metastore позволяет Impala знать о доступности и структуре баз данных. При создании, изменении и удалении объектов схемы или загрузке данных в таблицы через SQL-инструкции, соответствующие изменения метаданных автоматически передаются всем узлам Impala с помощью специализированной службы каталогов [3].
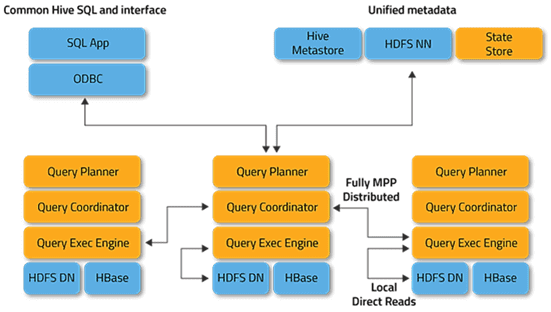
Ключевыми компонентами Импала являются следующие исполняемые файлы [3]:
- Impalad (Impala daemon) – системная служба, которая планирует и выполняет запросы к данным HDFS, HBase и Amazon S3. Один процесс impalad работает на каждом узле кластера.
- Statestored – служба имен, которая отслеживает местоположение и статус всех impalad экземпляров в кластере. Один экземпляр этого системного сервиса работает на каждом узле, а также на главном сервере (Name Node).
- Catalogd – служба координации метаданных, которая передает изменения от операторов Impala DDL и DML всем затронутым узлам Impala, чтобы новые таблицы или недавно загруженные данные сразу отображались для любого узла кластера. Рекомендуется, чтобы один экземпляр Catalogd был запущен на том же хосте кластера, что и Statestored daemon.
Как работает Импала: главные принципы выполнения SQL-запросов к Hadoop
Cloudera Impala, как и Apache Hive вместо SQL использует аналогичный декларативный язык запросов Hive Query Language (HiveQL), который является подмножеством SQL92. Он немного отличается от стандартного SQL, о чем мы подробно рассказывали здесь.
Само выполнение запроса в Импала происходит следующим образом [3]:
- Клиентское приложение отправляет SQL-запрос, подключаясь к любому impalad через стандартизированные интерфейсы драйверов ODBC или JDBC. Подключенный impalad становится координатором текущего запроса.
- Выполняется анализ SQL-запроса для определения задач для impalad-экземпляров в кластере, далее строится оптимальный план выполнения запроса.
- Impalad напрямую обращается к HDFS и HBase с помощью локальных экземпляров системных сервисов для предоставления данных. Такое непосредственное взаимодействие существенно экономит время выполнения запроса, как отсутствие сохранения промежуточных результатов, в отличие от Apache Hive.
- В ответ каждый daemon возвращает данные координирущему impalad, который далее отправляет результаты клиенту.
Благодаря MPP-механизму параллельного распределения запросов, кэшированию часто запрашиваемых данных в памяти, предварительному запуску системных служб (при загрузке) и генерации программного кода во время исполнения (runtime), а не при компиляции (compile time), Импала работает быстрее надежной и отказоустойчивой Hive. Подробнее про исполнение SQL-запросов в Apache Hive и Cloudera Impala читайте в нашей отдельной статье.
Примеры использования, ключевые преимущества и главные недостатки Impala
Вышеописанные архитектурные особенности обусловливают следующие преимущества Импала:
- высокая скорость работы, практически в режиме реального времени, в т.ч. в многопользовательской среде с высокой конкуренцией запросов. Особенная эффективность отмечается при обработке множества запросов с относительно простой логикой [4].
- встроенная поддержка безопасного сетевого протокола аутентификации Kerberos;
- приоритезация и возможность управления очередью запросов;
- поддержка популярных Big Data форматов (LZO, Avro, RCFile, Parquet, Sequence).
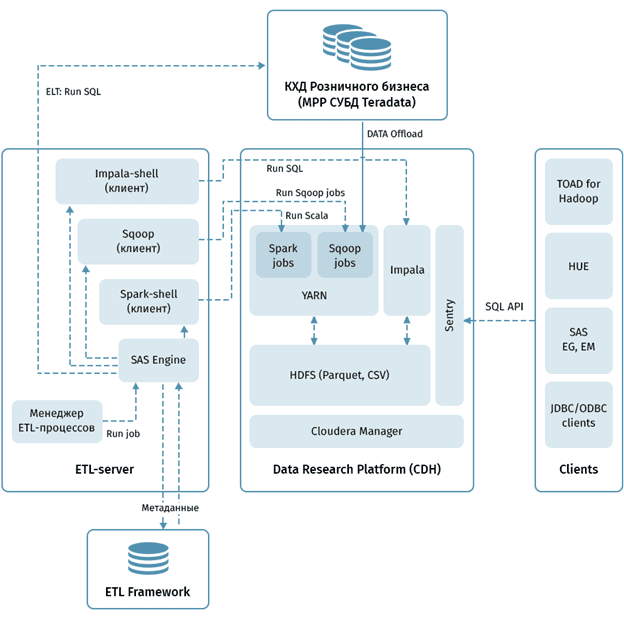
Обратной стороной всех этих достоинств Импала является снижение надежности, отказоустойчивости и пропускной способности по сравнению c Apache Hive. Также, в отличие от Hive, Импала не поддерживает сложные типы данных (map, list и struct) [5]. Несмотря на эти недостатки, Cloudera Impala активно используется в различных Big Data проектах по всему миру. Благодаря своей быстроте, эта система востребована не только у аналитиков и инженеров по данным, но и в крупных production-решениях. Например, здесь мы рассказывали, как банк ВТБ использует Cloudera Impala в качестве дополнительного ETL-инструмента для собственной Big Data системы клиентской аналитики, работающей с корпоративным хранилищем и озером данных (Data Lake).
Источники
- https://www.cloudera.com/products/open-source/apache-hadoop/impala/
- https://www.dezyre.com/hadoop-tutorial/impala-case-study-flight-data-analysis
- https://ru.bmstu.wiki/Apache_Impala
- https://data-flair.training/blog/impala-vs-hive/
- https://www.educba.com/hive-vs-impala/