
Продолжая опровергать мифы о Hadoop, сегодня мы расскажем о том, как и где создать облачный кластер для Big Data и почему это выгодно. Концепция облачных вычислений стала популярна с 2006 года благодаря компании Amazon и постепенно распространилась на использование внешних платформ и инфраструктуры как сервисов (Platform as a Service, PaaS, и Infrastructure as a Service, IaaS) [1]. Теперь совсем не обязательно разворачивать мощный компьютерный кластер у себя на предприятии – гораздо удобнее, быстрее и дешевле обойдется аренда вычислительных мощностей и дискового пространства в специализированных центрах обработки данных (ЦОД), что весьма актуально для проектов Big Data.
В этом материале мы собрали для вас общие достоинства и недостатки популярных облачных решений для Big Data на основе Hadoop от самых крупных PaaS-провайдеров: Amazon, Microsoft, IBM, SAP, Google, Яндекс, Mail.ru. А их детальное их сравнение по составу и стоимости читайте в нашей отдельной статье.
Самые крупные облачные провайдеры и их решения для кластера Big Data
Лидерами среди PaaS/IaaS-провайдеров считаются компании Amazon, Microsoft, Google, IBM, SAP и Oracle [2]. На отечественном рынке к ним примкнули российские ИТ-гиганты Яндекс и Mail.ru. Для развертывания облачного Hadoop-кластера эти корпорации предлагают следующие свои решения по большим данным:
- Amazon EMR от Amazon;
- HDInsight от Microsoft Azure;
- InfoSphere BigInsights и Analytics Engine от IBM;
- Dataproc от Google Cloud Platform;
- SAP Cloud Platform Big Data Services от SAP
- MCS от Mail.Ru Cloud Solutions
- Yandex Data Proc от Яндекс.Облако.
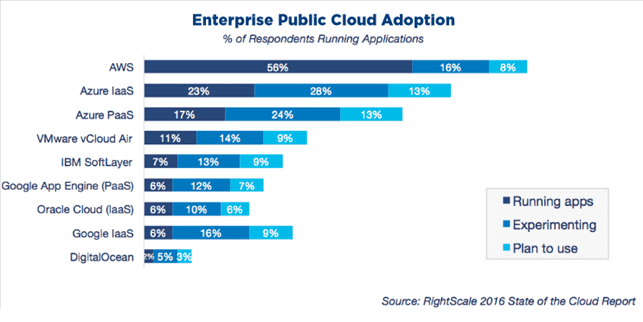
Общие достоинства облачных Hadoop-сервисов
- Готовое решение, которое включает не только дистрибутив Hadoop с набором инструментов для поставленных задач (потоковая обработка данных, машинное обучение, распознавание речи и т.д.), но и различные варианты аппаратных конфигураций с возможностью их индивидуальной настройки.
- Быстрый запуск: благодаря наличию готовых экосистем, а также типизированной процедуре создания и настройки кластера через веб-интерфейс, весь процесс развертывания инфраструктуры для проектов Big Data займет не более пары дней без привлечения дорогостоящих консультантов и DevOps-инженеров [3].
- Экономия офисного пространства и расходов на специалистов: удаленная ИТ-инфраструктура не требует выделения квадратных метров под сервера, а наличие подробной документации и круглосуточной техподдержки избавит от затрат на привлечение DevOps-инженеров и администраторов больших данных.
- Бесшовная интеграция с другими сервисами и службами: каждый PaaS-провайдер, в первую очередь, предоставляет возможность быстрого обмена данными со всей линейкой своих облачных решений, а также с аналогичными продуктами некоторых конкурентов. Например, HDInsight интегрирован с Active Directory и System Center, а также со всеми службами Microsoft Azure, BigInsights от IBM – с платформой сбора, аналитики и потоковой обработки больших данных в реальном времени InfoSphere Streams, Yandex Data Proc – со всеми сервисами и приложениями Яндекса, MCS — со всеми продуктами Mail.Ru Cloud Solutions, а Amazon EMR со всеми веб-сервисами Amazon.
- Прозрачное ценообразование: практически все PaaS-провайдеры перешли на модель оплаты за реальное потребление ресурсов (вычислительных мощностей и дискового пространства), некоторые предлагают бесплатное использование минимального кластера, который подойдет для стартапов и малого бизнеса. В частности, Amazon предоставляет начальный уровень бесплатного использования ограниченного количества своих веб-сервисов [4]. Другие провайдеры также дают возможность протестировать свои решения практически бесплатно.
- Удобство использования: веб-интерфейсы, API и командная строка для доступа к кластеру и управления им, подробная техническая документация и поддержка профессиональных инженеров и администраторов.
- Надежность и безопасность: доступность кластера и веб-сервисов по SLA (Service Level Agreement, соглашение об уровне предоставления услуги) более 99%, что означает практически бесперебойную работу кластера за счет поддержки защищенных протоколов доступа HTTPS, резервирования каналов передачи информации, шифрования SSH, изоляции данных, аутентификации и ролевых политик доступа.

Недостатки облачных инфраструктур для Big Data проектов
- Специфика российского законодательства: федеральный закон, который предписывает хранение персональных данных россиян на территории страны (ФЗ № 242-ФЗ от 21 июля 2014 г.) [5] и «пакет Яровой» (ФЗ № 374-ФЗ от 6 июля 2016 г. и № 375-ФЗ от 6 июля 2016 г.), регулирующий хранение интернет-трафика, а также средства шифрования [6]. Несоблюдение этих законов вызвало волну блокировок Роскомнадзора, от которых в 2018 году пострадали многие интернет-сервисы, в частности, Viber, Skyeng, eLama и другие сайты в подсетях серверов Amazon, Google и Microsoft Azure [7].
- Привязка к валюте и увеличение стоимости за счет роста НДС (20% от цены) для российских пользователей: например, с начала 2019 года Amazon начал взимать с российских компаний НДС (20% от цены) за свои облачные решения [7].
Этих 2-х недостатков лишены отечественные PaaS/IaaS-решения: MCS от Mail.Ru Cloud Solutions и Yandex Data Proc от Яндекс.Облако. Однако, они вышли на рынок совсем недавно и, фактически, еще находятся в стадии beta-тестирования. Поэтому говорить о них как о полноценной замене зарубежных продуктов еще пока рано.
- Завязка на продуктовую линейку одного провайдера (вендор-лог): поскольку бесшовная интеграция, в первую очередь, настроена между сервисами и службами одного поставщика, подключать сторонние решения может быть проблематично. Однако, ряд провайдеров заявляет о полной совместимости с продуктами конкурентов. В частности, MCS позиционирует себя как полностью совместимое с AWS (Amazon Web Services) решение [8]. Другие провайдеры тоже делают подобные заявления, но в реальности это не всегда подтверждается.

Сравнение по составу компонентов и стоимость облачных Hadoop-решений вы найдете в нашей следующей статье, а сведения о том, как развернуть кластер для Big Data в облаке и в локальной инфраструктуре – на наших практических курсах обучения пользователей, инженеров, администраторов и аналитиков больших данных в Москве:
- INTR: Основы Hadoop
- HADM: Администрирование кластера Hadoop
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
- BAHU: Основы Hadoop для пользователей
Источники
- https://ru.wikipedia.org/wiki/Облачные_вычисления
- http://la.by/blog/sravnenie-uslug-oblachnyh-provayderov-microsoft-azure-aws-ili-google-cloud
- https://habr.com/ru/company/mailru/blog/429154/
- https://aws.amazon.com/ru/free/
- http://www.garant.ru/news/648095/
- https://ru.wikipedia.org/wiki/Закон_Яровой
- https://habr.com/ru/post/440054/
- https://mcs.mail.ru/bigdata/

