 1385
1385 
Содержание
Мы уже делали краткий обзор некоторых исполнителей задач Apache AirFlow. Сегодня рассмотрим более подробно механизмы запуска удаленных задач и разберемся, чем Celery Executor отличается от CeleryKubernetes Executor и как они работают.
Виды и назначение исполнителей Apache AirFlow
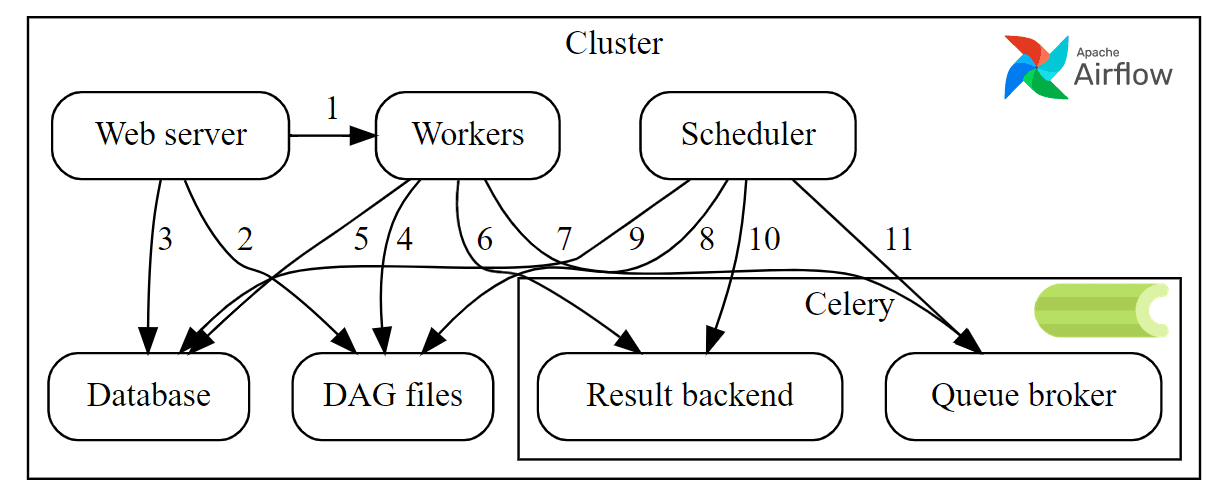
Напомним, Apache AirFlow состоит из нескольких компонентов:
- Веб-сервер, предоставляющий GUI для настройки DAG и расписания их запусков, а также мониторинга статусов;
- база метаданных (по умолчанию SQLlite 3), где хранятся глобальные переменные, настройки соединений с источниками данных, статусы выполнения экземпляров задач и запусков DAG. Для взаимодействия с этой базой метаданных используется Python-библиотека SqlAlchemy, которая выполняет ORM-сопоставления, синхронизируя объекты Python-кода с записями реляционной базы данных без использования SQL-запросов.
- планировщик (Scheduler) – сервис планирования, который отслеживает все созданные задачи и DAG, а также инициализирует экземпляры задач по мере выполнения условий для их запуска. По умолчанию раз в минуту планировщик анализирует результаты парсинга DAG, чтобы обнаружить задачи, готовые к запуску. Для выполнения активных задач планировщик использует исполнитель, указанный в настройках конфигурационного файла. Именно планировщик отвечает за добавление задач в очередь на исполнение.
- Worker – рабочий процесс, в котором выполняются задачи. В зависимости от типа исполнителя worker размещается локально или на удаленной машине.
- Исполнитель (Executor) – механизм запуска экземпляров задач, который работает вместе с планировщиком в рамках одного рабочего процесса.
Таким образом, для запуска экземпляров задач Apache AirFlow использует механизм исполнителей, которые имеют общий API и являются подключаемыми, позволяя дата-инженеру выбрать то, что больше всего подходит для конкретного случая. В один момент времени в AirFlow работает лишь один исполнитель, который задается в разделе [core] файла конфигурации, например, так:
executor = KubernetesExecutor
Все исполнители AirFlow можно разделить на 2 типа исполнителей:
- локальные, которые запускают задачи локально, т.е. внутри процесса планировщика. К ним относятся тестирощик DAGs через dag.test(), CLI-отладчик DAG, Local Executor и Sequential Executor.
- удаленные, которые запускают задачи удаленно, обычно через пул worker’ов. В эту группу входят Celery Executor, CeleryKubernetes Executor, Dask Executor, Kubernetes Executor и LocalKubernetes Executor
По умолчанию AirFlow настроен с Sequential Executor, который является локальным исполнителем и наиболее безопасным вариантом для выполнения. Однако, рекомендуется вместо него использовать Local Executor для небольших установок на одной машине или один из удаленных исполнителей для работы в режиме кластера. В любом случае, важно помнить, что логика исполнителя работает внутри процесса планировщика, при запуске которого запускается исполнитель.
Блеск и нищета исполнителя Celery
Исполнитель Celery, основанный на Python-библиотеке управления распределенной очередью заданий, позволяет AirFlow переносить выполнение задач на рабочий кластер Celery для их масштабируемой и распределенной обработки в режиме реального времени. Чтобы использовать Celery Executor, нужно иметь работающий рабочий кластер Celery и установить несколько дополнительных зависимостей:
- саму Python-библиотеку Celery, которая позволяет AirFlow взаимодействовать с рабочим кластером Celery;
- брокер сообщений, такой как RabbitMQ, или быстрая key-value NoSQL-СУБД Redis для передачи задач между AirFlow и Celery.
После установки и настройки этих зависимостей следует изменить конфигурационный файл airflow.cfg, задав значение CeleryExecutor параметру executor. Также надо настроить серверную часть Celery в файле конфигурации AirFlow. После этого задачи AirFlow будут выполняться в рабочем кластере Celery следующим образом:
- когда запланировано выполнение задачи, AirFlow отправляет ее в рабочий кластер Celery через брокер сообщений или key-value СУБД
- далее worker Celery выполняет задачу и сообщает AirFlow о ее статусе.
Одним из преимуществ использования исполнителя Celery является то, что он позволяет динамически масштабировать ресурсы в зависимости от задачи. Например, если задача требует больше ресурсов ЦП, чем есть в текущем кластере, Celery может автоматически запустить дополнительные worker’ы для обработки возросшей рабочей нагрузки.
Еще одно преимущество использования исполнителя Celery заключается в том, что он обеспечивает высокий уровень изоляции между задачами, поскольку каждая задача выполняется в своем собственном рабочем процессе Celery. Это помогает предотвратить конфликты ресурсов и повышает общую стабильность рабочих процессов Airflow.
Дополнительным плюсом Celery Executor является простота его настройки и использования, включая возможность установки Celery вместе с AirFlow на одном компьютере без дополнительной инфраструктуры. Это отлично подходит для небольших и средних рабочих процессов.
Однако, есть некоторые ограничения на использование исполнителя Celery:
- временная задержка между планированием задачи и ее фактическим запуском, т.к. задачи отправляются рабочему процессу Celery для выполнения. Эта задержка возрастает, если в очереди много задач, что чревато увеличением времени выполнения рабочих процессов.
- исполнитель Celery не обеспечивает встроенной поддержки контейнеризации. Поэтому, если рабочий процесс требует выполнения задач в контейнерах, придется настроить собственную инфраструктуру для этого.
Обойти эти ограничения можно с помощью CeleryKubernetesExecutor, который мы рассмотрим далее.
Устройство и принципы работы CeleryKubernetesExecutor
Для работы с контейнерными задачами в Apache AirFlow используется исполнитель Kubernetes, поддерживающий платформу оркестрации контейнеров с открытым исходным кодом. С исполнителем Kubernetes каждая задача запускается в отдельном контейнере в кластере Kubernetes. В отличие от исполнителя Celery, KubernetesExecutor позволяет запускать задачи на выполнение сразу же после их планирования, без какой-либо задержки. Контейнеризация обеспечивает глубокую изоляцию, поскольку каждая задача выполняется в своем собственном контейнере. Поскольку задачи выполняются в контейнерах, можно точно указать ресурсы, необходимые для каждой задачи, такие как ограничения ЦП и памяти, чтобы гарантировать бесперебойную и эффективную работу рабочего процесса.
Однако, чтобы использовать исполнитель Kubernetes, необходимо иметь настроенный кластер этой платформы контейнерной виртуализации. А, поскольку задачи выполняются в отдельных контейнерах, дата-инженер должен убедиться, что рабочий процесс поддерживает работу с контейнерами, что может потребовать дополнительной настройки. Подробнее про KubernetesExecutor мы писали здесь.
Как мы уже отметили, в один момент времени в AirFlow может работать лишь один исполнитель. Поэтому дата-инженеру приходится выбирать между исполнителем Celery и Kubernetes, что не всегда просто. Чтобы упростить этот нелегкий выбор, в AirFlow есть CeleryKubernetesExecutor, который позволяет пользователям одновременно использовать CeleryExecutor и KubernetesExecutor для запуска конкретной задачи из очереди задач. Этот исполнитель наследует масштабируемость CeleryExecutor для обработки высокой нагрузки в пиковое время и изоляцию KubernetesExecutor во время выполнения.
Поскольку CeleryKubernetesExecutor позиционируется как комбо исполнителей Celery и Kubernetes, он совмещает как их достоинства, так и недостатки. В частности, для использования этого исполнителя понадобится настроенный кластер Kubernetes. Поэтому CeleryKubernetesExecutor рекомендуется использовать в следующих случаях:
- количество задач, которые необходимо запланировать больше того, с которым может справиться кластер Kubernetes;
- относительно небольшая часть задач требует изоляции во время выполнения;
- есть множество небольших задач, которые можно выполнять в рабочих процессах Celery, и ресурсоемкие задачи, которые лучше выполнять в изолированных средах с четко ограниченными ресурсами.
Освойте все возможности Apache AirFlow для дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

