 747
747 
Содержание
При том, что Apache Airflow сегодня считается главным инструментом дата-инженерии, он далеко не единственное средство оркестрации пакетных заданий и построения конвейеров обработки больших данных. В рамках продвижения наших курсов для инженеров Big Data, сегодня рассмотрим, что такое Apache Hop, чем это отличается от AirFlow и где использовать эту платформу, а также разберем практический пример построения собственного data pipeline’а.
Что такое Apache Hop и зачем он нужен
При всей популярности Apache Airflow среди дата-инженеров, это далеко не единственное средство оркестрации Big Data заданий и построения конвейеров обработки и аналитики больших данных. В качестве альтернативных вариантов выступают Dagster, ViewFlow, Luigi, Argo, MLFlow и KubeFlow, о которых мы писали здесь. Недавно к этому набору оркестраторов присоединился Apache Hop, который впервые был представлен на конференции KCM19 еще в ноябре 2019 года, а его первый предварительный релиз доступен с 10 апреля. С 2021 года проект находится в инкубаторе фонда Apache и доступен для свободного скачивания.
Hop – это инструмент интеграции данных с открытым исходным кодом, который является ответвлением популярной BI-платформы Pentaho Data Integration (Kettle). Он позволяет создавать конвейеры обработки данных в визуальном редакторе без разработки кода. Задания конвейера могут выполняться на различных механизмах, включая собственный, а также Spark, Flink, Google Dataflow или AWS EMR через Apache Beam. Этот продукт направлен на облегчение всех аспектов оркестрации данных и метаданных.
Как и Apache AirFlow, а также прочие упомянутые оркестраторы, Hop позволяет создать data pipeline средствами визуального интерфейса, облегчая процессы разработки, тестирования, запуска и развертывания. При этом он поддерживает все современные DevOps-концепции: контроль версий, тестирование, CI/CD, документация. А строгое разделение данных и метаданных дает возможность отделить процессы обработки данных независимо от самих данных. Примечательно, что в отличие от AirFlow и Dagster, Hop не требует разработки DAG’а на Python: все настройки готовых блоков выполняются в визуальном GUI. Вся разработка сводится к написанию SQL-запросов там, где это необходимо, а парсинг JSON и CSV-файлов выполняется автоматически. Таким образом, порог входа в технологию существенно снижается, позволяя строить конвейеры обработки данных не только инженерам данных и дата-аналитикам, но и другим ИТ-специалистам с меньшей глубиной компетенций в области Big Data, например, бизнес-аналитик, администратор и пр.
Еще одним достоинством Hop является независимость от особенностей выполнения: конвейер проектируется один раз, а запускается где угодно и на любом движке (Apache Spark, Flink, Google Dataflow или AWS EMR через модель Apache Beam).
Что внутри: архитектура и принципы работы
Apache Hop состоит из следующих основных компонентов:
- Conf – инструмент командной строки для управления различными аспектами конфигурации: проектами, средами, облачной конфигурацией и пр.
- Encrypt — инструмент командной строки, который скрывает или шифрует простой текстовый пароль для использования в файлах XML, паролей или метаданных;
- GUI – визуальная IDE, где можно создавать, тестировать, запускать и управлять жизненным циклом процессов и конвейеров обработки данных. Также здесь есть функции управления проектами и средами, поиска и управления метаданными, контроля версий и просмотра журналов в графовой NoSQL-СУБД Neo4j.
- Run — инструмент командной строки для запуска рабочих процессов и конвейеров с параметрами (перечислением или) указанием проектов, сред, свойств и конфигураций запуска;
- Search — инструмент командной строки для поиска всех метаданных в конкретном проекте или среде;
- Server — интерфейс веб-службы для управления рабочими процессами и конвейерами и их выполнения, включая REST API для удаленного вызова рабочего процесса и конвейера
- Translator – инструмент с графическим интерфейсом, который позволяет нетехническим пользователям переводить Hop на свой родной язык.
Все компоненты платформы Hop являются подключаемыми, что упрощает его установку и настройку. Так в Apache Hop можно в визуальном режиме строить конвейеры преобразований и определять задания обработки данных из готовых блоков, создавая сложные ETL-заданий без разработки кода.
Подобно отложенным вычислениям (преобразованиям) в Apache Spark, в Hop можно включить «ленивую загрузку» (Lazy loading), когда все преобразования для считываемых данных будут отложены на максимально возможное время. При этом данные считываются как двоичные поля, чтобы снизить затраты ЦП на чтение данных. Однако, если преобразование данных в любом случае необходимо выполнить, отсрочка преобразования может замедлить процесс, а не ускорить его.
Но ленивое преобразование повысит скорость обработки, если данные просто считываются и без вычислений записываются в другой файл или их следует отсортировать, а они не помещаются в памяти. В этом случае сериализация на диск выполняется быстрее с ленивым преобразованием, поскольку кодирование и преобразование типов откладываются. Также lazy loading пригодится при массовой загрузке в базу данных без их изменения.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
2 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Основными концепциями Apache Hop являются следующие:
- Действие (Action) — одна операция в рабочем процессе. По умолчанию действия выполняются последовательно, с возможностью параллельного выполнения. Действие возвращает истинный или ложный код выхода, который можно использовать или игнорировать при выполнении рабочего процесса.
- Конвейер (Pipeline) из операций чтения, изменения, обогащения, очистки и записи данных. Оркестровка конвейеров осуществляется через другие конвейеры и/или рабочие процессы.
- Преобразование (Transform) — единица работы в конвейере, например, чтение данных из файла или базы данных, поиск или соединение, обогащение, очистка и пр. Все преобразования в конвейере выполняются параллельно, преобразуя данные процесса и перемещая пакеты обработанных данных для обработки последующими действиями.
- Рабочий процесс (Workflow) – последовательность операций, которые по умолчанию выполняются последовательно (с необязательным параллельным выполнением). Они обычно не работают с данными напрямую, а выполняют задачи оркестровки. Типичные задачи в рабочем процессе состоят из извлечения и архивирования данных, отправки электронных писем, обработки ошибок и пр.
Apache Hop связывает действия в рабочем процессе или преобразования в конвейере. Группа конфигураций, переменных, объектов метаданных, рабочих процессов и конвейеров объединяется в проект, который содержит одну или несколько сред, где определена фактическая конфигурация. Проекты могут наследовать метаданные родительских проектов. Среда – это экземпляр проекта с его фактическими конфигурации среды выполнения и другие объекты метаданных, например, например, для разработки, тестирования и реального использования: dev, test, prod.
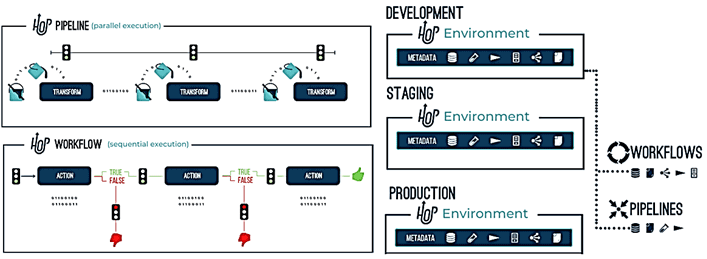
Apache Hop в действии: практический пример и отличия от AirFlow
Рассмотрим пример переноса данных о курсах валют через API и сохранение их в таблице MySQL. Возьмем RESTfull-API сервиса Open Exchange Rates и отправим запрос в его конечную точку, чтобы получить последние данных о курсе валют. После успешного запроса конечная точка отправит обратно объект JSON со следующей структурой:
{
«disclaimer»: «Usage subject to terms: https://openexchangerates.org/terms«,
«license»: «https://openexchangerates.org/license»,
«timestamp»: 1611871200,
«base»: «USD»,
«rates»: {
«AED»: 3.672995,
«AFN»: 77.503946,
«ALL»: 102.210542,
«AMD»: 519.485125,
«ANG»: 1.794941,
«AOA»: 655.668,
«ARS»: 87.146455,
«AUD»: 1.302647,
/* …. */
}
}
Этот объект JSON содержит метку времени UNIX (секунды в формате UTC), базовую валюту (трехбуквенный код ISO) и объект ставок разных валют с парами «символ: значение» относительно доллара США. Перед загрузкой данных в MySQL их следует очистить, чтобы поместить конечный результат в таблицу с тремя столбцами: Exchange_Date, Exchange_Currency и Exchange_Rate.
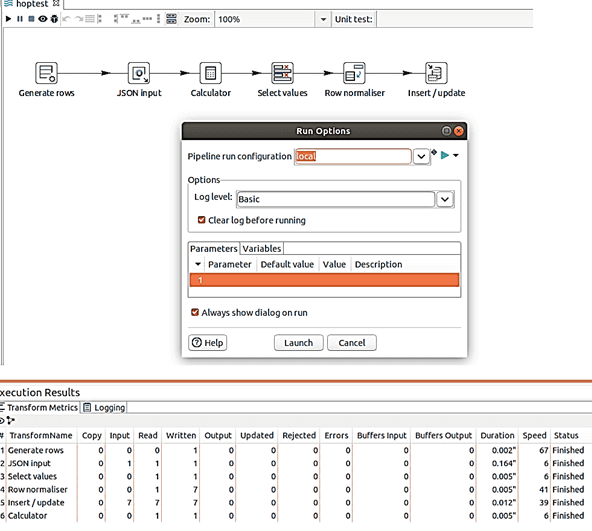
Создание конвейера в Hop GUI начинается с выбора нужных блоков.
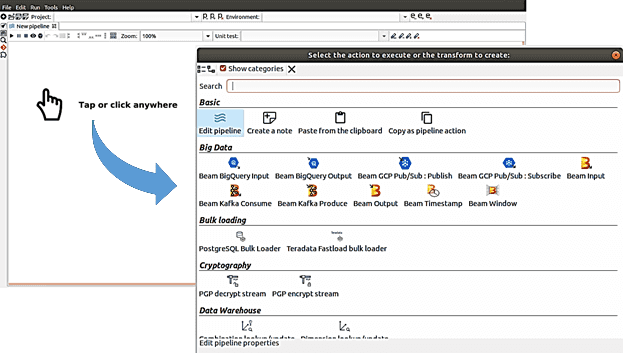
Добавим в конвейер следующие преобразования, выбрав их из готовых блоков:
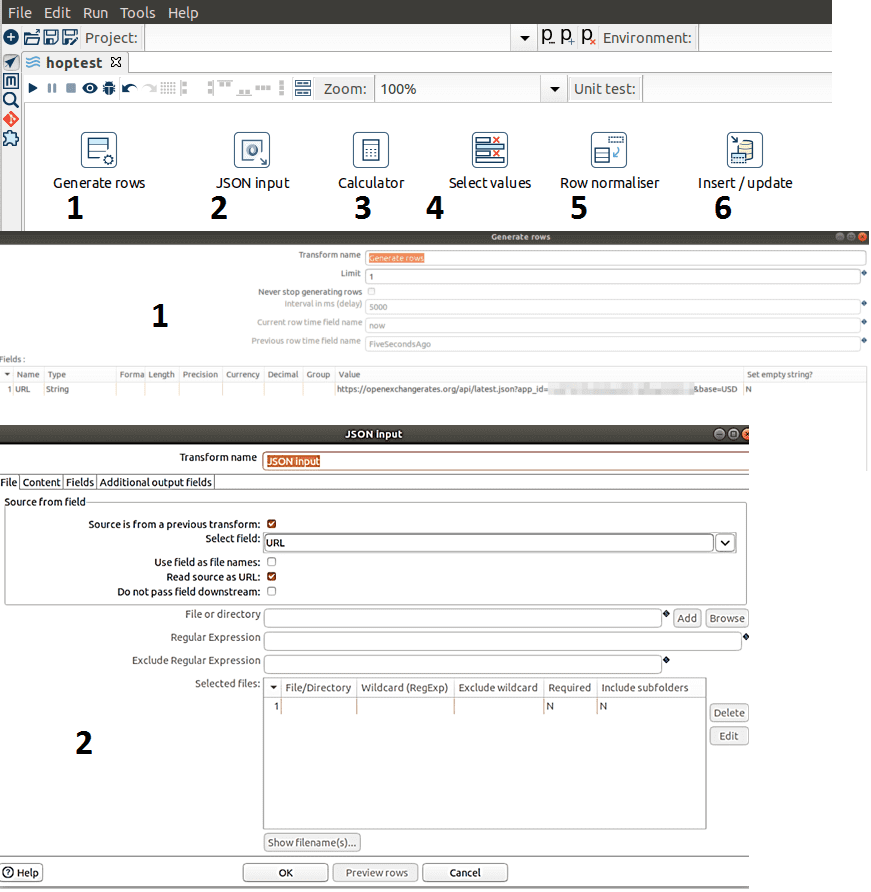
- Создание строк — генерирует указанное количество строк в качестве вывода, чтобы передать конечной точке API открытые курсы валют. Выходные данные этого шага станут входными данными для следующего преобразования;
- Ввод JSON — считывает данные из объектов JSON, файлов или входящих полей, используя выражение JSONPath для извлечения данных и выходных строк, чтобы получить данные из URL-адреса, определенного в преобразовании «Создание строк». Необходимо указать имя поля, связанное с каждым выражением JSONPath и определить тип данных.
- Калькулятор – умножение метки времени UNIX на 1000, чтобы перейти от секунд к миллисекундам и сделать дату удобочитаемой;
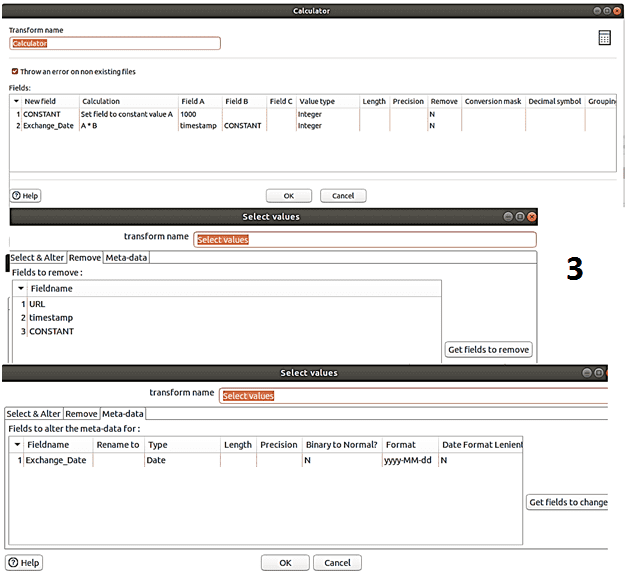
- Выбор значений – помогает выбирать, удалять, переименовывать, изменять типы данных, а также настраивать длину и точность полей в потоке. Здесь это преобразование нужно для удаления ненужных полей (URL, отметка времени и CONSTANT), созданных в предыдущих преобразованиях.
- Нормализация строк — преобразование столбцов в строки, чтобы сохранить их в таблице MySQL;
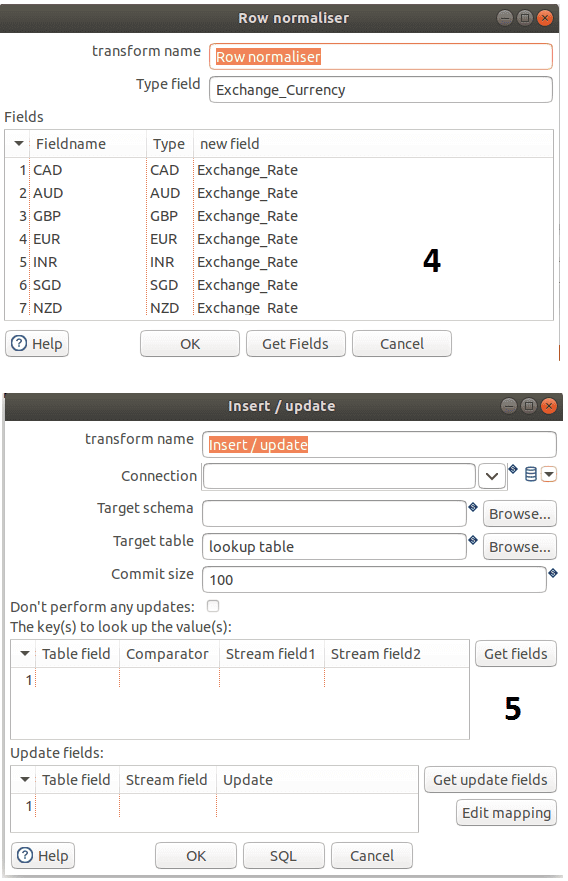
- Вставка/Обновление – непосредственная запись данных в MySQL с созданием таблицы средствами SQL-запроса, который вписывается в Hop GUI.
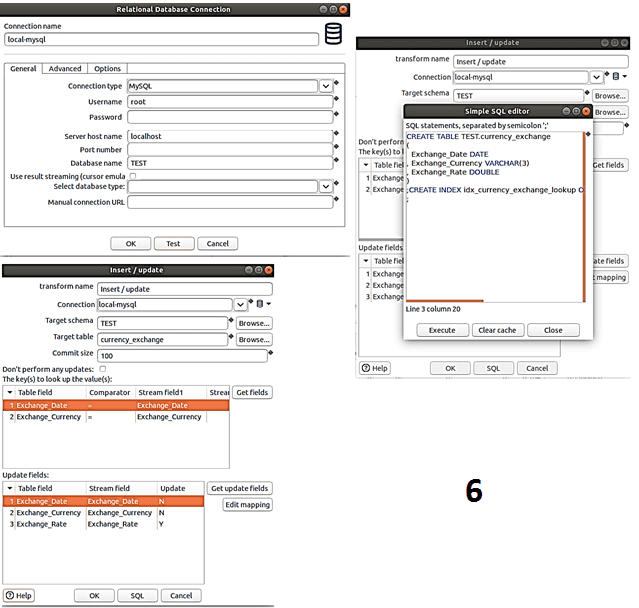
В результате всех шагов созданного конвейера получаем записи данных о курсах обмена валют в MySQL.
Подводя итог рассмотренным возможностям Apache Hop, можно сделать следующие выводы:
- удобство работы в пользовательском интерфейсе впечатляет и снижает порог входа в технологию. Можно сказать, что это отличный инструмент для изучения основ дата-инженерии и знакомства с процессами построения ETL-конвейеров.
- множество поддерживаемых источников и форматов данных позволяет охватить практически любые задачи, от OLAP до OLTP;
- платформа поддерживает не только разработку и тестирование data pipeline’ов, но и современные DevOps-идеи управления их жизненным циклом.
Однако, проект пока находится на этапе инкубации и не может похвастаться реальными внедрениями в области Big Data. Поэтому о его применении в production для настоящих бизнес-задач пока рано говорить, в отличие от зарекомендовавшего себя Apache AirFlow. Как на практике использовать Apache AirFlow для построения ETL/ELT-процессов и разработки сложных конвейеров аналитики больших данных с Hadoop и Spark вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

