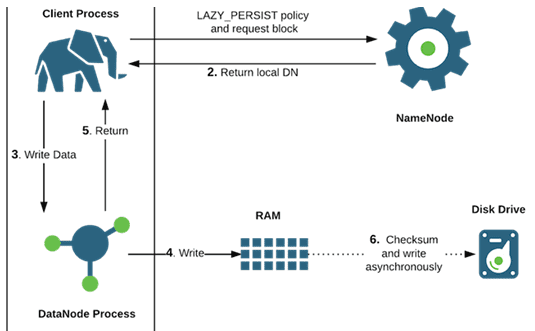
HDFS предназначена для больших данных (Big Data), поэтому размер файлов, которые хранится в ней, существенно выше чем в локальных файловых системах – более 10 GB [1]. Продолжая тему файловых операций и взаимодействия компонентов Hadoop Distributed File System, в этой статье мы расскажем, как осуществляется запись таких больших файлов с учетом блочного...

Благодаря архитектурным особенностям распределенной файловой системы Hadoop, допустимые файловые операции в ней отличаются от возможных действий с файлами на локальных системах. В этой статье мы рассмотрим файловые операции в HDFS и взаимодействие ее компонентов: узлов данных и сервера имен с клиентами - пользователями или приложениями. Файловые операции HDFS В отличие...

Сегодня мы поговорим о заблуждениях насчет базового инфраструктурного понятия хранения и обработки больших данных – экосистеме Hadoop и развеем 3 самых популярных мифа об этой технологии. А также рассмотрим применение Cloudera, Hortonworks, Arenadata, MapR и HDInsight для проектов Big Data и машинного обучения (Machine Learning). Миф №1: Hadoop – это...

Даже после очистки и нормализации данных, выборка еще не совсем готова к моделированию. Для машинного обучения (Machine Learning) нужны только те переменные, которые на самом деле влияют на итоговый результат. В этой статье мы расскажем, что такое отбор или выделение признаков (Feature Selection) и почему этот этап подготовки данных (Data...

Мы уже рассказали, что такое нормализация данных и зачем она нужна при подготовке выборки (Data Preparation) к машинному обучению (Machine Learning) и интеллектуальному анализу данных (Data Mining). Сегодня поговорим о том, как выполняется нормализация данных: читайте в нашем материале о методах и средствах преобразования признаков (Feature Transmormation) на этапе их...

Нормализация данных – это одна из операций преобразования признаков (Feature Transformation), которая выполняется при их генерации (Feature Engineering) на этапе подготовки данных (Data Preparation). В этой статье мы расскажем, почему необходимо нормализовать значения переменных перед тем, как запустить моделирование для интеллектуального анализа данных (Data Mining). Что такое нормализация данных и чем она...

Извлечение признаков (Feature Extraction) из текста – часто встречающаяся задача Data Mining, а именно этапа генерации признаков. Интеллектуальный анализ текста получил название Text Mining. В этом случае Feature Extraction относится к сфере NLP, Natural Language Processing – обработка естественного языка. Это отдельное направление искусственного интеллекта и математической лингвистики [1]. Здесь...

Генерация признаков – пожалуй, самый творческий этап подготовки данных (Data Preparation) для машинного обучения (Machine Learning). Этот этап еще называют Feature Engineering. Он наступает после того, как выборка сформирована и очистка данных завершена. В этой статье мы поговорим о том, что такое признаки, какими они бывают и как Data Scientist...

Выборка, полученная в результате первого этапа подготовки данных (Data Preparation), еще пока не пригодна для обработки алгоритмами машинного обучения, поскольку информацию необходимо очистить. Сегодня мы расскажем, что такое очистка данных (Data Cleaning) для Data Mining, зачем она нужна и как выполнять этот этап Data Preparation. Что такое очистка данных для...
Мы уже рассказывали о важности этапа подготовки данных (Data Preparation), результатом которого является обработанный набор очищенных данных, пригодных для обработки алгоритмами машинного обучения (Machine Learning). Такая выборка, называемая датасет (dataset), нужна для тренировки модели Machine Learning, чтобы обучить систему и затем использовать ее для решения реальных задач. Однако, поскольку в...