
Как найти зависший процесс в базе данных Greenplum, создать резервную копию каталога, разделить лог-файл по тестам и проверить его на наличие повреждений. Знакомимся с набором утилит gpsupport. 6 инструментов утилиты gpsupport для техподдержки Greenplum Как и любая крупная система Greenplum, помимо компонентов, обеспечивающих ее ключевые функции, также включает дополнительные инструменты,...

Как с помощью Flink SQL организовать потоковую агрегацию данных из таблицы PostgreSQL: знакомство с API таблиц в Ververica Cloud на практическом примере. API таблиц Ververica Cloud: создаем внешние источники и приемники данных Как я недавно рассказывала, немецкая фирма Ververica создала высокопроизводительный облачный сервис для обработки данных в реальном времени на...
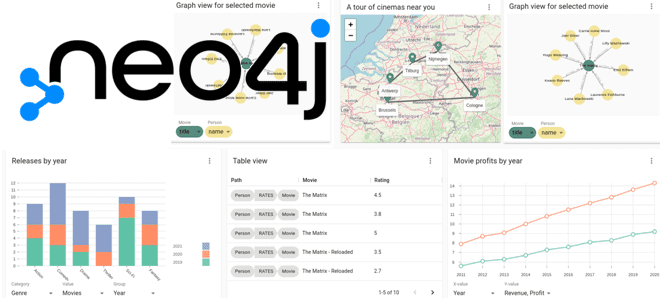
Создаем визуализации Cypher-запросов к своему графу в графовой базе данных Neo4j с помощью дэшборда NeoDash на примере анализа финансовых транзакций в банке. Python-генерация графа в Neo4j с фейковыми данными Поскольку NoSQL-СУБД Neo4j отлично подходит для задач графовой аналитики больших данных благодаря своей нативно графовой модели хранения данных, ее можно использовать...
Сегодня я покажу, как проверить доступность веб-сайта с помощью http-хука в Apache AirFlow и отправить результаты проверки в Телеграм-бот. Еще раз про хуки и соединения Apache AirFlow Доступность системы является ключевым свойством информационной безопасности. Проверить, что веб-сервис доступен, можно по статусу HTTP-ответа на GET-запрос. Чтобы делать такую проверку периодически, т.е....

Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров. Краткий ликбез по WSL и Docker для любителей Windows Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая...
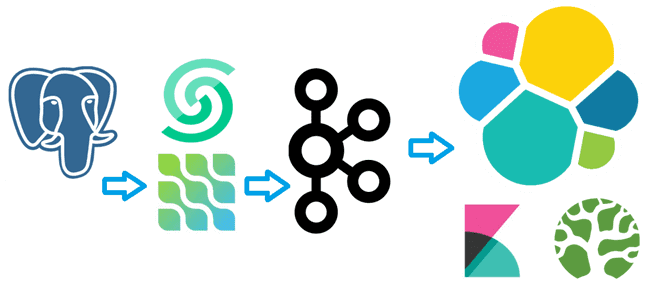
Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven. Постановка задачи и проектирование конвейера Как обычно, в...