
Чтобы добавить в наши курсы для ИТ-архитекторов и дата-инженеров еще больше практических примеров, сегодня разберем ключевые требования к современному озеру данных и самые последние тренды в аналитике Big Data. Что такое DaaS, зачем это нужно и каковы риски. 7 преимуществ развертывания Data Lake в облаке При том, что Data Lake...

Специально для обучения дата-инженеров и администраторов кластера Apache Kafka, сегодня разберем, как обеспечить безопасность клиента этой распределенной платформы потоковой передачи событий по REST API с помощью возможностей открытого ПО. Что такое PEM-файлы и при чем здесь SSL-сертификаты, а также другие криптографические средства защиты данных: кейс инженеров Expedia Group. Инструменты обеспечения...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, что такое динамическое партиционирование таблиц в Apache Spark, зачем это нужно и как реализовать такие вставки разделов. Разбираем на практическом примере. Что такое динамическое партиционирование в Apache Spark Партиционирование – это разделение данных на основе значения столбца и их сохранение...

В отличие от каменных зданий, архитектуры данных постоянно меняются. Сегодня рассмотрим новую архитектурную модель под названием BigLake, выпущенную Google весной 2022 года. Что это такое, как устроено, чем похоже на Lakehouse, озеро данных и Data Mesh, а также чем от них отличается и какую пользу несет для конвейеров аналитики Big...

Недавно мы писали, от каких факторов зависит выбор подходящего MLOps-инструмента. В продолжение этой темы сегодня специально для ML-инженеров разберем сходства и различия двух самых популярных MLOps-решений: что общего у MLflow и Kubeflow, чем они отличаются и в каких случаях выбирать тот или иной инструмент. Краткий обзор 2-х самых популярных MLOps-решений...
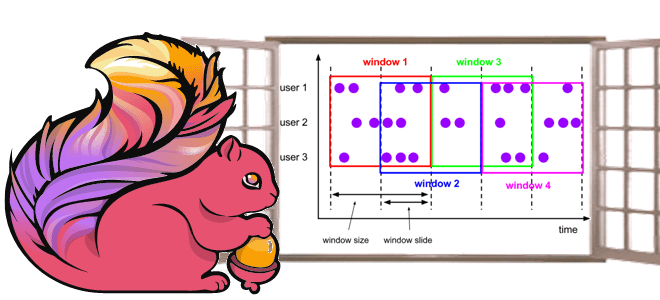
Чтобы сделать наши курсы по Apache Flink для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня рассмотрим, как этот фреймворк потоковой аналитики больших данных реализует концепцию оконных функций. Жизненный цикл окна, ключевые понятия и оконные операции Apache Flink, управляемые данными и временем. Что такое окно в потоковой обработке данных...
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем сложности рефакторинга графовых моделей в Neo4j и способы их обхода с помощью библиотеки APOC и плагина Liquibase. Что такое Liquibase и как Data Scientist и аналитик данных могут использовать его совместно с Neo4j. Гибкость модели данных и трудности...

Специально для обучения дата-инженеров и администраторов кластера тонкостям работы с современными инструментальными средствами оркестрации конвейеров обработки данных, сегодня рассмотрим, почему в Apache AirFlow уходит много времени на парсинг большого количества DAG-файлов и как этого избежать. Потери времени при парсинге множества DAG-файлов в Apache AirFlow Apache AirFlow часто используется в проектах...

Как найти компромисс между задержкой, пропускной способностью, долговечностью и доступностью в Apache Kafka: проблемы CAP-теоремы и поиски оптимальной стороны PACELC-ромба. Архитектурные ограничения распределенных систем и лучшие практики для настройки конфигурационных параметров для администратора кластера Apache Kafka и дата-инженера потоковых приложений аналитики больших данных. CAP-теорема и распределенные системы На производительность Apache...

Сегодня рассмотрим особенности использования оператора LIMIT в Spark SQL: как он выполняется и почему вместо него лучше использовать оператор TABLESAMPLE. Для этого в рамках обучения дата-инженеров, разработчиков распределенных приложений и аналитиков данных заглянем под капот оптимизатора Catalyst в Apache Spark и сравним физические планы выполнения SQL-запросов. Недостатки оператора LIMIT в...