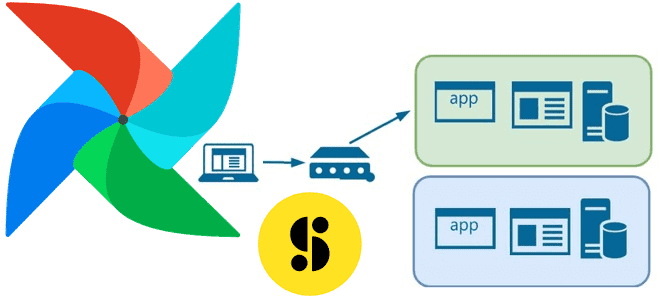
В этой статье для обучения дата-инженеров рассмотрим, как крупнейший медиа-банк Storyblocks добился обновления данных в корпоративном хранилище без простоев с помощью DevOps-идеи сине-зеленого развертывания и механизма TaskGroup в Apache Airflow. Проблемы ETL при массовой загрузке данных в Data Lake и DWH Storyblocks – это крупнейший в мире банк данных, включающий...
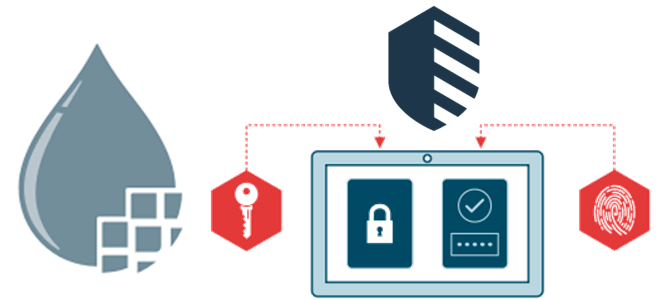
Недавно мы рассказывали, как организовать аутентификацию пользователей Apache NiFi через Okta OIDC в качестве сервиса провайдера удостоверений. Продолжая эту важную для обучения администраторов кластера и дата-инженеров тему, сегодня рассмотрим, как использовать SaaS-решение IBM Security Verify для управления доступом к пользовательскому интерфейсу Apache NiFi. Разбираемся с OpenID Connect для входа и...
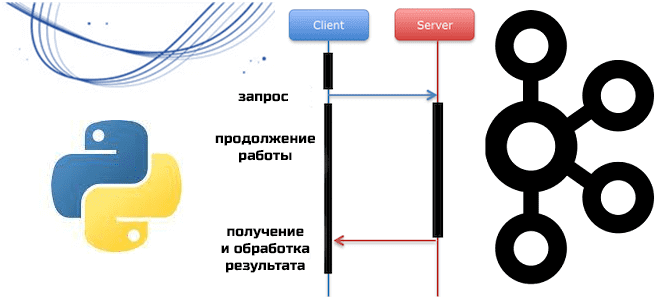
Мы уже писали о Python-клиентах Apache Kafka, которые позволяют разрабатывать приложения потоковой передачи события, используя популярный Python вместо сложных языков Java и Scala. Сегодня познакомимся с еще одной Python-библиотекой, которая представляет асинхронный клиент для Kafka. Что такое aiokafka и чем это отличается от kafka-python: краткий обзор для обучения инженеров данных...

Сегодня рассмотрим важную тему для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Как устроена потоковая обработка данных в Apache Spark Structured Streaming, зачем нужны водяные знаки и с какими сложностями при этом можно столкнуться. Как работают водяные знаки в потоковой передача событий Apache Spark Библиотека потоковой обработки событий Structured Streaming основана...

Сегодня рассмотрим тему анализа и оптимизации бизнес-процессов средствами графовой аналитики больших данных. Как устроены информационные системы класса Process Mining, где еще применяются эти идеи и другие приложения теории графов в бизнесе на примере Python-библиотеки PM4Py. Что такое Process Mining Чтобы понять, как выполняется процесс, бизнес-аналитик строит его схему в виде подробной EPC...

Data Mesh воплощает децентрализованный подход к построению распределенной архитектуры данных. При всех достоинствах этой модели, которая совмещает потоковую и пакетную парадигмы обработки данных, она еще довольно незрелая и имеет ряд недостатков. Одним из них является проблема с информационной безопасностью, что мы и рассмотрим далее для обучения ИТ-архитекторов и дата-инженеров. Безопасность...
Мы уже рассказывали про важность переносимости ML-моделей, что является одним из аспектов MLOps-концепции. Сегодня разберем, почему популярный формат Pickle не лучший выбор для сохранения модели Machine Learning и что использовать вместо него. Пара достоинств и 7 главных недостатков формата Pickle Согласно концепции MLOps, направленной на сокращение разрыва между различными специалистами,...
Недавно мы писали про устранение серьезной уязвимости PostgreSQL в свежем выпуске Greenplum 6.21.1. Продолжая тему cybersecurity, сегодня разберем другие значимые угрозы, которые были устранены в этой MPP-СУБД в 2022 и 2021 годах. Угрозы безопасности Greenplum и PostgreSQL Будучи основанной на объектно-реляционной СУБД PostgreSQL, что мы разбирали здесь, Greenplum подвержен многим...

Для практического обучения дата-инженеров и архитекторов Big Data систем сегодня рассмотрим трудности изоляции и распределения в кластере Apache HBase и способы их обхода. С какими проблемами изоляции и сбалансированного распространения данных столкнулись инженеры индийской e-commerce компании Flipkart при организации мультиарендного кластера Apache HBase и как их решили. Изоляция данных и...

В этой статье для обучения дата-инженеров и администраторов SQL-on-Hadoop рассмотрим способы обеспечения информационной безопасности и защиты данных от несанкционированного доступа в Apache Hive. Классический security-набор: аутентификация, авторизация и шифрование. Авторизация и аутентификация в Apache Hive Будучи популярным инструментом стека SQL-on-Hadoop, Apache Hive поддерживает все механизмы обеспечения информационной безопасности, поддерживаемый базовой...