Мы уже писали про важность модульного тестирования DAG Apache Airflow, а также лучшие практики и инструменты реализации этого процесса. Как протестировать структуру DAG со сложной условной логикой, сделав тест детерминированным с помощью простой сортировки идентификаторов задач, а также каким образом дата-инженеру помогут шаблоны Jinja.
Проверка структуры DAG в AirFlow
С точки зрения дата-инженера Apache Airflow можно рассматривать как планировщик задач, способный создавать сложные блок-схемы рабочих процессов в виде направленного ациклического графа (DAG, Directed Acyclic Graph), который соединяет задачи с помощью условной логики и повторных попыток. Но Python-файлы, которые определяют эти блок-схемы, также содержат бизнес-логику. Эта двойственность определения DAG и бизнес-логики представляет собой проблему тестирования кода в Apache Airflow: дата-инженеру нужно думать о структуре создаваемой блок-схемы и тестировать бизнес-логику, которую реализует каждый шаг.
Традиционный подход предполагает тестирование DAG от начала до конца, проверяя, что нужные данные загружаются из правильных источников и оказываются в нужном месте. Этот подход хорош, когда источниками и получателями являются базы данных типа PostgreSQL или плоские файлы.
Но в случае использования Airflow для загрузки данных в облачное хранилище данных типа Snowflake или AWS S3 отсутствует Docker-контейнер, который можно развернуть для тестирования конвейеров данных обычным сквозным способом. Чтобы протестировать определения DAG Airflow, не настраивая полную сквозную тестовую среду, можно отделить это от бизнес-логики, реализовав модульные тесты для структуры цепочки задач. При этом надо рассмотреть следующие вопросы:
- какова структура DAG, т.к. какие задачи связаны между собой?
- какие операторы используются для реализации каждой задачи?
- какие аргументы передаются каждому оператору, особенно если они основаны на шаблоне Jinja – быстром расширяемом механизме шаблонов. Специальные заполнители в шаблоне позволяют писать код, аналогичный синтаксису Python. Затем в шаблон передаются данные для рендеринга окончательного документа.
Чтобы проверить, правильно ли выглядит DAG, при тестировании должна быть возможность перебирать каждую задачу во всей структуре, сравнивая ее с набором ожидаемых задач. Поскольку DAG означает направленный ациклический граф, в этой структуре не может быть циклов: каждая задача гарантированно выполняется только 1 раз, начиная с корневого узла, и рекурсивно следуя связям между ним и его дочерними узлами.
В качестве примера рассмотрим DAG следующей структуры из 4-х операторов, 2 из которых являются Bash-операторами.
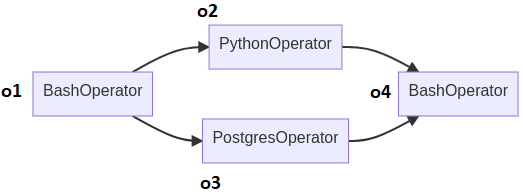
Создадим переменную dag для тестирования структуры DAG и сформулируем тестовый интерфейс с идентификаторами задач:
with DAG() as expected_dag:
o1 = BashOperator(task_id="o1")
o2 = PythonOperator(task_id="o2")
o3 = PostgresOperator(task_id="o3")
o4 = BashOperator(task_id="o4") o1 >> [o2, o3] >> o4 assert dag == expected_dag
Если рассматривать запуск узла o2 или o3 по оператору условной логики «Исключающее ИЛИ» (XOR), то надо протестировать 2 DAG, каждый из которых использует один и тот же оператор. Если o2 и o3 не имеют одного и того же оператора, тест иногда проходит, а иногда не проходит. Чтобы обойти это, можно отсортировать оба нисходящих списка перед итерацией по идентификатору задачи:
def assert_operators_match(node_a, node_b): for child_a, child_b in zip( sorted(node_a.downstream_list, key=lambda o: o.task_id), sorted(node_b.downstream_list, key=lambda o: o.task_id), ): assert_operators_match(child_a, child_b) assert type(node_a) is type(node_b)
Это делает тест детерминированным, и ожидаемые идентификаторы задач DAG могут быть назначены, чтобы гарантировать, что они сортируются в том же порядке, что и реальные идентификаторы задач DAG.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
1 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Тестирование с шаблонами Jinja
AirFlow позволяет использовать шаблоны Jinja с каждым параметром, который маркирован как шаблон (templated) в документации. Подстановка шаблона происходит непосредственно перед вызовом функции pre_execute пользовательского оператора. Можно использовать шаблоны Jinja с вложенными полями, если они помечены как шаблонные в структуре, к которой они принадлежат: поля, зарегистрированные в свойстве template_fields, будут отправлены на подстановку шаблона.
Шаблоны аргументов задачи Jinja позволяют выполнять различные действия в зависимости от диапазона дат, в котором работает конкретный запуск DAG. Например, можно запустить запрос данных из СУБД в соответствии с временным диапазоном:
BashOperator(
task_id="get_data",
bash_command="""
psql -c \
"select * from tbl \
where date >= '{{ data_interval_start }}' \
and date < '{{ data_interval_end }}'" \
> aws s3 cp - s3://my-bucket/{{ ts_nodash_with_tz }}
"""
)
Чтобы протестировать этот SQL-запрос в Airflow, можно использовать шаблоны Jinja для операторов, создав DagRun, который указывает используемые параметры. Например, если есть BaseOperator в операторе переменной, можно проанализировать его шаблонные поля, выполнив следующие действия:
dag_run = DagRun( dag_id=operator.dag.dag_id, run_id="this_is_not_important", execution_date=pendulum.datetime(2010, 1, 1, tz="UTC"), ) ti = TaskInstance(operator) ti.dag_run = dag_run ti.render_templates()
Как только это будет сделано, у оператора будут конкретизированные атрибуты. Затем можно сравнить два оператора, o1 и o2, следующим образом:
for field in set(o1.template_fields).union(set(o2.template_fields)): assert getattr(o1, field) == getattr(o2, field)
Таким образом, интерфейс тестирования DAG в рассматриваемом примет следующий вид:
with DAG() as expected_dag:
o1 = BashOperator(task_id="o1", bash_command="...")
o2 = PythonOperator(...)
o3 = PostgresOperator(...)
o4 = BashOperator(...) o1 >> [o2, o3] >> o4 assert dag == expected_dag
Код курса
ADH-AIR
Ближайшая дата курса
в любое время
Продолжительность
ак.часов
Стоимость обучения
0
Читайте в нашей новой статье про интеграционное тестирование DAG. А освоить администрирование и эксплуатацию Apache AirFlow для эффективной организации ETL/ELT-процессов в аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

