Мы уже писали про тестирование приложений Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Сегодня рассмотрим, как с помощью тестовых наборов тестировать UDF-функции, использующих состояние и таймеры.
Модульное тестирование UDF-функций Flink-приложения с помощью тестовых наборов
При работе с Apache Flink разработчики часто сталкиваются с проблемами при тестировании определяемых пользователем функций (UDF), использующих состояние и таймеры. Дополнительную сложность создают такие функции, как KeyedProcessFunction. Чтобы упростить работу с такими функциями, как мы уже упоминали здесь, Flink включает в себя специально разработанные тестовые наборы (TestHarness). Эти тестовые наборы были созданы, чтобы помочь проверить правильность встроенных операторов Flink, а также их можно использовать для тестирования UDF-функций, использующих состояние и таймеры. Используя эти наборы тестов, разработчики могут убедиться, что их пользовательские функции работают правильно и могут обрабатывать различные типы входных данных. Это позволит сэкономить время и усилия в процессе разработки и может обеспечить надежность и точность пользовательских функций.
Все тестовые наборы Flink для тестирования UDF-функций, а также пользовательских операторов делятся по следующим категориям:
- OneInputStreamOperatorTestHarness (для операторов потоков данных);
- KeyedOneInputStreamOperatorTestHarness (для операторов KeyedStreams);
- TwoInputStreamOperatorTestHarness (для операторов ConnectedStreams двух DataStreams);
- KeyedTwoInputStreamOperatorTestHarness (для операторов вConnectedStreams двух KeyedStreams);
Операторы KeyedOneInputStreamOperatorTestHarness и KeyedTwoInputStreamOperatorTestHarness создаются путем дополнительного предоставления KeySelector, включая TypeInformation для класса ключа. Таким образом, KeyedOneInputStreamOperatorTestHarness включает в себя KeyedProcessOperator, который, в свою очередь, содержит функцию KeyedProcessFunction, предназначенную для оценки.
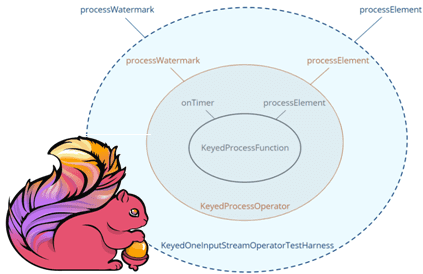
Для использования тестовых наборов операторов необходимы дополнительные зависимости. В частности, нужно добавить некоторые зависимости в проект, чтобы использовать тестовые наборы. Например, чтобы протестировать задания DataStream, необходимо добавить в блок зависимостей pom.xml проекта Maven следующий участок кода:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-test-utils</artifactId>
<version>1.18.0</version>
<scope>test</scope>
</dependency>
А для тестирования заданий Table/SQL надо добавить в блок зависимостей pom.xml для проекта Maven в дополнение к вышеупомянутым flink-test-utils еще кое-что:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-test-utils</artifactId>
<version>1.18.0</version>
<scope>test</scope>
</dependency>
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
2 декабря, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Тестирование UDF-функций с помощью оператора позволяет проверить протестировать функцию в контексте оператора и посмотреть, как она ведет себя при использовании в конвейере Flink. Поскольку Flink предоставляет наборы тестов только для операторов, разработчику придется вручную создать экземпляр соответствующего оператора, чтобы использовать эти наборы тестов. Это означает, что нужно будет создать экземпляр оператора и настроить его с необходимыми входными данными и параметрами. После этого можно использовать тестовые наборы для проверки правильности UDF-функции. На практике такой подход может оказаться более сложным, чем использование других методов тестирования, поскольку он требует ручной настройки оператора и настройки его с соответствующими входными данными. Следующий пример Java-кода показывает создание экземпляра оператора KeyedProcessOperator, который затем будет протестирован.
@Test
public void testMyProcessFunction() throws Exception {
KeyedProcessOperator<String, String, String> operator =
new KeyedProcessOperator<>(new MyKeyedProcessFunction());
// setup test harness
// push in data
// verify results
}
Чтобы протестировать пользовательскую функцию во Flink, сначала необходимо создать соответствующий тестовый набор (TestHarness). После этого можно использовать его для тестирования различных аспектов UDF-функции и оператора, в котором она используется. Например, можно проверить, что обработка элемента с оператором создает состояние и что это состояние позже очищается. Пример Java-кода для такого теста может выглядеть так:
public class MyKeyedProcessFunctionTest {
private KeyedOneInputStreamOperatorTestHarness<Long, Long, Long> testHarness;
@Before
public void setupTestHarness() throws Exception {
KeyedProcessOperator<Long, Long, Long> operator =
new KeyedProcessOperator<>(MyKeyedProcessFunction);
testHarness =
new KeyedOneInputStreamOperatorTestHarness<>(operator, e -> e.key, Types.LONG);
testHarness.open();
}
@Test
public void testingStatefulFunction() throws Exception {
assertThat(testHarness.numKeyedStateEntries(), is(0));
testHarness.setProcessingTime(0L);
testHarness.processElement(2L, 100L);
assertThat(testHarness.numKeyedStateEntries(), is(not(0)));
testHarness.setProcessingTime(3600000L);
assertThat(testHarness.numKeyedStateEntries(), is(0));
}
}
При тестировании UDF-функции Flink-приложения важно проверить все аспекты ее поведения, особенно создание и срабатывание таймеров. Для этого также пригодятся тестовые наборы. Можно создать TestHarness для отправки тестовых данных через оператора и проверки создания таймера. Затем продвинуть водяной знак (watermark) и убедиться, что таймер сработал. В дополнение к тестированию таймеров также можно проверить, что обработка элемента создает состояние, и посмотреть результаты этой обработки.
Например, срабатывание таймера для тестовой цели ожидается в течение 20 миллисекунд. В следующем примере кода показано, как протестировать его с помощью тестового набора.
@Test
public void testTimelyOperator() throws Exception {
// setup initial conditions
testHarness.processWatermark(0L);
assertThat(testHarness.numEventTimeTimers(), is(0));
// send in some data
testHarness.processElement(3L, 100L);
// verify timer
assertThat(testHarness.numEventTimeTimers(), is(1));
// advance the time to 20 in order to fire the timer.
testHarness.processWatermark(20);
assertThat(testHarness.numEventTimeTimers(), is(0));
// verify results
assertThat(testHarness.getOutput(), containsInExactlyThisOrder(3L));
assertThat(testHarness.getSideOutput(new OutputTag<>("invalidRecords")), hasSize(0))
}
Важно отметить, что тестовые наборы считаются внутренними, поэтому их API может меняться при изменении версии Apache Flink. Хотя обычно эти изменения совместимы с предыдущими версиями, возможно, потребуется внести некоторые обновления в тесты. Также с тестовыми наборами связаны еще некоторые ограничения интеграционного тестирования, которые мы разберем далее.
Интеграционное тестирование
При всей своей мощи, тестовые наборы Flink позволяют тестировать только один оператор, а не целый конвейер операторов. Это означает, что для тестирования UDF-функции, которая используется в конвейере операторов, разработчику потребуется настроить и протестировать каждый оператор отдельно.
Впрочем, для облегчения этой задачи Apache Flink предоставляет правило JUnit под названием MiniClusterWithClientResource для тестирования полных заданий на локальном встроенном мини-кластере. Для использования MiniClusterWithClientResource требуется одна дополнительная зависимость (с областью действия теста):
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-test-utils</artifactId>
<version>1.18-SNAPSHOT</version>
<scope>test</scope>
</dependency>
При выполнении интеграционного тестирования с MiniClusterWithClientResource рекомендуется применять следующие лучшие практики:
- Вместо копирования всего кода конвейера из рабочей среды в тестовую можно сделать источники и приемники подключаемыми и/или внедрить в тесты специальные тестовые источники и тестовые приемники.
- Поскольку Flink сериализует все операторы перед их распределением по кластеру для взаимодействия с операторами, созданными локальным мини-кластером Flink, можно использовать статические переменные или записать данные в файлы во временном каталоге с тестовым приемником.
- Для заданий, использующих таймеры времени события, целесообразно реализовать пользовательскую функцию параллельного источника для создания водяных знаков;
- Рекомендуется всегда тестировать конвейеры локально с параллелизмом > 1, чтобы выявить ошибки, которые проявляются только для конвейеров, выполняемых параллельно.
- Вместо декоратора @Rule рекомендуется использовать @ClassRule, чтобы несколько тестов могли использовать один и тот же кластер Flink. Это экономит много времени на запуск и завершение работы кластеров Flink.
- Если конвейер содержит пользовательскую обработку состояния, ее правильность можно проверить, включив контрольные точки и перезапустив задание в мини-кластере. Для этого нужно инициировать сбой, создав исключение из UDF-функции (только для тестирования) в пользовательском конвейере.
Таким образом, рассмотренные техники и инструменты тестирования приложений Apache Flink позволяют убедиться в его корректной работе. В заключение отметим, что важно протестировать приложение на нескольких уровнях, от модульного тестирования UDF-функций, использующих состояние и таймеры, до интеграционного и нагрузочного тестирования. Именно такой многоуровневый подход к тестированию позволит убедиться, что приложение работает должным образом и готово к запуску в производственной среде.
Узнайте больше про применение Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники