
Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...

Мы уже сравнивали MLflow и Kubeflow, которые позволяют управлять конвейерами машинного обучения. Продолжая эту важную для ML-инженера тему, сегодня рассмотрим 2 других MLOps-инструмента для оркестрации конвейеров Machine Learning: Vertex AI Pipelines и Apache AirFlow. Что такое Vertex AI Pipelines от Google Поскольку цель концепции MLOps в том, чтобы объединить разработку...
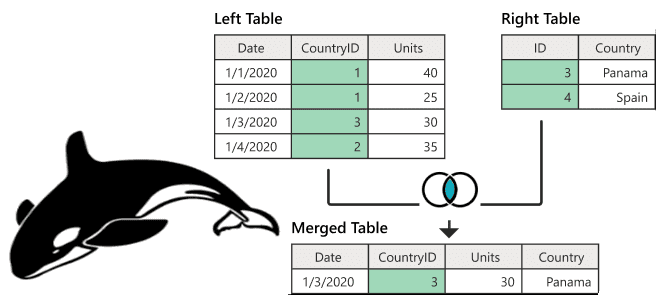
Поиск данных по нескольким таблицам в реляционных базах данных реализуется через SQL-запрос с оператором JOIN. В NoSQL-хранилищах такая возможность может отсутствовать. Разбираем, как соединить таблицы в Apache HBase и причем здесь MapReduce. Варианты реализации JOIN в Apache HBase Будучи популярной NoSQL-базой, которая реализует возможности Google BigTable для Apache Hadoop, HBase...

19 сентября 2022 года вышел очередной релиз Apache AirFlow, а через пару недель выпущены его минорные обновления. Что нового в выпуске 2.4, чем полезен новый класс Dataset, что такое наборы данных, какие триггеры позволят запускать задачи и DAG в стиле cron-соглашений, зачем убрали интеллектуальные датчики и другие важные фичи, исправления...
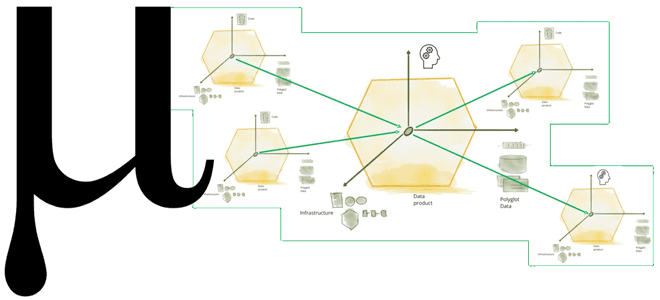
Что не так с конвейерной моделью обработки данных и почему архитектура Data Mesh с потоковой передачей событий не решают всех проблем пакетной парадигмы. Зачем нужна новая архитектура данных под названием Мю, какие инструменты и принципы она использует для устранения технологической неоднородности отдельных технологий Big Data, а также при чем здесь...

В этой статье для обучения дата-инженеров и администраторов кластера Apache Kafka разберем, какие ошибки создают медленные потребители и как решить их, просто изменив значений конфигураций по умолчанию. А также познакомимся с Lighthouse - еще одним полезным инструментом мониторинга системных метрик, который позволит обнаружить эти и другие проблемы. Проблема медленных потребителей...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...

Можно ли применять Apache Spark Structured Streaming для пакетных заданий и в каких случаях это целесообразно. Разбираемся, как устроена потоковая передача событий в Spark Structured Streaming, с какой частотой разные режимы триггеров микропакетной обработки данных запускают потоковые вычисления и что выбрать дата-инженеру. Потоковая передача событий и пакетные задания: versus или...

В рамках продвижения нашего нового курса по графовой для аналитики больших данных аналитике больших данных, сегодня познакомимся с клиентской Python-библиотекой Neo4j под названием Py2neo, которая позволяет отказаться от языка запросов Cypher. Читайте далее, что это такое, как работает и где пригодится. Python вместо Cypher в приложениях для Neo4j Манипуляции с...

Чтобы сделать наши курсы по Apache Flink еще более полезными для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных, сегодня разберем, как работают источники данных потоковой обработки на примере топиков Kafka. Источники данных в Apache Flink Наряду с Apache Spark, Flink также является популярным фреймворком пакетной и потоковой обработки...