 1156
1156 
Поиск данных по нескольким таблицам в реляционных базах данных реализуется через SQL-запрос с оператором JOIN. В NoSQL-хранилищах такая возможность может отсутствовать. Разбираем, как соединить таблицы в Apache HBase и причем здесь MapReduce.
Варианты реализации JOIN в Apache HBase
Будучи популярной NoSQL-базой, которая реализует возможности Google BigTable для Apache Hadoop, HBase поддерживает только 4 основные действия обработки данных, которые отличаются от классических SQL-запросов, о чем мы писали здесь. Тем не менее, HBase использует табличную модель хранения данных, поэтому возникает вопрос: какой запрос позволит получить данные, распределенные по нескольким таблицам? Официальная документация Apache HBase отвечает на это вопрос весьма однозначно: в том виде, как это есть в реляционных СУБД, JOIN-запросы не поддерживаются в этом NoSQL-хранилище.
Однако, это не означает фактическую невозможность реализовать соединения таблиц в Apache HBase, но это придется делать разработчику распределенного приложения самостоятельно. Сделать это можно следующими способами:
- денормализация данных при записи в HBase;
- наличие таблиц поиска и соединение таблиц HBase в приложении или в коде MapReduce. В частности, в MapReduce можно взять объект таблицы HBase, и, расширив tablemapper, использовать 2-ю таблицу, чтобы соединить их.
- использование Hive, Impala или Phoenix, которые позволяют оперировать стандартными SQL-запросами при обращении к данным, хранящимся в HDFS. Однако, применение этих или других SQL-on-Hadoop инструментов ограничено объемом соединяемых данных: если он слишком велик, может возникнуть проблема Hbase kill (region server Down).
Предположим, нужно соединить в запросе данные из таблиц A, B и C. Можно использовать методы класса TableMapReduceUtil для перебора A, а затем получать данные из B и C внутри класса TableMapper, а затем использовать TableReducer для обратной записи в таблицу Y. Этот подход работает, но если выполнить 2 случайных чтения отсканированной строки, скорость выполнения запроса резко упадет. Впрочем, если строки сильно отфильтрованы или в таблице A немного данных, падение производительности будет не заметным.
Впрочем, боде оптимальным подходом Однако лучшим подходом, который будет доступен в HBase 0.96, является метод MultipleTableInput, который просканирует таблицу A и запишет вывод с уникальным ключом, чтобы совпасть с таблицей B. Например, таблица A выдает (b_id, a_info), а таблица B выдает (b_id, b_info) в Reduce-шаге через соединение с вложенным циклом. Выполняя соединение по ключу строки или если атрибут соединения отсортирован в соответствии с таблицей B, можно иметь экземпляр сканера в каждой задаче, который последовательно читает из таблицы B, пока не найдет то, что ищет. К примеру, ключ строки таблицы A = «companyId» и ключ строки таблицы B = «companyId_employeeId». Для каждой компании в таблице A можно получить всех сотрудников, используя алгоритм вложенного цикла:
for(company in TableA):
for(employee in TableB):
if employee.company_id == company.id:
emit(company.id, employee)
А как вообще реализуется соединение в MapReduce, мы рассмотрим далее.
Соединение таблиц в MapReduce
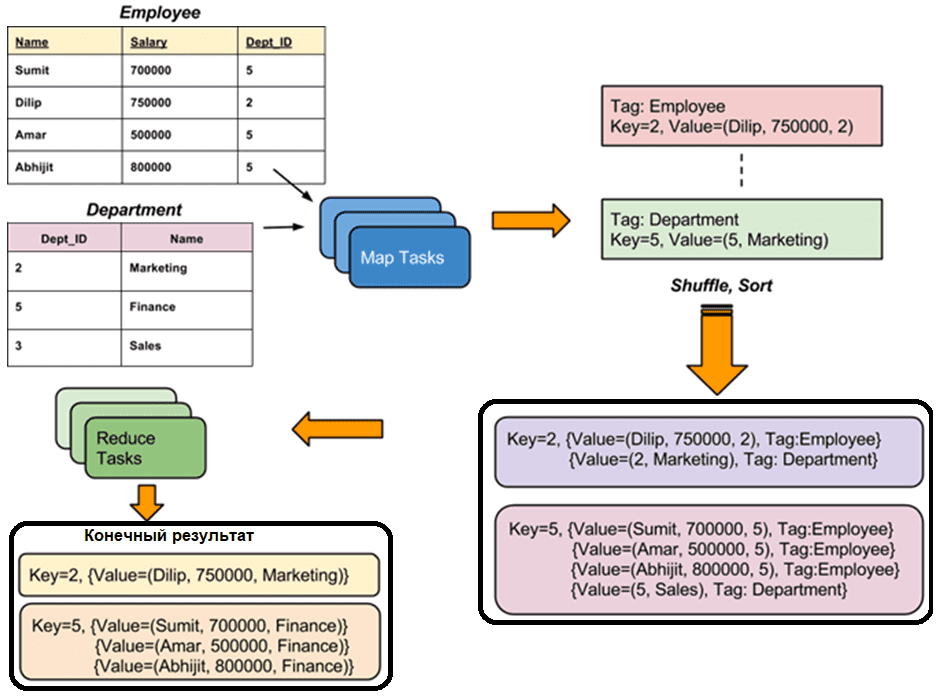
JOIN-операция MapReduce используется для cоединения двух больших наборов данных. Однако, этот процесс включает в себя написание большого количества кода для выполнения фактической операции соединения. Сперва выполняется оценивание размера каждого набора данных, чтобы сравнить их между собой. Если один набор данных немного меньше другого, меньший набор данных распространяется на каждый узел данных в кластере. Как только соединение в MapReduce распределено, Mapper или Reducer использует меньший набор данных для поиска соответствующих записей из большого набора данных, а затем объединяет эти записи для формирования выходных записей.
В зависимости от места, где выполняется фактическое соединение, соединения в Hadoop могут быть нескольких типов:
- соединение на стороне Map, которое выполняется до фактического использования данных функцией сопоставления. При этом входные данные каждого сопоставления должны быть в виде отсортированного раздела. Кроме того, для соединения необходимо равное количество разделов, которые должны быть отсортированы по ключу соединения.
- соединение на стороне Reduce, при котором нет необходимости иметь набор данных в структурированном или партицинированном виде. Здесь обработка на стороне Map выдает ключ соединения и соответствующие кортежи обеих таблиц, в результате чего все кортежи с одинаковым ключом соединения попадают в один и тот же Reducer, который затем объединяет записи с одним и тем же ключом соединения.
Больше подробностей про администрирование и эксплуатацию Apache HBase и других компонентов экосистемы Hadoop для хранения и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

