
В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах. Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data Прежде всего, отметим, что Apache HBase и Cassandra считаются...
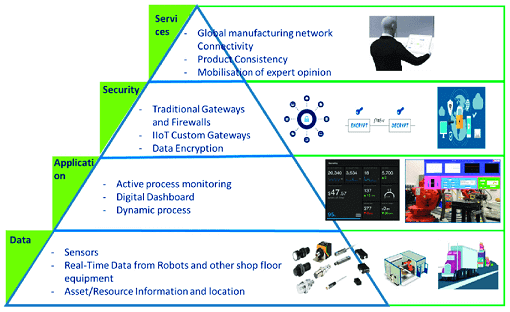
Мы уже рассматривали типовую архитектуру систем Internet of Things (IoT). Сегодня поговорим подробнее про уровневую модель передачи и обработки данных от конечных устройств до облачных IoT-платформ, а также приведем примеры наиболее популярных средств обеспечения каждого из уровней этой сложной архитектуры Industrial Internet of Things, включая инструменты Big Data. Многоуровневый IIoT:...
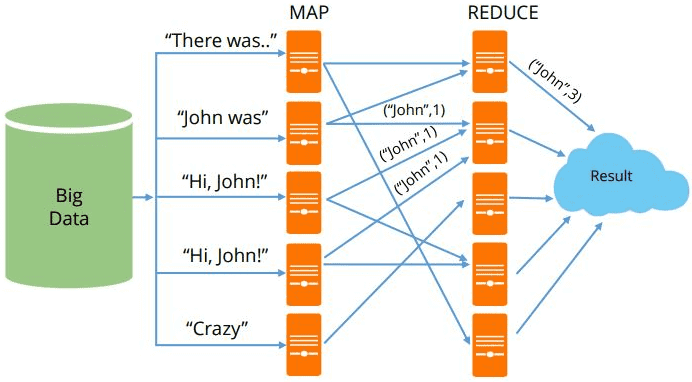
MapReduce можно назвать основой Big Data, т.к. именно данная технология позволяет обрабатывать огромные массивы информации параллельно в распределенных кластерах. Эту вычислительную модель поддерживают множество различных коммерческих и свободных продуктов: Apache Hadoop, Spark, Greenplum, Hive, MongoDB, Phoenix, DryadLINQ и прочие Big Data фреймворки и библиотеки, написанные на разных языках программирования [1]. Сегодня...

Проанализировав сходства и различия пяти самых популярных Big Data фреймворков для распределенных потоковых вычислений (Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza), в этой статье мы сравним их по 10 критериям и отметим, какие именно факторы являются наиболее значимыми для объективного выбора. Сравнительный анализ самых популярных фреймворков потоковой обработки...

В этой статье мы рассмотрим, чем похожи и чем отличаются 5 самых популярных инструментов распределенной обработки потоков Big Data: Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza, а также поговорим про наиболее значимые факторы выбора между этими программными средствами. 5 общих характеристик распределенных Big Data фреймворков потоковой обработки Прежде...

Apache Samza часто сравнивают с другими Big Data фреймворками распределенных потоковых вычислений в реальном времени (Real Time, RT): Kafka Streams, Spark Streaming, Flink и Storm. Apache Spark и Flink обладают практически одинаковым набором функциональных возможностей и компонентов, поэтому их можно сравнивать между собой более-менее объективно. Apache Samza является более простой...

Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм,...

Flink часто сравнивают с Apache Spark, другим популярным инструментом потоковой обработки данных. Оба этих распределенных отказоустойчивых фреймворка с открытым исходным кодом используются в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop [1] и других кластерных системах. В этой статье мы поговорим, чем похожи и чем отличаются Флинк и Спарк, а...

Проанализировав сходства и различия Apache Kafka Streams и Spark Streaming, можно сделать некоторые выводы относительно выбора того или иного решения в качестве основного инструмента потоковой обработки Big Data. В этой статье мы собрали для вас аргументы в пользу Кафка Стримс и Спарк Стриминг в конкретных ситуациях, а также нашли некоторые...

Сегодня мы рассмотрим популярные Big Data инструменты обработки потоковых данных: Apache Kafka Streams и Spark Streaming: чем они похожи и чем отличаются. Стоит сказать, что Спарк Стриминг и Кафка Стримс – возможно, наиболее популярные, но не единственные средства обработки информационных потоков Big Data. Для этой цели существует еще множество альтернатив,...