
Вчера мы рассказали, почему запускать Airflow на Kubernetes – это эффективно и выгодно для всех участников batch-процессов с большими данными (Big Data): разработчиков Data Flow, Data Scientist’ов, аналитиков и инженеров. Сегодня рассмотрим, что такое Airflow Kubernetes Operator и чем он отличается от подобной разработки компании Google. Как работает AirFlow Kubernetes...

Чтобы обучение Airflow было максимально приближенным к практике, сегодня мы поговорим про особенности реального внедрения этого фреймворка для разработки, планирования и мониторинга пакетных процессов обработки больших данных (Big Data) с учетом современного DevOps-подхода. Читайте в нашей статье, зачем вообще нужна связка Apache Эйрфлоу с Kubernetes и как это реализовать технически....

Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования. Чем хорош Apache AirFlow:...

Обычно курсы по Spark подробно рассказывают, чем хорош этот Big Data фреймворк для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных. Но, чтобы обучение Apache Spark было максимально полезным, стоит знать и о недостатках этого многофункционального инструмента обработки больших данных. Сегодня мы рассмотрим некоторые проблемы, которые возникают при практическом...

Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления...

Рассматривать обучение Кафка интереснее на практических примерах. Сегодня мы расскажем, как Apache Kafka применяется в одной из крупнейших промышленных компаний России - ПАО «Северсталь». Эта статья написана на основе выступления Доната Фетисова, главного архитектора «Северсталь Диджитал». Доклад был представлен 7 декабря 2019 года на очередном ИТ-митапе компании Авито по Big...

Вчера мы рассказывали, от чего зависит скорость работы Apache Kafka и как можно повысить. Сегодня рассмотрим подробнее, как именно конфигурация отправителей (производителей, producers) сообщений влияет на общую производительность этой распределенной Big Data системы потоковой агрегации событий. Что такое конфигурация производителей Apache Kafka Напомним, общая производительность Кафка зависит от следующих факторов:...

Продолжая практическое обучение Kafka, сейчас мы рассмотрим, от чего зависит производительность этой распределенной Big Data системы потоковой агрегации событий. Частично эту тему мы уже рассматривали в статье про применение Кафка в высоконагруженных проектах. Читайте в сегодняшнем материале, какие параметры влияют на скорость работы Кафка и как можно ее повысить. Как...
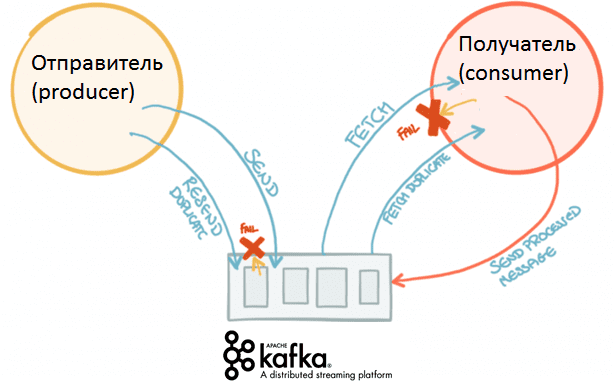
Вчера мы говорили про концепцию QaaS, очереди сообщений в Apache Kafka и другие проблемы производительности высоконагруженных систем с использованием этой Big Data платформы. Сегодня рассмотрим сложности многопоточной обработки событий в разном порядке: когда возникают подобные ситуации и как их решить. Для этого еще раз сравним Кафку с ее вечным конкурентом,...

При всех достоинствах Apache Kafka, для этого популярного Big Data средства управления сообщениями характерны определенные трудности в обеспечении производительности. Сегодня мы поговорим про некоторые проблемы использования этого распределенного брокера сообщений в высоконагруженных системах. В качестве реального примера рассмотрим особенности практического использования Кафка в отечественном сервисе объявлений Авито. Что такое высоконагруженная...