
В этой статье для обучения дата-инженеров сравним популярный ETL-оркестратор Apache AirFlow с облачным бессерверным сервисом от AWS под названием Step Functions. Оба этих решения представляют собой workflow-сервисы, которые позволяют автоматизировать бизнес-процессы и упростить процедуры дата-инженерии. Читайте далее, что между ними общего и чем они отличаются, а также какой из них...

Сегодня рассмотрим опыт международной компании Emumba, которая специализируется на инженерии и аналитике больших данных. Читайте далее, как выгодно масштабировать конвейер потоковой передачи данных от миллионов устройств интернета вещей, используя Apache Kafka, KStream и Druid в облачной инфраструктуре AWS. Архитектура PoC для потоковой передачи событий от миллионов IoT-устройств Миллионы устройств интернета...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое Nebula Graph и как использовать мощные возможности обработки графов этой NoSQL-СУБД в сочетании с Apache Spark, одним из самых популярных механизмов анализа данных. Что такое Nebula Graph и как это работает Nebula Graph — это...

Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и...

Постоянно добавляя в наши курсы для дата-инженеров и разработчиков распределенных Spark-приложений интересные примеры, сегодня мы хотим поделиться с вами простыми, но эффективными приемами, как улучшить производительность этого вычислительного движка. Чем метод take() лучше collect() в Apache Spark, какие открытые инструменты помогут выполнить профилирование кода и как быстро прочитать множество маленьких...
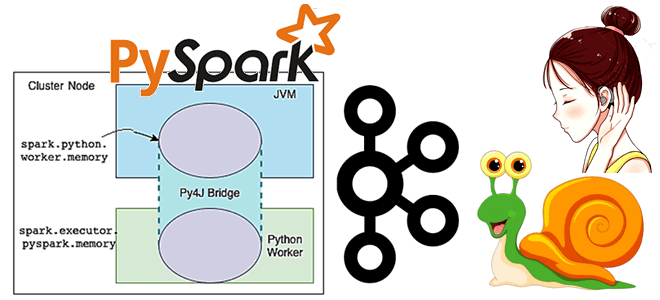
Чтобы добавить в наши курсы для дата-инженеров и разработчиков распределенных приложений еще больше практических примеров, сегодня рассмотрим, как написать Python-код для вычисления задержки потребителя Apache Kafka, расширив типовой слушатель StreamingQueryListener, который есть в Java и Scala API библиотеки Spark Structured Streaming, но недоступен в PySpark. Проблема отставания потребителя Apache Kafka...
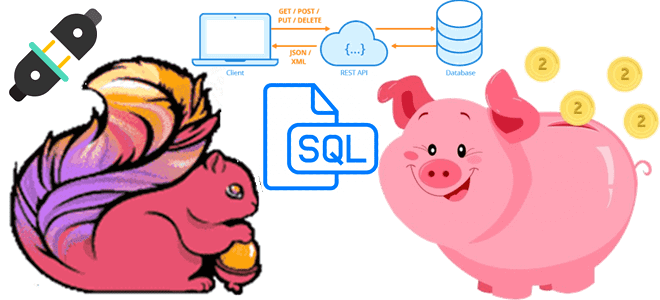
В этой статье для обучения дата-инженеров и разработчиков распределенных приложений рассмотрим, как Flink SQL может обогатить ML-модель данными из внешней системы в режиме реального времени с использованием REST API. Что представляет собой http-flink-connector с открытым исходным кодом, разработанный GetInData на основе концепции Lookup Joins. Обогащение данных c SQL: достоинства использования...
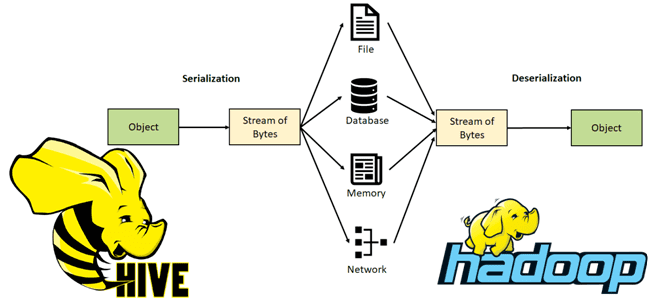
Чтобы добавить еще больше практики в наши курсы для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим тонкости сериализации данных в Apache Hive. Читайте далее, как этот популярный SQL-on-Hadoop инструмент обрабатывает данные из HDFS, что такое SerDe и как написать собственный сериализатор/десериализатор. Сериализация и десериализация данных в Apache Hive В настоящее...
Специально для обучения дата-инженеров и архитекторов DWH сегодня разберем, как построить LakeHouse на Greenplum и объектном хранилище Cloudian HyperStore, совместимом с AWS S3. Что такое Cloudian HyperStore Object Storage, как оно совмещается с Greenplum и при чем здесь Apache Cassandra с интеграционным фреймворком PXF. Что такое объектное хранилище Cloudian HyperStore...
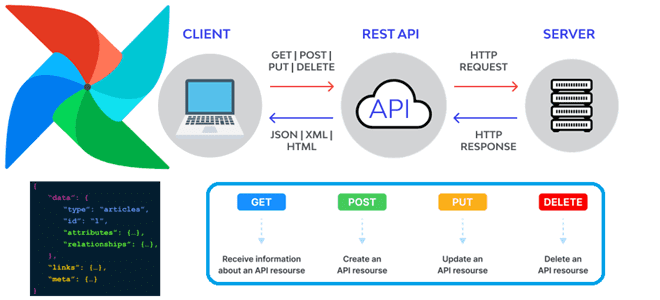
Сегодня в рамках обучения дата-инженеров рассмотрим, как программно запустить DAG в Apache AirFlow через вызовы REST API. А также повторим основы интеграционного взаимодействия ИС через отправку HTTP-запросов к конечным точкам. Как устроен REST API в Apache AirFlow Напомним, начиная с выпуска 2 Apache Airflow включает стабильный RESTfull API версии 1.0.0...