 1177
1177 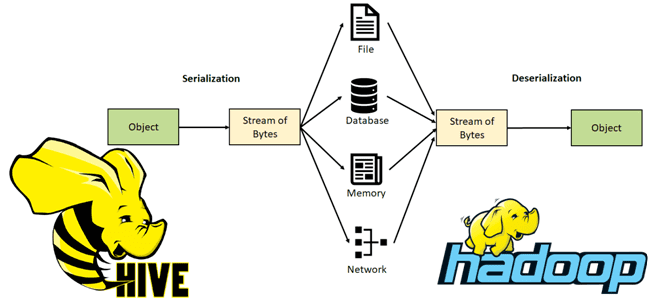
Чтобы добавить еще больше практики в наши курсы для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим тонкости сериализации данных в Apache Hive. Читайте далее, как этот популярный SQL-on-Hadoop инструмент обрабатывает данные из HDFS, что такое SerDe и как написать собственный сериализатор/десериализатор.
Сериализация и десериализация данных в Apache Hive
В настоящее время Apache Hive является очень популярным NoSQL-хранилищем. Впрочем, корректнее его отнести к стеку SQL-on-Hadoop, который позволяет обращаться к данным, хранящимся в HDFS, через ANSI-подобный язык SQL-запросов без разработки Java-кода с функциями MapReduce. При запросе таблицы SerDe десериализует строку данных из байтов файла в объекты, используемые внутри Hive для работы с этой строкой данных. Для выполнения SQL-операций INSERT или CTAS компонент SerDe сериализует внутреннее представление строки данных Hive-таблицы в байты, которые записываются в выходной файл. Напомним, процесс сериализации – это перевод структуры данных в последовательность байтов для передачи объектов по сети и для их сохранения в файлы. Обратный процесс восстановления данных из последовательности байтов и их представление согласно структуре, заданной в схеме, называется десериализацией.
В Apache Hive за сериализацию и десериализацию данных отвечает библиотека SerDe, встроенная в Hadoop API, в пакете org.apache.hadoop.hive.serde2. Сериализаторы и десериализаторы данных в этой библиотеке фреймворка позволяют пользователям разрабатывать сериализаторы и десериализаторы для собственных форматов данных. Этот компонент также содержит несколько встроенных средств сериализации и десериализации данных. Можно сказать, что SerDe сообщает Hive о том, как обрабатывать запись, т.е. строку таблицы. Hive может обрабатывать полуструктурированные записи типа XML и JSON, а также письма электронной почты, данные RSS-каналов, аудио, видео и пр. Например, для CVS-файлов с разделителями Hive использует методы публичного класса MetadataTypedColumnsetSerDe, который расширяет абстрактный класс AbstractSerDe из пакета hadoop.hive.serde2 и реализует интерфейсы Deserializer, SerDe, Serializer.
А класс LazySimpleSerDe можно использовать для чтения того же формата данных, что и MetadataTypedColumnsetSerDe и TCTLSeparatedProtocol, однако он создает объекты через отложенные вычисления, обеспечивая лучшую производительность. SerDe ThriftSerDe используется для чтения/записи сериализованных объектов Thrift. При этом файл класса для объекта Thrift должен быть загружен первым. DynamicSerDe тоже читает/записывает сериализованные объекты Thrift, но понимает язык определения данных Thrift (DDL, Data Defenition Language), поэтому схема объекта может быть предоставлена во время выполнения. Также он поддерживает множество различных протоколов, в том числе TBinaryProtocol, TJSONProtocol и TCTLSeparatedProtocol, который записывает данные в записи с разделителями.
Hive использует SerDe формат файла (FileFormat) для чтения и записи строк таблицы следующим образом:
- файлы HDFS —> InputFileFormat —> <key, value> —> Deserializer —> объект строки (Row);
- объект строки —> Сериализатор —> <ключ, значение> —> OutputFileFormat —> файлы HDFS.
При этом ключи (key) игнорируются при чтении и всегда являются константой при записи. В основном объект строки хранится в value, т.е. значении пары <key, value>. Поскольку Hive не владеет форматом файлов HDFS, пользователи должны иметь возможность напрямую читать эти файлы в таблицах Hive с помощью других инструментов. Аналогичное правило справедливо и для прямой записи в файлы HDFS, которые можно загрузить во внешнюю таблицу Hive с помощью SQL-запроса CREATE EXTERNAL TABLE или LOAD DATA INPATH, который просто перемещает файл в каталог Hive-таблицы.
При работе с файлами HDFS Hive использует следующие классы FileFormat:
- TextInputFormat/HiveIgnoreKeyTextOutputFormat – для чтения/записи данных в формате обычного текстового файла;
- SequenceFileInputFormat/SequenceFileOutputFormat – для чтения/записи данных эти в бинарном формате Sequence File для хранения данных в виде сериализованных пар ключ/значение в экосистеме Apache Hadoop, который позволяет разбивать файл на участки (порции) при сжатии. Это обеспечивает параллелизм при выполнении задач MapReduce, т.к. разные порции одного файла могут быть распакованы и использованы независимо друг от друга. Подобно Apache AVRO, Sequence File считается линейно-ориентированным (строковым) форматом, в отличие от колоночных (столбцовых) типа RCFile, ORC и Parquet.
Если имеющихся в SerDe сериализаторов и десериализаторов недостаточно для обработки структуры данных, можно написать собственный SerDe, чтобы Hive знал, как загружать файлы в таблицы и наоборот. При этом если нужно, чтобы изменить типовые варианты использования Hive-таблицы, то разработчику следует расширить абстрактный класс AbstractSerDe, и удалить интерфейс SerDe. Как это сделать, мы рассмотрим далее.
Как написать свой собственный SerDe
Чаще всего дата-инженеру или разработчику распределенного приложения надо написать собственный десериализатор вместо типового SerDe, потому что пользователи просто хотят читать свой формат данных, а не записывать в него. Например, RegexDeserializer десериализует данные, используя параметр конфигурации regex и, возможно, список имен столбцов. Если пользовательский SerDe поддерживает DDL, будучи SerDe с параметризованными столбцами и типами столбцов, можно реализовать протокол на основе DynamicSerDe, а не писать свой SerDe с нуля. Это рекомендуется, потому что фреймворк передает DDL в SerDe через формат Thrift DDL, написать собственный парсер для которого не самая простая задача.
Важно помнить, что именно SerDe, а не DDL, определяет схему таблицы, хотя некоторые реализации SerDe используют DDL для настройки, но это можно переопределить в собственном сериализаторе-десериализаторе. Типы столбцов могут быть произвольно вложенными массивами, картами и структурами. Hive использует конструкцию обратного вызова ObjectInspector для анализа внутренней структуры объекта строки, а также структуры отдельных столбцов. ObjectInspector допускает отложенную десериализацию с помощью CASE/IF или при использовании сложных или вложенных типов и предоставляет единый способ доступа к сложным объектам, которые могут храниться в памяти в различных форматах, включая:
- экземпляр класса Java (Thrift или нативная Java);
- стандартный объект Java, где util.List используется для представления Struct и Array, а java.util.Map для представления сопоставления (Map);
- отложено инициализированный объект, например, Struct строковых полей, хранящихся в одном строковом объекте Java с начальным смещением для каждого поля;
Сложный объект может быть представлен парой ObjectInspector и Java Object. ObjectInspector не только сообщает структуру объекта, но также дает способы доступа к внутренним полям внутри объекта. Рекомендуется, чтобы пользовательские ObjectInspectors имели конструктор без аргументов в дополнение к их обычным конструкторам для сериализации.
Начиная с Hive 0.14, для собственного Hive SerDes был введен механизм регистрации, который обеспечивает динамическую привязку между ключевым словом STORED AS вместо нескольких спецификаций (SerDe, InputFormat и OutputFormat) в операторах CreateTable. Чтобы добавить новый собственный SerDe с ключевым словом STORED AS, разработчику нужно выполнить следующие действия:
- создать класс дескриптора формата хранения, унаследованный от java, который возвращает ключевое слово STORED AS и имена классов InputFormat, OutputFormat и SerDe;
- добавить имя класса дескриптора формата хранения в регистрационный файл StorageFormatDescriptor.
Как это сделать на практике, а также другие тонкости администрирования и эксплуатации Apache Hive для аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

