Недавно мы рассказывали про тонкости хранения потоковых файлов в Apache NiFi. Продолжая эту важную для обучения дата-инженеров тему, сегодня разберем еще несколько причин повышенного потребления ресурсов при работе с этим фреймворком и способы обхода этих ограничений.
Характер потоков и размер репозитория
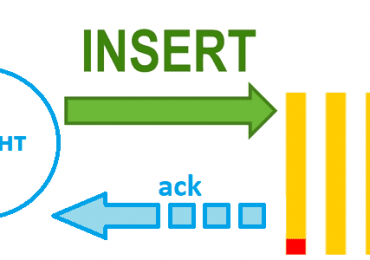
Apache NiFi не позволяет управлять ресурсами в разрезе потоков или процессоров: нельзя выделить определенное количество ядер ЦП на поток или количество оперативной памяти. Также невозможно ограничить использование репозиториев для потока. По умолчанию NiFi стремится сбалансировать использование ресурсов поровну между всеми имеющимися процессорами и объемами данных, чтобы уложиться в возможности среды. Но если какой-то поток является инициирующим, то он займет большую часть ресурсов, т.к. именно он обрабатывает больший объем данных. Поэтому другие потоки могут задерживаться с доставкой данных, что негативно повлияет на бизнес-процессы и технические системы, работающие с такими источниками данных, которые имеют ограниченный срок жизни сообщений. О том, как отследить и исправить такие ситуации, читайте в нашей новой статье.
В частности, именно это может случиться при определенных настройках в политике хранения данных, заданных через конфигурации retention.bytes и retention.ms. Подробнее об этом мы писали здесь. Если этим конфигурационным параметрам топика заданы слишком малые значения, NiFi не успеет забрать данные, и они затрутся новыми сообщениями. Таким образом, фактически случится потеря данных, что точно окажет негативное влияние на бизнес-пользователей.
Поэтому рекомендуется разделить среды исполнения разных потоков, чтобы потоки с большим объемом данных не задерживали другие, забирая большую часть ресурсов. Для разных сред можно указывать разные параметры, опираясь на характер нагрузки. Это можно сделать с помощью конфигурационного параметра nifi.content.claim.max.flow.files. По умолчанию его значение равно 100 и означает максимальное количество потоковых файлов для назначения одному утверждению контента.
Напомним, NiFi не знает окончательный размер фрагмента контента, помещаемого в потоковый файл (FlowFile) во время загрузки. Фреймворк просто смотрит на размер текущего утверждения, и если он не превышает 10 МБ, к нему добавляется следующий полный фрагмент контента независимо от его размера. При этом утверждение на контент не может быть перемещено в архив контент-репозитория, пока ни одна из частей контента в этом утверждении не будет привязана к активному FlowFile. Поэтому заявленный совокупный размер всех FlowFiles в реальных кпотоковых конвейерах, скорее всего, никогда не будет соответствовать фактическому использованию диска в репозитории контента. Этот совокупный размер не является размером утверждений содержимого, в которых находятся поставленные в очередь потоковые файлы, а представляет собой сообщаемый совокупный размер отдельных фрагментов содержимого. Именно поэтому репозиторий контента NiFi может достичь 100% использования диска, даже если пользовательский интерфейс NiFi сообщает, что общий совокупный размер данных в очереди меньше этого.
Поэтому при точной настройке конфигураций NiFi дата-инженеру и администратору кластера следует учитывать размер и количество данных данные. К примеру, в случае с очень маленькими ИЛИ очень большими данными, рекомендуется оставить значение параметра конфигурации nifi.content.claim.max.flow.files по умолчанию. Но при работе с данными, которые сильно варьируются от очень маленьких до очень больших, целесообразно уменьшить максимальный размер добавляемого файла и/или параметры максимального файла потока. Так можно уменьшить количество FlowFiles, которые превращаются в одно утверждение. Это снижает вероятность того, что один фрагмент данных сохранит активными большие объемы данных в репозитории контента.
Резюмируя вышесказанное, можно сделать вывод, что для исполнения инициирующей загрузки данных нужна отдельная среда развертывания Apache NiFi. Лучше всего подойдут виртуальные среды, выделяемые из некоего общего пула и возвращаемые обратно в случае простоя. Наконец, отметим еще одну важную практику инженерии данных, связанную со стандартизацией и унификацией подходов и инструментов. К примеру, рассматривать любой конвейер обработки данных как ETL-цепочку: получение из источников, изменение и загрузка в приемник.
Как оптимизировать производительность Apache NiFi, задав правильные настройки операционной системы и самого фреймворка, читайте в нашей новой статье.
Больше практических приемов по администрированию и эксплуатации Apache NiFi для эффективной аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники