
В этой статье для обучения дата-инженеров и администраторов кластера Apache NiFi разберем лучшие практики настройки этого популярного маршрутизатора потоковых данных. Какие настройки задать в операционной системе Linux и что исправить в конфигурациях самого Apache NiFi, чтобы ускорить обработку потоковых данных. Что настроить в Linux: 6 конфигураций Как и большинство серверных...

В рамках обучения дата-инженеров сегодня рассмотрим пример отправки данных в платформу сбора и анализа системных логов Splunk с помощью Apache NiFi. Как работает процессор PutSplunkHTTP, когда вместо него стоит выбрать InvokeHTTP, что такое HEC-токен и какие HTTP-методы REST API обеспечивают интеграцию Splunk с Apache NiFi. Что такое Splunk и как...
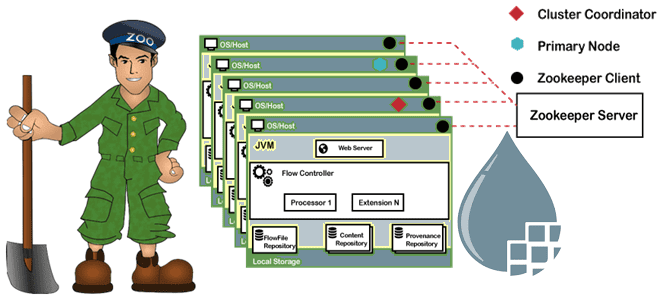
Сегодня рассмотрим важную для обучения администраторов кластера Apache NiFi тему по установке и настройке этого потокового ETL-фреймворка с использованием встроенного сервиса координации и синхронизации метаданных в распределенных системах Zookeeper. А также рассмотрим, как процесс выбора лидера в кластере Zookeeper позволяет серверам избежать аномальных всплесков трафика от клиентов и роста нагрузки....

Сегодня рассмотрим серьезную уязвимость CVE-2022-33140, связанную с авторизациями и обнаруженную в последнем выпуска Apache NiFi 1.16.3, о котором мы писали здесь. Почему проблема с ShellUserGroupProvider оказалась так значительна и что сделано для ее устранения. Уязвимость CVE-2022-33140 в Apache NiFi 1.16.3 В свежем релизе Apache NiFi 1.16.3, который вышел 15 июня...
Недавно мы рассказывали про стратегии обработки ошибок в потоковых конвейерах данных на Apache NiFi. В продолжении этой темы, сегодня более детально разберем, с какими исключениями может столкнуться дата-инженер, о чем они говорят и как их обойти. Виды исключений Apache NiFi При разработке собственного процессора может возникнуть несколько различных неожиданных ситуаций....

В этой статье для обучения дата-инженеров рассмотрим, почему в потоковых конвейерах обработки данных на базе Apache NiFi случаются ошибки, и какие популярные стратегии и инструменты помогут идентифицировать эти проблемы, а также решить их. Проблемы конвейеров обработки данных на Apache NiFi Конвейеры данных помогают консолидировать информацию из разных источников, чтобы получить...

15 июня 2022 года вышел новый выпуск Apache NiFi. Разбираем, что нового и полезного в релизе 1.16.3: исправленные ошибки, а также улучшения, важные для дата-инженера и администратора кластера Apache NiFi. 7 исправленных ошибок в релизе 1.16.3 Apache NiFi – один из самых популярных и востребованных инструментов современного дата-инженера. Эта платформа...

Мы уже писали о преимуществах развертывания Apache NiFi на Kubernetes, а также сложностях практической реализации этого процесса. Сегодня поговорим о контейнеризации реестра NiFi с использованием Helm-диаграмм, а также совмещения с Apache Ranger и Kerberos. 7 главных трудностей развертывания Apache NiFi на Kubernetes Apache NiFi активно используется дата-инженерами для организации потоковых...
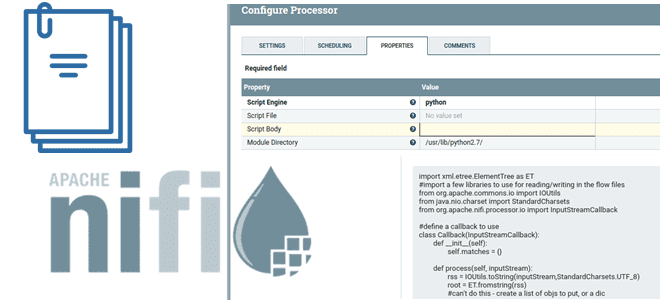
В этой статье для дата-инженеров разберемся, что такое NiFi Scripted Components и как они заполняют пробел между скриптами и пользовательскими компонентами: процессорами, контроллерами, сообщениями и средствами их чтения/записи. Рассмотрим примеры скиптовых процессоров и сервисов, а также определим реальные достоинства и недостатки этих компонентов. Почему просто скриптовых процессоров Apache NiFi недостаточно?...

В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi. Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт)....