
Мы регулярно добавляем в наши курсы по Apache Flink и Spark для дата-инженеров полезные материалы и инструменты, которые помогают повысить эффективность разработки и эксплуатации приложений аналитики больших данных. Читайте далее, что такое SeaTunnel и как эта высокопроизводительная платформа интеграции распределенных данных упрощает их потоковую синхронизацию средствами SQL-заданий Apache Flink и...
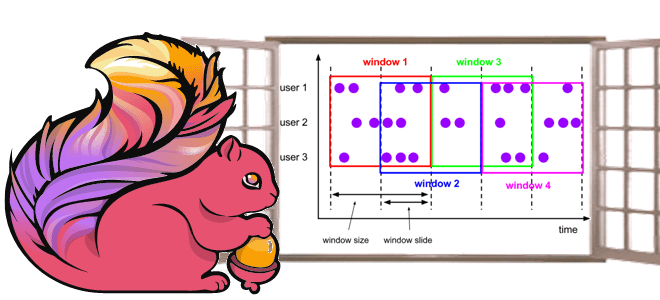
Чтобы сделать наши курсы по Apache Flink для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня рассмотрим, как этот фреймворк потоковой аналитики больших данных реализует концепцию оконных функций. Жизненный цикл окна, ключевые понятия и оконные операции Apache Flink, управляемые данными и временем. Что такое окно в потоковой обработке данных...
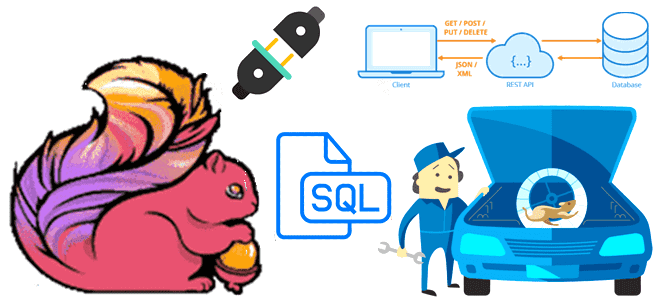
Недавно мы писали про HTTP-коннектор к Apache Flink от компании GetInData, который позволяет обогатить ML-модель данными из внешней системы с использованием REST API и SQL-концепции Lookup Joins. Как устроен этот коннектор с открытым исходным кодом, и какие методы Flink SQL он использует: разбираем на практическом примере. Что такое HATEOAS: блеск...
В этой статье для обучения дата-инженеров и разработчиков распределенных приложений рассмотрим, как Flink SQL может обогатить ML-модель данными из внешней системы в режиме реального времени с использованием REST API. Что представляет собой http-flink-connector с открытым исходным кодом, разработанный GetInData на основе концепции Lookup Joins. Обогащение данных c SQL: достоинства использования...

Сегодня разберем тему, особенно полезную для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink: обнаружение сложных цепочек связанных событий в потоковой обработке. Как создать свой шаблон поиска сложных событий с библиотекой FlinkCEP. Комплексная обработка событий или зачем вам CEP Современный data-driven бизнес хочет принимать...
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica. Зачем и как выполнить развертывание Apache...

Сегодня рассмотрим, с какими нетиповыми ошибками может столкнуться дата-инженер при работе с Apache Flink, а также как решить эти проблемы. Где и что править, когда сервер BLOB-объектов завис из-за слишком большого количества подключений, почему не хватает памяти при развертывании Flink-приложений в кластере Kubernetes и как ускорить инициализацию заданий. Особенности работы...
Мы уже рассматривали важность мониторинга приложений Apache Flink и говорили про метрики отслеживания задержки обработки данных в потоковых заданиях. Сегодня заглянем под капот этого фреймворка и разберем, какие показатели работы JVM, а также RocksDB особенно важны для дата-инженера и разработчика распределенных приложений. Метрики JVM во Flink-приложениях Напомним, основным языком разработки...
Недавно мы говорили про непрерывный мониторинг Flink-приложений и подробно рассмотрели метрики состояния и пропускной способности. В продолжение этой важной для разработчиков и дата-инженеров темы, сегодня рассмотрим, как идентифицировать временную задержку обработки данных. Пользовательские метрики задержки в потоковых приложениях Для потоковых приложений, которые обрабатывают события в режиме, близком к реальному времени,...
Специально для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink, рассмотрим наиболее важные системные показатели, а также инструменты мониторинга этих метрик. Мониторинг Flink-приложений: особенности и метрики В общем случае мониторинг приложений гарантирует, что ПО обрабатывает данные и выполняет запрошенные действия ожидаемым образом. Непрерывное отслеживание...