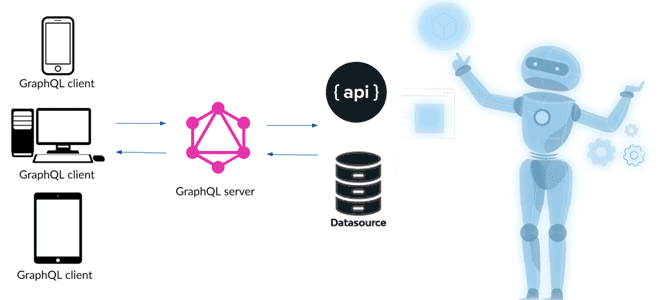
Недавно мы упоминали GraphQL как мощный и гибкий язык запросов к данным, хранящимся в графовых СУБД. Сегодня рассмотрим, чем эта технология может быть полезна в проектах Machine Learning, какие сложности с ней связаны и как их решить с помощью MLOps.
GraphQL для ML: возможности и примеры
Не будучи в чистом виде языком запросов к графовым базам данных, о чем мы писали здесь, GraphQL возвращает сложный граф данных (отсюда и слово Graph в названии), снижая количество запросов по сети до одного. Это язык запросов для API, который позволяет клиенту запрашивать только нужные данные, в отличие от традиционных REST API, которые возвращают весь набор данных ресурса, связанный с конечной точкой. Эта технология снижает нагрузку на сеть, позволяя реализовать сложные аналитические вычисления в рамках одного запроса. Применяя GraphQL к системам машинного обучения, можно управлять ML-моделями и отслеживать их производительность с помощью единого API. Наконец, с точки зрения производственного использования проектов Machine Learning, GraphQL позволяет экономно в плане трафика обновлять ML-модели в режиме реального времени, что крайне важно для приложений машинного обучения, которые необходимо постоянно переобучать и обновлять.
Если ML-модель должна обрабатывать много данных и различные параметры фильтрации, с потенциалом будущего развития системы машинного обучения, GraphQL будет отличным выбором. Для примитивных CRUD-операций подойдет классический REST API, который реализует манипулирование ресурсами через основные HTTP-запросы (GET, POST, PUT, DELETE).
К примеру, используя GraphQL, разработчики могут создавать API, который позволяет пользователям гибко и эффективно взаимодействовать с ML-моделями обработки естественного языка (NLP). Предположим, NLP-приложение для понимания запросов клиентов и ответа на них. С GraphQL это приложение может запросить ML-модель, чтобы понять намерение клиента и предоставить соответствующий ответ в режиме реального времени и без дополнительных сетевых запросов.
Также GraphQL можно использовать для распознавания изображений, создав API, который позволяет пользователям запрашивать ML-модель и получать информацию об объектах или сценах на картинке. К примеру, дл идентификации растений или грибов в лесу. Еще GraphQL подойдет для создания унифицированного аналитического API, который позволит всем заинтересованным сторонам использовать единый источник доступа к согласованным данным, но несвязанным между собой семантически. Это соответствует ключевым идеям концепции непрерывного управления и сопровождения ML-систем под названием MLOps.
Таким образом, GraphQL может быть мощным инструментом для создания и управления моделями машинного обучения с широким спектром сценариев практического использования. Как применить его для разработки API проекта машинного обучения, рассмотрим далее.
Инструменты для реализация проекта машинного обучения
При разработке системы машинного обучения с использованием GraphQL следует выбрать инструменты, которые поддерживают эти технологии. Например, Apollo Server для создания GraphQL API, TensorFlow.js для запуска ML-моделей в браузере или на сервере и GraphQL-Yoga для создания полнофункционального сервера GraphQL. С точки зрения MLOps – концепции непрерывной разработки и развертывания проектов Machine Learning, еще необходима система управления моделями, поддерживающая версионирование, контроль доступа и мониторинг. Также необходимо помнить о масштабируемости, т.к. ML-модели могут требовать значительных вычислительных ресурсов, и важно убедиться, что платформа выдержит такую нагрузку. Один из способов сделать это — использовать такой сервис, как AWS Lambda или Google Cloud Functions, для запуска моделей машинного обучения в бессерверной среде.
Наконец, при работе с конфиденциальными данными крайне важно убедиться, что ML-платформа безопасна и соответствует требованиям. GraphQL обеспечивает уровень безопасности через свой API, но необходимо также обеспечить аутентификацию и шифрование данных, т.к. модели машинного обучения часто обрабатывают конфиденциальную информацию. В частности, следует обеспечить контроль доступа. Однако, технология GraphQL изначально не очень хорошо поддерживает разграничение прав доступа к данным: фактически, клиент может запросить любые данные. Поэтому контроль доступа необходимо реализовать в стороннем компоненте, чтобы предоставить доступ к ML-моделям только авторизованным пользователям и гарантировать, что только они и нужные сервисы смогут просматривать, изменять или выполнять проекты машинного обучения. Практически реализовать это также можно, применяя лучшие практики MLOps и DevOps, в частности, версионирование исходного кода.
Еще одним важным аспектом безопасности является шифрование данных. При работе с конфиденциальными данными крайне важно обеспечить их шифрование как при передаче, так и при хранении. Это особенно важно при использовании GraphQL, поскольку эта технология предполагает доступ к данным из нескольких источников. Зашифровав данные, можно избежать раскрытия конфиденциальной информации в соответствии с требованиями GDPR и других регламентов по защите данных.
С инструментальной точки зрения использования GraphQL для проектов Machine Learning стоит помнить, что этот язык запросов и среда выполнения на стороне сервера для создания API не привязан к какой-либо конкретной базе данных или языку программирования. Можно создать свой сервер GraphQL на Node.js, C#, Scala, Python и других языках. В проектах Data Science чаще всего используется Python как средство реализации ML-алгоритмов и прототипирования сервисов. В частности, для создания серверов Python-приложений часто используется Flask —минималистичный фреймворк, который может предоставить GraphQL API для обслуживания моделей машинного обучения. Запросы от клиентских приложений может перенаправлять шлюз GraphQL, используя федерацию схем данных для работы с несколькими источниками.
Для работы со схемами данных GraphQL необходимо определить их. Изначально в экосистеме Python нет библиотек типа graphql-tools, поэтому нужно определить схему с подходом, основанным на коде. Сделать это можно с помощью библиотеки Graphene, которая предоставляет инструменты для реализации GraphQL API в Python с использованием подхода «сначала код». Эта библиотека полностью интегрирована с самыми популярными веб-фреймворками и ORM. Подход Graphene к созданию API GraphQL отличается от подходов, основанных на схеме данных, что есть в Apollo Server (JavaScript) или Ariadne (Python). Вместо написания языка определения схемы GraphQL (SDL) пишется Python-код для описания данных, предоставляемых сервером. Graphene создает схемы, полностью соответствующие спецификации GraphQL, а также предоставляет инструменты и шаблоны для создания Relay-совместимого API.
Схема GraphQL описывает каждое поле в модели данных, предоставляемой сервером, с использованием скалярных типов, таких как String, Int и Enum, и составных типов, таких как List и Object. Схема также может определять любое количество аргументов для полей. Это мощный способ для запроса описать точные требования к данным для каждого поля. Чтобы реализовать основное преимущество технологии GraphQL – передача в ответе только данных, которые запросил клиент, для каждого поля в схеме данных надо написать метод Resolver с использованием текущего контекста и аргументов. Подробный пример, как это сделать, приведен в источнике [2]. Разумеется, с учетом изменчивости данных, характерных для проектов Machine Learning, необходимо версионировать схемы данных с использованием реестра схем и Git-подобных инструментов в современных MLOps-фреймворках, о которых мы писали здесь и здесь.
Как применять эти и другие средства MLOps в проектах аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

