
В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене...
Вчера мы упоминали, как долгожданный KIP-500, реализованный в марте 2021 года, позволяет не только отказаться от Zookeeper в кластере Apache Kafka, но и снимает ограничение числа разделов, чтобы масштабировать брокеры практически до бесконечности. Однако, не все так просто: читайте далее, какие важные функции еще не поддерживаются в этом экспериментальном режиме...
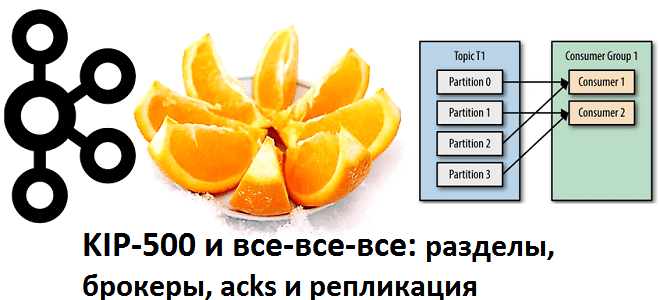
Сегодня рассмотрим важную практическую задачу из курсов Kafka для разработчиков и администраторов кластера – разделение топиков по брокерам. Читайте далее, как пропускная способность всей Big Data системы зависит от числа разделов, коэффициента репликации и ответного ack-параметра, а также при чем здесь KIP-500, позволяющий отказаться от Zookeeper. Что такое партиционирование в...