
Цифровизация возможна не только на предприятиях. Цифровая трансформация настигает даже города, чтобы сделать их более удобными для жителей и менее вредными для планеты. Сегодня мы подготовили для вас 8 интересных примеров по 4 разным направлениям об использовании больших данных (Big Data), машинного обучения (Machine Learning) и интернета вещей (Internet of...

Проанализировав предложения крупных PaaS/IaaS-провайдеров по развертыванию облачного кластера, сегодня мы сравним 4 наиболее популярных дистрибутива Hadoop от компаний Cloudera, HortonWorks, MapR и ArenaData, которые используются при развертывании локальной инфраструктуры для проектов Big Data. Как мы уже отмечали, эти дистрибутивы распространяются бесплатно, но поддерживаются на коммерческой основе. Некоторые отличия популярных дистрибутивов...

Мы уже рассказывали про общие достоинства и недостатки облачных Hadoop-кластеров для проектов Big Data и сравнивали локальные дистрибутивы. В продолжение этой темы, в сегодняшней статье мы подготовили для вас сравнительный обзор наиболее популярных PaaS/IaaS-решений от самых крупных иностранных (Amazon, Microsoft, Google, IBM) и отечественных (Яндекс и Mail.ru) провайдеров [1]. Сравнение...

Продолжая опровергать мифы о Hadoop, сегодня мы расскажем о том, как и где создать облачный кластер для Big Data и почему это выгодно. Концепция облачных вычислений стала популярна с 2006 года благодаря компании Amazon и постепенно распространилась на использование внешних платформ и инфраструктуры как сервисов (Platform as a Service, PaaS,...
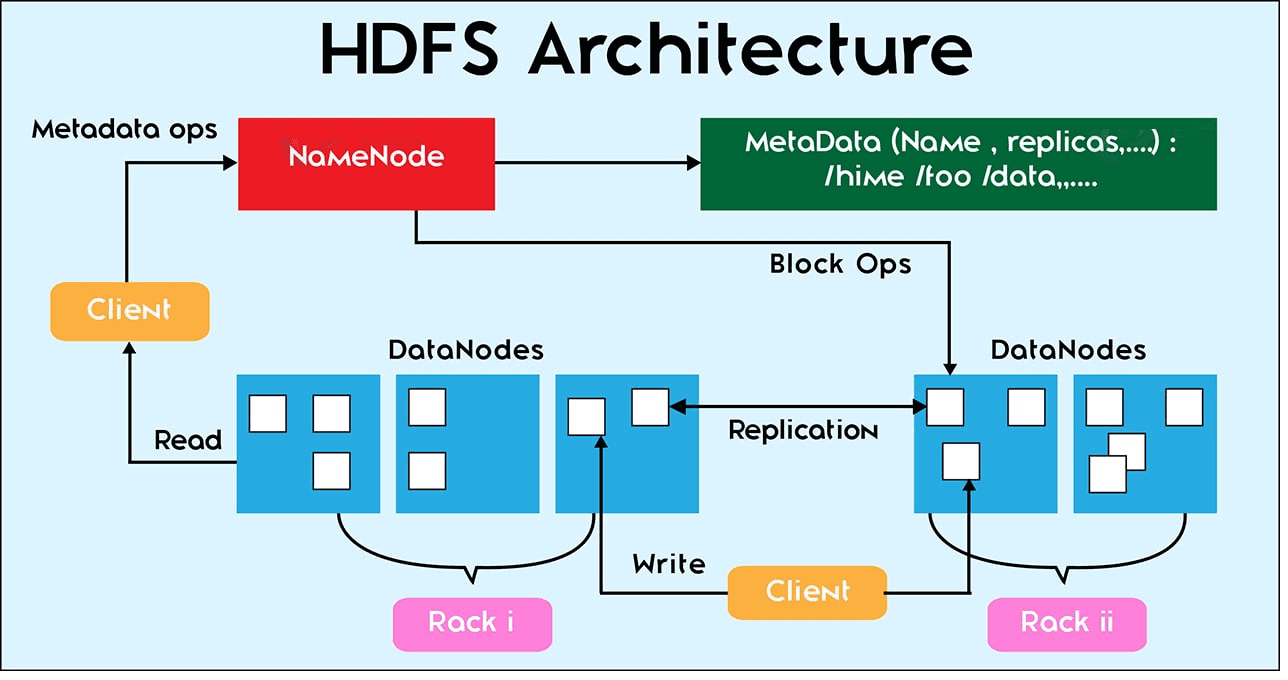
Мы уже рассказывали, как большие данные (Big Data) сохраняются на диск. Сегодня поговорим о других файловых операциях в HDFS: репликации, чтении и удалении данных. За все файловые операции в Hadoop Distributed File System отвечает центральная точка кластера – сервер имен NameNode. Сами операции с конкретными файлами выполняются на локальном узле...
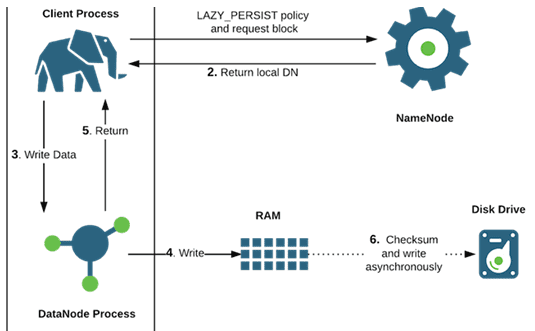
HDFS предназначена для больших данных (Big Data), поэтому размер файлов, которые хранится в ней, существенно выше чем в локальных файловых системах – более 10 GB [1]. Продолжая тему файловых операций и взаимодействия компонентов Hadoop Distributed File System, в этой статье мы расскажем, как осуществляется запись таких больших файлов с учетом блочного...

Благодаря архитектурным особенностям распределенной файловой системы Hadoop, допустимые файловые операции в ней отличаются от возможных действий с файлами на локальных системах. В этой статье мы рассмотрим файловые операции в HDFS и взаимодействие ее компонентов: узлов данных и сервера имен с клиентами - пользователями или приложениями. Файловые операции HDFS В отличие...

Сегодня мы поговорим о заблуждениях насчет базового инфраструктурного понятия хранения и обработки больших данных – экосистеме Hadoop и развеем 3 самых популярных мифа об этой технологии. А также рассмотрим применение Cloudera, Hortonworks, Arenadata, MapR и HDInsight для проектов Big Data и машинного обучения (Machine Learning). Миф №1: Hadoop – это...

Даже после очистки и нормализации данных, выборка еще не совсем готова к моделированию. Для машинного обучения (Machine Learning) нужны только те переменные, которые на самом деле влияют на итоговый результат. В этой статье мы расскажем, что такое отбор или выделение признаков (Feature Selection) и почему этот этап подготовки данных (Data...

Мы уже рассказали, что такое нормализация данных и зачем она нужна при подготовке выборки (Data Preparation) к машинному обучению (Machine Learning) и интеллектуальному анализу данных (Data Mining). Сегодня поговорим о том, как выполняется нормализация данных: читайте в нашем материале о методах и средствах преобразования признаков (Feature Transmormation) на этапе их...