Сегодня познакомимся с еще одним полезным инструментом Apache NiFi: как использовать предметно-ориентированный язык RecordPath, чтобы получить доступ к полям записи. Смотрим на примере процессора UpdateRecord.
Что такое RecordPath в Apache NiFi
Apache NiFi имеет множество готовых процессоров, способных принимать, обрабатывать, маршрутизировать, преобразовывать и доставлять данные любого формата и размера благодаря набору шаблонов, разработанных для работы с разными типами данных. Для обработки данных, ориентированных на записи в NiFi есть набор служб контроллеров для анализа различных форматов данных и представления их согласованным образом с использованием API RecordReader. Это позволяет обрабатывать данные, записанные в любом формате, с применением RecordReader, способным создавать объект Record, представляющий данные.
В NiFi запись – это абстракция, которая позволяет обрабатывать данные одинаково, независимо от формата, в котором они находятся. Запись состоит из одного или нескольких полей. Каждое поле имеет имя и связанный с ним тип. Структура записи описывается с помощью схемы, которая перечисляет набор полей и их тип. Каждое из полей может быть записью, т.е. иметь много уровней иерархической вложенности. После преобразования потока данных в записи API RecordWriter позволяет сериализовать эти записи обратно в потоки байтов, чтобы передать их в другие системы.
В NiFi есть процессоры, которые предоставляют возможности маршрутизации, запросов и преобразования данных, ориентированных на записи. Примеры таких процессоров мы недавно рассматривали здесь. Часто для выполнения желаемой функции процессору требуется ввод данных от пользователя, чтобы определить, какие поля или какие значения в записи следует обрабатывать. Для этого дата-инженеру удобно использовать RecordPath – простой и удобный предметно-ориентированный язык (DSL, Domain-Specific Language).
Язык RecordPath позволяет ссылаться на поля внешней или дочерней записи, разделяя имена дочерних элементов косой чертой (/) – дочерним оператором. Например, запись состоит из двух полей: имени клиента и детальных сведений о нем – дочерней записи из 2-х полей поля: идентификатора и адреса. Адрес, в свою очередь, тоже является записью, которая содержит 5 полей: номер, улица, город, область и почтовый индекс. Пример такой вложенной JSON-структуры может выглядеть так:
{
"name": "Ivanov Ivan",
"details": {
"identifier": 151,
"address": {
"number": "13",
"street": "Lenina",
"city": "Moscow",
"region": "MO",
"zip": " 143350"
}
}
}
Можно сослаться на поле zip, используя RecordPath: /details/address/zip, т.е. использовать поле детальных сведений корневой записи. Далее идут поле адреса дочерней записи и поле почтового индекса этой записи.
Если неизвестен полный путь к конечному полю, можно использовать оператор-потомок (//) вместо дочернего оператора (/). Получить то же поле zip, что и выше, можно через путь //zip. Однако, оператор-потомок может соответствовать многим полям, тогда как дочерний оператор соответствует не более чем одному полю. Поэтому при наличии нескольких значений одного ключа в одной записи, следует использовать 2 косые черты, чтобы получить весь набор значений. Кроме того, RecordPath позволяет манипулировать со значениями, предоставляя набор функций с простым синтаксисом. Чтобы понять, как дата-инженер может использовать это на практике, рассмотрим небольшой пример.
Практический пример с процессором UpdateRecord
В качестве примера рассмотрим UpdateRecord – один из процессоров NiFi, ориентированных на запись. Он обновляет содержимое FlowFile, содержащего данные, которые могут быть прочитаны через RecordReader и записаны с помощью RecordWriter. Этот процессор требует, чтобы было добавлено хотя бы одно определяемое пользователем свойство. Имя Свойства должно указывать RecordPath, определяющий поле, которое должно быть обновлено. Значение Свойства является либо замещающим значением (необязательно с использованием языка выражений), либо само является RecordPath, который извлекает значение из записи. Определяется ли значение свойства как RecordPath или буквальное значение, зависит от конфигурации свойства <Replacement Value Strategy>.
UpdateRecord использует RecordPath, позволяя пользователю указать, какие поля в записи следует обновить. Нужное свойство надо добавить в конфигурацию процессора. Имя определяемого пользователем свойства должно быть текстом RecordPath, который должен оцениваться для каждой записи. Значение свойства указывает, какое значение должно войти в это выбранное поле записи.
При указании замещающего значения определяемого пользователем свойства можно указать буквальное значение, например, конкретное число, выражение языка выражений для ссылки на атрибуты FlowFile или другой путь RecordPath, из которого можно получить желаемое значение записи. Следует ли интерпретировать введенное значение как литерал или как путь к записи, определяется значением свойства <Replacement Value Strategy>.
Если указан RecordPath и он не соответствует ни одному полю во входной записи, это свойство будет пропущено, а все остальные свойства будут по-прежнему оцениваться. Если RecordPath соответствует только одному полю, это поле будет обновлено соответствующим значением. Если несколько полей соответствуют RecordPath, все совпадающие поля будут обновлены. Если замещающее значение само по себе является несоответствующим RecordPath, то для поля будет установлено нулевое значение. В случаях, когда это нежелательно, можно использовать предикаты RecordPath для фильтрации совпадающих полей, чтобы поля не были выбраны.
Как это может выглядеть в графическом интерфейсе NiFi при настройке свойств процессора UpdateRecord, показано на следующем рисунке:
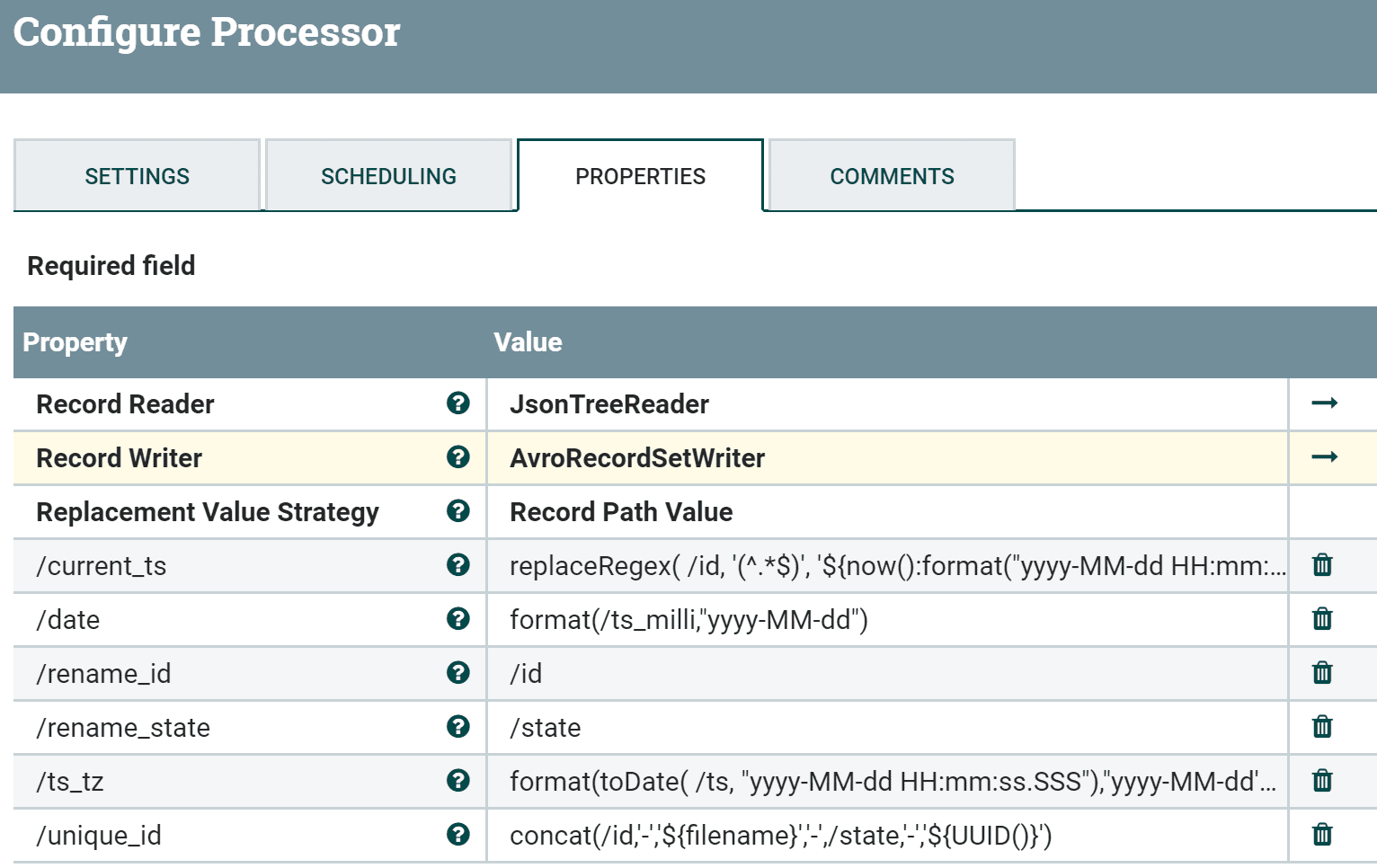
На приведенном рисунке поле записи /ts_tz будет преобразовано с помощью функции format(), которая переформатирует строку даты. А функция concat() объединяет несколько строковых значений в одну строку.
О том, какая новая функция добавлена в этот DSL-язык в релизе 1.20 и зачем, читайте в нашей новой статье. А в этом материале вы узнаете про преобразование JSON-документов с помощью процессоров, основанных на Java-библиотеке JOLT.
Узнайте больше подробностей по администрированию и эксплуатации Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники