
Сегодня рассмотрим пару важных тем для администратора Greenplum: требования к программно-аппаратному окружению, а также особенности установки и настройки этой MPP-СУБД. Еще разберем, как Arenadata Cluster Manager облегчает и автоматизирует эти процессы в Arenadata DB. Программное окружение Greenplum: операционные системы и Java Greenplum 6 работает на следующих платформах операционных систем: Red...
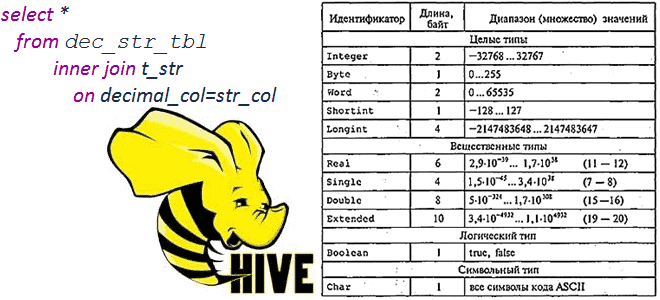
Сегодня рассмотрим тему, полезную для обучения администраторов SQL-on-Hadoop и разработчиков распределенных приложений: операции сравнения и арифметические вычисления между строковыми и десятичными типами в Apache Hive 1.2.0 и 3.1.0, а также MySQL и Microsoft SQL Server 2017. Про типы данных и SQL-запросы в Apache Hive Чтобы упростить сравнение, будем считать типы...
В этой статье для администраторов Greenplum рассмотрим, как настроить систему сетевой защиты Kerberos для этой MPP-СУБД, чтобы контролировать доступ к хранящимся в ней данным с помощью сервера аутентификации. А также рассмотрим основные понятия и термины Kerberos применительно к Greenplum. Что такое Kerberos и зачем это в Greenplum Напомним, Kerberos –...

Чем хороши JSON-файлы и как с ними работать в Apache Spark и Hive: проблемы обработки вложенных структур данных и способы их решения на практических примерах. Как автоматизировать переименование некорректных названий полей во вложенных структурах данных JSON-файлов на любом количестве таблиц со множеством полей, чтобы создать таблицу в Hive Metastore и...
Недавно мы писали про пользу snapshot’ов Apache HBase на примере компании Vimeo. Сегодня рассмотрим кейс корпорации Box, которая специализируется на облачных enterprise-продуктах совместного управления контентом и файлами. Переход от локальной HBase к Google Cloud BigTable: сложности миграции и способы их обхода. Сходства и различия Apache HBase с Google Cloud BigTable...

Добавляя новые интересные примеры в наши курсы для дата-аналитиков, разработчиков распределенных приложений и администраторов SQL-on-Hadoop, сегодня рассмотрим опыт видеоаналитики в компании Vimeo с использованием Apache Spark. Как быстро запросить множество данных из Apache HDFS через Phoenix и Spark из моментальных снимков HBase с минимальным влиянием на кластер. Аналитика очень больших...

Сегодня в рамках обучения дата-аналитиков и разработчиков распределенных приложений, рассмотрим, что такое пользовательские функции в Apache Hive, как их создать и использовать. А также в чем проблема вызова UDF-функции, зарегистрированной в Hive, из Impala и при чем здесь Sentry. Простые и сложные UDF в Apache Hive Пользовательские функции в Hive...

О том, что такое spill-эффект, мы недавно писали на примере Apache Spark. Однако, проблема переброса данных из оперативной памяти на жёсткий диск и обратна характерна и для Greenplum. Где посмотреть количество и объем spill-файлов, а также как устранить причину их образования с помощью конфигурационных параметров и инструментов администратора. Что такое...

Ранее мы писали о том, как фотохостинг Pinterest с помощью новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, объединяет пакетную и потоковую аналитику больших данных, чтобы еще лучше обслуживать более 475 миллионов своих пользователей. Сегодня поговорим про контроль сетевого трафика и синхронизацию источников данных через генерацию...
Мы уже писали, зачем нужна статистика таблиц при оптимизации SQL-запросов на примере Greenplum. Сегодня рассмотрим, как собрать статистические данные в таблицах Apache Hive, каким образом это поможет оптимизатору запросов и какие есть способы сбора статистики в этом популярном инструменте стека SQL-on-Hadoop. Еще раз о пользе статистики для оптимизации запросов в...