 1115
1115 
Содержание
Чтобы сделать наши курсы по Apache Kafka для разработчиков Big Data систем еще более интересными, а обучение – запоминающимся, сегодня мы рассмотрим еще несколько примеров реализации микросервисной архитектуры на этой стриминговой платформе. А также поговорим про проблемы удаления данных в этой архитектурной модели, разобрав кейс компании Twitter по построению корпоративного конвейера стирания данных на базе Kafka.
Микросервисная event-streaming архитектура на Apache Kafka: 5 разных примеров и парочка общих проблем
Сегодня микросервисная архитектура стала фактически стандартом де-факто: все больше компаний приходят к этой модели, разделяя «монолиты» своих систем на множество небольших сервисов, каждый из которых решает узко направленную задачу. При некоторых сложностях архитектурного проектирования, данный подход повышает гибкость и расширяемость программных систем, позволяя расширять их функциональные возможности путем добавления новых служб. Это отлично поддерживает принципы Agile и DevOps, сокращая общее время разработки за счет итеративной поставки сервисов в соответствии с требованиями современного бизнеса, о чем мы рассказывали здесь.
В мире Big Data такая идея реализуется с помощью Apache Kafka, которая выполняет роль средства интеграции данных между разными сервисами, аккумулируя сообщения от издателей или продюсеров (producer) в разные топики (topic), откуда их считывают потребители (consumer). При этом обработка данных о случившихся событиях ведется непрерывно, фактически в реальном времени. Поэтому подобная архитектура получила название event streaming, отражая потоковый режим вычислений с данными о событиях [1].
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
12 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Успешность этой архитектурной модели и ее реализации с помощью Apache Kafka подтверждает ее популярность в промышленной эксплуатации (production). В частности, именно так Kafka используется в ML-системе сети строительных супермаркетов Леруа Мерлен и компании Авито, о чем мы писали в этом материале. По похожему принципу банк ВТБ реализовал собственный ML-конвейер, интегрировав сервисы кредитного скоринга, прогнозирования потребительского спроса и выявления мошенничества в единую информационную среду, которую будет легко расширять и поддерживать [2].
Еще одним характерным примером использования Apache Kafka в качестве основы для микросервисной архитектуры является кейс французской компании Leboncoin – доски бесплатных объявлений. Она пришла к Кафка с монолита на PostgreSQL, внедряя микросервисный подход с поддержкой старой СУБД, где пока еще хранится много важных данных. В этом кейсе в Apache Kafka записываются все обновления, происходящие с каждым объявлением в СУБД, позволяя получать события даже из устаревшей базы данных [3].
Наконец, вчера мы разбирали кейс построения конвейера для ML-системы речевого анализа Callinter от китайской компании Fano Labs. Можно перечислить еще множество других интересных примеров реализации микросервисной архитектуры Big Data систем на базе Apache Kafka. Однако, для такого подхода свойственна проблема удаления данных, когда ответственность за них распределена по всей компании. Далее мы рассмотрим, как Twitter решает эту задачу, организовав конвейер стирания данных, который также основан на Kafka [4].
Конвейер стирания данных в микросервисной системе Twitter
Прежде всего поясним, что под удалением данных дата-инженеры Twitter имеют ввиду не разовое событие, а целый процесс, который включает обнаружение данных для удаления, предоставление доступа к ним и обработку, т.е. собственно стирание. При этом учитываются ряд важнейших аспектов, характерных для микросервисной архитектуры, такие как [4]:
- обнаруживаемость – из-за разнородного хранения источников и хранилищ корпоративной информации, найти данные, которые нужно удалить, не так просто. Данные о событии, пользователе или записи могут находиться в датасетах онлайн или офлайн и принадлежать разным структурным подразделениям. Поэтому сперва составить корпоративную базу знаний о том, где хранятся какие данные и в каком виде.
- Доступ к найденным данным и методы их обработки. Данные в онлайн можно изменять с помощью API реального времени или асинхронного мутирующего метода (мутатора). Офлайн-данные в автономном хранилище можно изменять с помощью параллельной распределенной обработки, например, MapReduce. Чтобы получить доступ к каждому фрагменту данных, конвейер стирания должен поддерживать все 3 указанных метода обработки. При этом данные, изменяемые через API в реальном времени, являются самыми простыми. Конвейер стирания может вызывать этот API для удаления данных. После успешного выполнения вызовов API для каждого фрагмента данных данные удаляются и конвейер стирания останавливается. Обратной стороной этого подхода является расхождение в планируемой и реальной скорости удаления данных. Предполагается, что каждая задача удаления выполняется за время вызова API (секунды или миллисекунды). Но на практике это может занять больше времени, что усложняет работу конвейера стирания. Например, кгда речь идет о данных, которые экспортируются в автономные снимки СУБД (snapshots), или существуют в нескольких серверных системах и кешах. Такая денормализация присуща архитектуре микросервисов и повышает производительность, делегируя ответственность за жизненный цикл данных той команде, которой принадлежат их API и бизнес-логика.
- Оповещение владельцев данных об их удалении. Конвейер стирания может публиковать события стирания в распределенной очереди, такой как Apache Kafka, куда будут подписаны клииенты, чтобы инициировать удаление данных. Они обрабатывают событие стирания и связываются с командой, чтобы подтвердить запрос на удаление. При этом могут существовать полностью автономные датасеты, содержащие данные для удаления, например, снэпшоты или обучающие данные для модели Machine Learning.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Таким образом, получается целый конвейер, который будет выполнять следующие функции [4]:
- принимать входящие запросы на удаление;
- отслеживать процесс удаление и сохранять информацию о том, какие части данных были удалены;
- вызывать синхронные API-интерфейсы для удаления данных;
- публиковать события о стирании данных для их асинхронного удаления;
- создавать автономный датасет о событиях стирания данных.
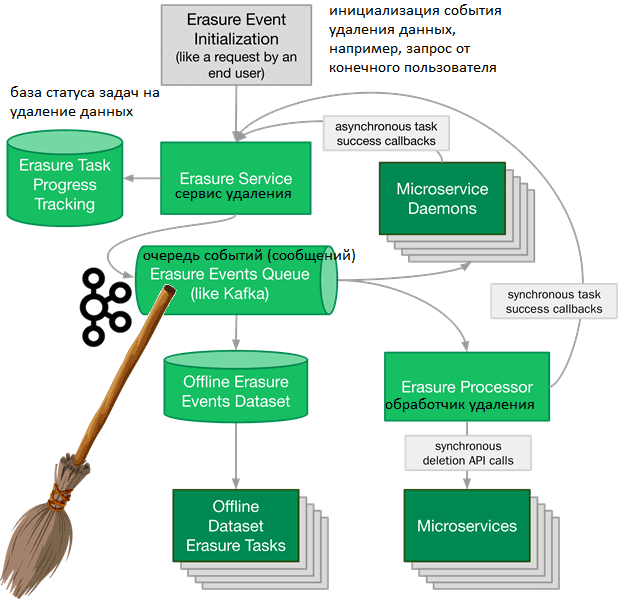
При реализации подобного конвейера также необходимо решить ряд проблем с его обслуживанием и эксплуатацией [4]:
- зависимость от сети передачи данных, когда перебои в обслуживании могут привести к некорректной работе всего конвейера, который должен быть устойчивым, чтобы успешно выполнить стирание. Поэтому следует предусмотреть возможность выполнения задач после восстановления сервиса, например, с помощью повторного их воспроизведения. Тогда в случае сбоя нужно просто воспроизвести все сброшенные события стирания. Система отслеживания стирания знает, какие события стирания еще не полностью обработаны, и может повторно опубликовать их.
- Зависимость от самих данных, которые могут не стираться, например, потому что изначально были некорректными.
- Обслуживание такого конвейера, который объединяет разрозненные задачи в конвейер с одним SLA (Service Level Agreement, соглашение об уровне предоставления услуг), может масштабироваться только в том случае, если каждая команда берет на себя ответственность за свою роль в удалении данных. Подробнее о SLA и других показателях эксплуатационной надежности мы рассказывали здесь.
- Тестирование распределенного конвейера, подобного этому, следует аналогичному принципу – каждая команда, владеющая данными, отвечает за тестирование своих задач удаления. Поэтому все, что нужно сделать владельцу конвейера стирания – это генерировать тестовые события, на которые он сможет реагировать. Таким образом, необходимо координировать создание тестовых данных в системах, принадлежащих различным командам. Чтобы выполнить интеграционное тестирование своих задач стирания, командам нужны тестовые данные. Для этого можно развернуть среду тестирования, которая объединяет создание тестовых данных с заданием cron, публикующим события стирания через некоторое время после создания тестовых данных. Также для подобного запуска задач по расписанию можно воспользоваться Apache Airflow.
- Сложность конвейера стирания может быть значительно снижена за счет уровня доступа к данным или каталога данных, хранящихся в онлайн-микросервисах и автономных хранилищах. Например, слои доступа к данным или каталоги данных индексируют данные, необходимые для удовлетворения запроса на стирание, и позволяют обрабатывать эти данные. Это объединяет результаты удаления данных с обязанностями владения данными.
Рассмотренные примеры построения корпоративных Big Data систем и конвейеров на базе Apache Kafka в очередной раз показывают универсальность и надежность этой стриминговой платформы обработки больших данных. Однако, иногда этого недостаточно в ML-системах, построенных в соответствии с микросервисной архитектурой. О проблемах микросервисов в системах Machine Learning читайте в нашей новой статье. А трудности администрирования Kafka-топиков мы разбираем здесь.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
8 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Освоить администрирование, разработку и эксплуатацию Kafka для потоковой аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://www.confluent.io/blog/apache-kafka-vs-enterprise-service-bus-esb-friends-enemies-or-frenemies/
- https://habr.com/ru/company/vtb/blog/524454/
- https://medium.com/leboncoin-engineering-blog/from-a-legacy-relational-db-to-an-event-queue-b4ff5891cfee
- https://blog.twitter.com/engineering/en_us/topics/infrastructure/2020/deleting-data-distributed-throughout-your-microservices-architecture/

