В этой статье мы рассмотрим комплексный конвейер (pipeline) обработки больших данных с помощью алгоритмов машинного обучения (Machine Learning) для системы речевого анализа Callinter от китайской компании Fano Labs. Apache Kafka играет ключевую роль в этом аналитическом конвейере, ежедневно обеспечивая бесперебойную стабильность и высокую производительность интеллектуальной обработки нескольких тысяч часов звонков. Читайте далее, как Apache Kafka повысила эффективность NLP-системы для колл-центров.
Постановка задачи
Китайская компания Fano Labs, базирующаяся в Гонконге, разработала собственную интеллектуальную систему анализа речи Callinter для автоматизации работы банковских, страховых, телекоммуникационных и прочих отраслевых колл-центров. Она предназначена для повышения качества сервиса и обнаружение инцидентов с помощью технологий распознавания смысла произносимых слов и эмоций на базе алгоритмов Machine Learning. В частности, анализируя миллионы вызовов ежедневно, система позволяет бизнесу определять потенциальные риски и возможности своего клиентского сервиса [1].
При такой интенсивной обработке множества телефонных переговоров каждый день огромное значение имеют производительность и стабильность аналитического конвейера, который представляет собой серию процессов из нескольких микросервисов, таких как распознавание речи, извлечение намерений, обнаружение ключевых слов, определение настроений, проверка соответствия бизнесу, оценка и пр. Интенсивную работу аналитического конвейера системы Callinter наглядно демонстрируют следующие показатели [2]:
- обработка до 10 000 вызовов в день, т.е. около 7 вызовов в минуту;
- средняя продолжительность каждого звонка 5-10 минут;
- соотношение продолжительности вызова и времени, необходимого для распознавания речи, составляет примерно 1:2. Это означает, что на каждую минуту разговора требуется 2 минуты времени аналитической обработки на каждое ядро ЦП.
Изначально система была построена по последовательному принципу, когда каждый шаг процесса выполнялся синхронно. Однако по мере развития сервиса увеличения количества аналитических запросов привело к критической проблеме, которая заключается в том, что потребление памяти пропорционально количеству задач, выполняемых на каждом шаге. Таким образом, обработка осуществляется слишком долго и занимает много памяти. Кроме того, рабочая нагрузка меняется в течение суток, например, обычно пик приходится на полночь, что приводит к перегрузке системы.
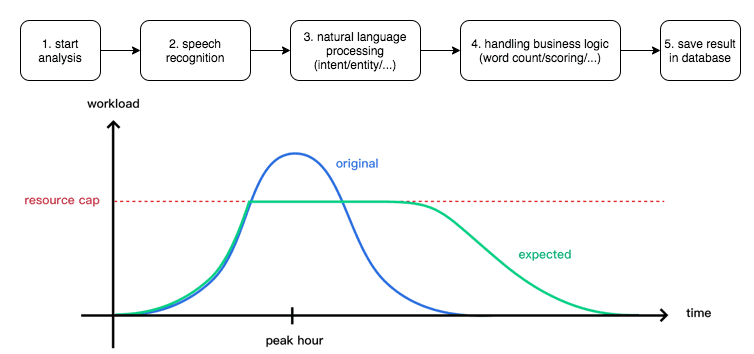
Один из способов решения этой проблемы – увеличить количество worker’ов сервиса распознавания в часы пик. Однако это невозможно в условиях ограниченных ресурсов. Поэтому Big Data специалисты компании Fano Labs приняли решение ставить задачи в очередь и обработки их с помощью брокера сообщений. Таким образом, worker может «вытягивать» задачу из брокера в зависимости от своей рабочей нагрузки, выравнивая общую загрузку всей системы. В качестве брокера сообщений была выбрана стриминговая платформа Apache Kafka. Напомним, Кафка предоставляет возможность анализа данных с помощью механизма структурированных запросов KSQL, библиотеку разработки распределенных приложений Kafka Streams и еще ряд специфических преимуществ по сравнению с другим популярным message broker, Rabbit MQ [2]. Чем отличается Apache Kafka от Rabbit MQ, мы подробно рассматривали здесь.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
8 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Apache Kafka как брокер сообщений для аналитического конвейера ML-системы речевой аналитики
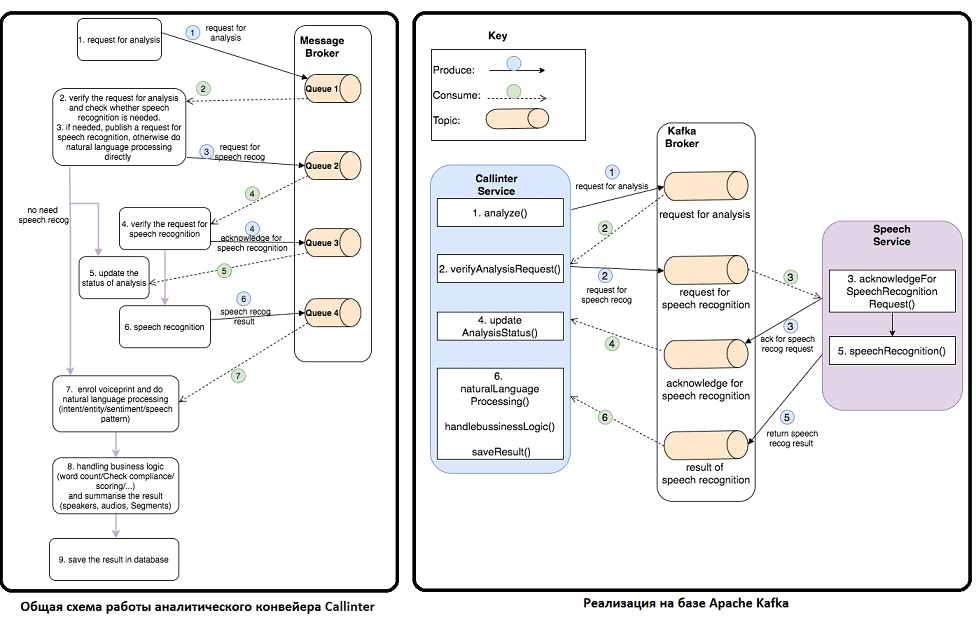
Сперва рассмотрим общий принцип работы аналитического конвейера для ML-системы речевой аналитики с брокером сообщений. Он действует как посредник обмена данными между сервисами, которые могут передаваться через стандартизированный протокол обмена сообщениями. Это позволяет маршрутизировать сообщения и доставлять их в соответствующее место назначения. Чтобы гарантировать доставку данных, очередь сообщений (Queue) часто используется для хранения и упорядочивания сообщений до тех пор, пока целевой сервис (потребитель, consumer) не сможет их использовать. Как правило, здесь реализуется архитектурная модель «Издатель-подписчик» (Publish-Subscribe), когда производитель публикует сообщение в топике, откуда его получают все потребители, подписанные на данный топик. Таким образом, рассматриваемый ML-pipeline будет работать по следующему принципу [2]:
- Запрос на аналитику публикуется в Очередь 1;
- Сообщения с действительным запросом на распознавание речи извлекаются из Очереди 1. Если распознавание не требуется, этот шаг пропускается, т.к. далее можно использовать предыдущий результат, сохраненный в базе данных.
- При необходимости распознавания речи, сервис публикует запрос на это действие в Очередь 2.
- Сообщение извлекается из Очереди 2, после получения которого сервис публикует подтверждение об этом в Очереди 3.
- Сообщение извлекается из Очереди 3, попутно обновляя статус в конвейере аналитики.
- По завершении распознавания речи сервис публикует результат в Очереди 4.
- Получив сообщение из Очереди 4, соответствующий сервис зарегистрирует его и выполнит обработку естественного языка (Natural Language Processing, NLP), включая определение намерения, смысла и настроения распознанной речи.
- После завершения NLP сервис будет обрабатывать бизнес-логику, такую как подсчет слов, проверка соответствия и оценка, а затем суммировать результат.
- Наконец, результат сохраняется в базе данных.
Администрирование кластера Kafka
Код курса
KAFKA
Ближайшая дата курса
2 июля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Вышеизложенная последовательность реализуется на Apache Kafka следующим образом [2]:
- Сервис системы Callinter (Callinter Service) выдает сообщение для речевой аналитики;
- Если запрос действителен, сервис выдаст сообщение для распознавания речи;
- Сервис речевой аналитики (Speech Service) принимает запрос на распознавание речи и выдает сообщение о подтверждении этого распознавания;
- Callinter Service считывает подтверждение распознавания речи, обновляя статус аналитики (AnalysisStatus).
- Когда сервис распознавания речи завершает его, он создает сообщение с результатами этого действия.
- Callinter Service однократно считывает результат распознавания, продолжая обработку естественного языка и выполнение бизнес-логики. Наконец, Callinter Service сохраняет результат в базе данных.
Практические результаты использования системы Machine Learning с NLP-технологиями
Успешность описанного решения на базе Apache Kafka и самой ML-системы речевой аналитики Callinter в целом подтверждает его внедрение в одной из крупнейших телекоммуникационных компаний Китая. В ее колл-центре работает более 300 агентов по обслуживанию клиентов, обслуживая около 9 миллионов абонентов. Система речевой аналитики Callinter на основе NLP-технологий машинного обучения и технологий Big Data была запущена в течение 4 месяцев, охватив 5 бизнес-единиц, 300 агентов и 14 000 взаимодействий с клиентами в день. Решение значительно повысило эффективность работы колл-центра обслуживания клиентов, показав следующие результаты [3]:
- повышение уровня автоматизации бизнес-процессов на 37% за счет интеллектуальной обработки клиентских запросов с помощью NLP-технологии;
- снижение нагрузки на агентов клиентского сервиса (сотрудников колл-центра);
- повышение качества обслуживания благодаря автоматическому анализу смысла и настроения речи при общении с клиентом;
- снижение продолжительности звонка на 21%;
- генерация новых бизнес-идей, включая продажи абонентам дополнительных услуг и продуктов в зависимости от их потребностей.
NLP с Python
Код курса
PNLP
Ближайшая дата курса
в любое время
Продолжительность
40 ак.часов
Стоимость обучения
90 000
В следующей статье мы продолжим разговор про аналитические pipeline’ы на базе Apache Kafka и рассмотрим проблему удаления данных в микросервисной архитектуре. А получить практические навыки по разработке NLP-приложений, а также освоить администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники