 653
653 
Содержание
Продолжая разговор про конвейеры обработки больших данных, сегодня рассмотрим пример использования Apache AirFlow в агрегаторе аренды частного жилья Airbnb. Читайте далее, в чем коварство накладных расходов при росте ETL-операций и других data pipeline’ов по запуску и выполнению заданий Spark, Hadoop и прочих технологий Big Data. Еще в этой статье разберем, от чего зависят накладные расходы, а также что такое глубина и ширина DAG.
Почему «тормозит» AirFlow: поиск причин
По мере развития бизнеса на базе больших данных (Big Data) конвейеры их обработки (data pipeline) тоже эволюционируют, становясь объемнее и сложнее. Поэтому компании стремятся «распилить» свои монолиты на множество функционально-доменных микросервисов, реализуя логику оркестровки и запуска задач MapReduce в коде, а не в необработанных запросах. Таким образом, система превращается в набор четко определенных шагов, структурированных в виде графа зависимостей. Однако, удобство автоматизированной оркестрации имеет свою цену: накладные расходы, к которым относятся операции ввода-вывода, ожидание выделения ресурсов для работы, ожидание запуска задачи по расписанию и т.д. Коварство накладных расходов в том, что они растут медленно, но постоянно, вместе с data pipeline’ом и превращаются в проблему, когда нужно управлять десятками задач. Поскольку при этом уже существует множество различных переменных, которые влияют на производительность конвейера, мониторинг и изоляция источников накладных расходов становятся сложными, особенно если конвейер тратит много времени на вычисления [1]. Поясним, что здесь и далее в этой статье под накладными расходами понимаются не денежные инвестиции, а время, затрачиваемое не на выполнение вычислений, полезных для бизнеса, а на вспомогательные операции.
В 2018 году задача снижения накладных расходов стала особенно актуальной для компании Airbnb, самой популярной онлайн-площадке для размещения, поиска и краткосрочной аренды частного жилья по всему миру с миллионами пользователей и собственной платежной системой [2]. Изначально конвейер Spark-заданий в рамках сервиса Payments запускался один раз в день, чтобы было достаточно для выполнения SLA по доставке и управления риском проблем с целостностью данных, возникающих в течение следующих суток. Но, мере популяризации площадки и спроса на краткосрочную аренду у частных путешественников, такая периодичность обработки данных перестала отвечать бизнес-потребностям. Поэтому возникла задача ежечасного запуска data pipeline’ов. При этом инженеров Big Data в Airbnb ограничивало текущая архитектура организации конвейеров и логика их оркестрации, которые делали невозможной реализацию почасовых конвейеров с контролем накладных расходов.
Сама Big Data платформа в Airbnb основана на Spark и Hive, а главный конвейер в основном реализован на Scala. YARN используется для планирования заданий и управления ресурсами, а выполнение заданий происходит в Amazon EMR. В качестве средства оркестрации задач выступает Apache Airflow, который заботится о логике выполнения задач, их запуске, конфигурации исполнителей заданий Spark и т.д. Всего в конвейерах Airbnb более тысячи задач. Например, конвейеров интеграционных тестов для сервиса Payments принимает события, генерируемые модульными тестами, и запускает их через весь конвейер для обнаружения проблем в новом коде, прежде чем он будет объединен с основной ветвью. При этом важно, что интеграционные тесты обрабатывают объем данных порядка нескольких сотен записей за запуск. Это на несколько порядков меньше, чем обрабатывает почасовой конвейер в производственной среде (production). Тем не менее, из-за высоких накладных расходов производительность production-конвейера приближалась к pipeline’у интеграционного тестирования: теоретически он должен работать около 15 минут, но на практике это время составляло примерно 2 часа. Корректировка конфигурации Spark для учета меньшей нагрузки не дала почти никакого эффекта. При дальнейшем исследовании дата-инженеры Airbnb обнаружили, что время, затрачиваемое на выполнение ETL-операций или любых Spark-вычислений, было близко к 0. Очевидно, конвейер тратил время на какие-то другие действия, что нужно было определить и исключить [1].
Где скрываются накладные расходы data pipeline’а: 5 главных «пожирателя времени»
Проведя комплексный анализ своих production-конвейеров, инженеры Big Data в компании Airbnb пришли к выводам, что источниками накладных расходов могут быть следующие факторы [1]:
- задержка планировщика – поскольку любой сложный конвейер данных имеет некоторую систему (crontab, Airflow, очередь задач и т.д.), которая управляет зависимостями и планированием заданий, то между завершением одного задания и запуском следующего присутствует некоторая задержка.
- задержка перед выполнением – даже когда задание запланировано, перед тем как работа будет запущена, нужно выполнить некоторую подготовительную работу. Например, отправка JAR-файла на машину, которая выполняет задачу, проверка работоспособности, гарантирующая, что данные из предыдущих задач были доставлены, инициализация кода приложения, загрузка конфигурации или зависимостей системной библиотеки и пр.
- создание экземпляра сеанса Spark и выделение ресурсов – поскольку сеансы Spark требуют времени для настройки, то чем чаще происходит его запуск и остановка, тем больше требуется времени. Кроме того, работа (job) должна получить все необходимые ресурсы из кластера. Это актуально даже при том, что некоторые функции Spark, такие как динамическое размещение, немного сокращают этот процесс. И хотя, в случае использования кластера с автомасштабированием, такого как Amazon EMR, возможен доступ к большому пулу ресурсов, для их назначения конкретному кластеру также требуется значительное время.
- сохранение и загрузка данных: в сложном конвейере часто есть промежуточные результаты, которые необходимо сохранить для их использования другими pipeline’ами или заданиями. Часто бывает полезно разбить конвейер на отдельные этапы, чтобы управлять логической сложностью и ограничить влияние сбоев в заданиях на выполнение конвейера.
- размер и сложность самого конвейера обработки данных – наконец, масштаб самого pipeline’а влияет на накладные расходы при его эксплуатации. Отношения между зависимыми задачами в конвейерах данных обычно структурируются как направленный ациклический граф (DAG, Directed Acyclic Graph), форму и размер которого можно измерить глубиной и шириной. Глубина показывает – количество связей между задачей и ближайшим к ней пограничным узлом. Ширина – это количество узлов с заданной глубиной. Обычно накладные расходы увеличиваются с глубиной графа, особенно в его линейных сегментах, где задачи выполняются последовательно. Ширина DAG’а также провоцирует рост накладных расходов, например, в случае времени, которое уходит на сохранение и загрузку записей из распределенной файловой системы Apache Hadoop (HDFS). Кроме того, операции ввода-вывода данных тоже имеют свои фиксированные накладные расходы, поэтому, хотя время посадки отдельных задач может не измениться, общая длительность вычислений увеличится.
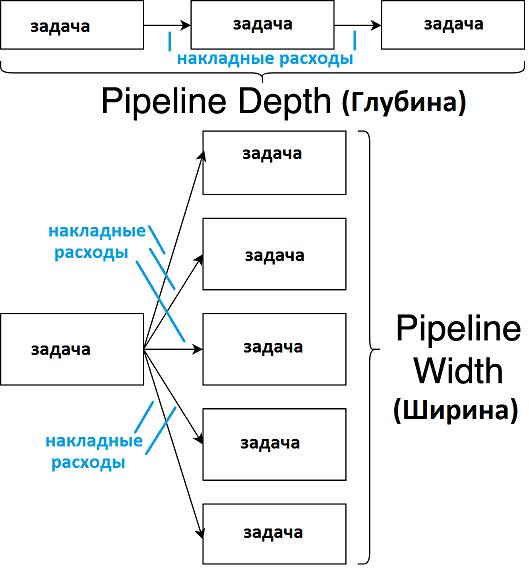
Из всех перечисленных источников накладных расходов, именно структура конвейера является наиболее управляемым фактором. В частности, пользовательский интерфейс Apache Airflow наглядно показывает структуру DAG, позволяя определить его ширину и глубину. Поэтому Big Data инженеры Airbnb решили изменить масштаб и сложность корпоративных pipeline’ов, отделив в них бизнес-логику от логики оркестровки [1]. Как именно это было сделано, мы рассмотрим завтра. А про повышение эффективности облачных AirFlow-сервисов с помощью Amazon RDS Proxy читайте в нашей новой статье.
Больше подробностей по администрированию и эксплуатации Apache Airflow в production на реальных проектах цифровизации частного бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

